
Flink CDC这种分库分表同步场景下源表和目标表主键不一致的情况cdc 3.0 pipeline也不支持吗?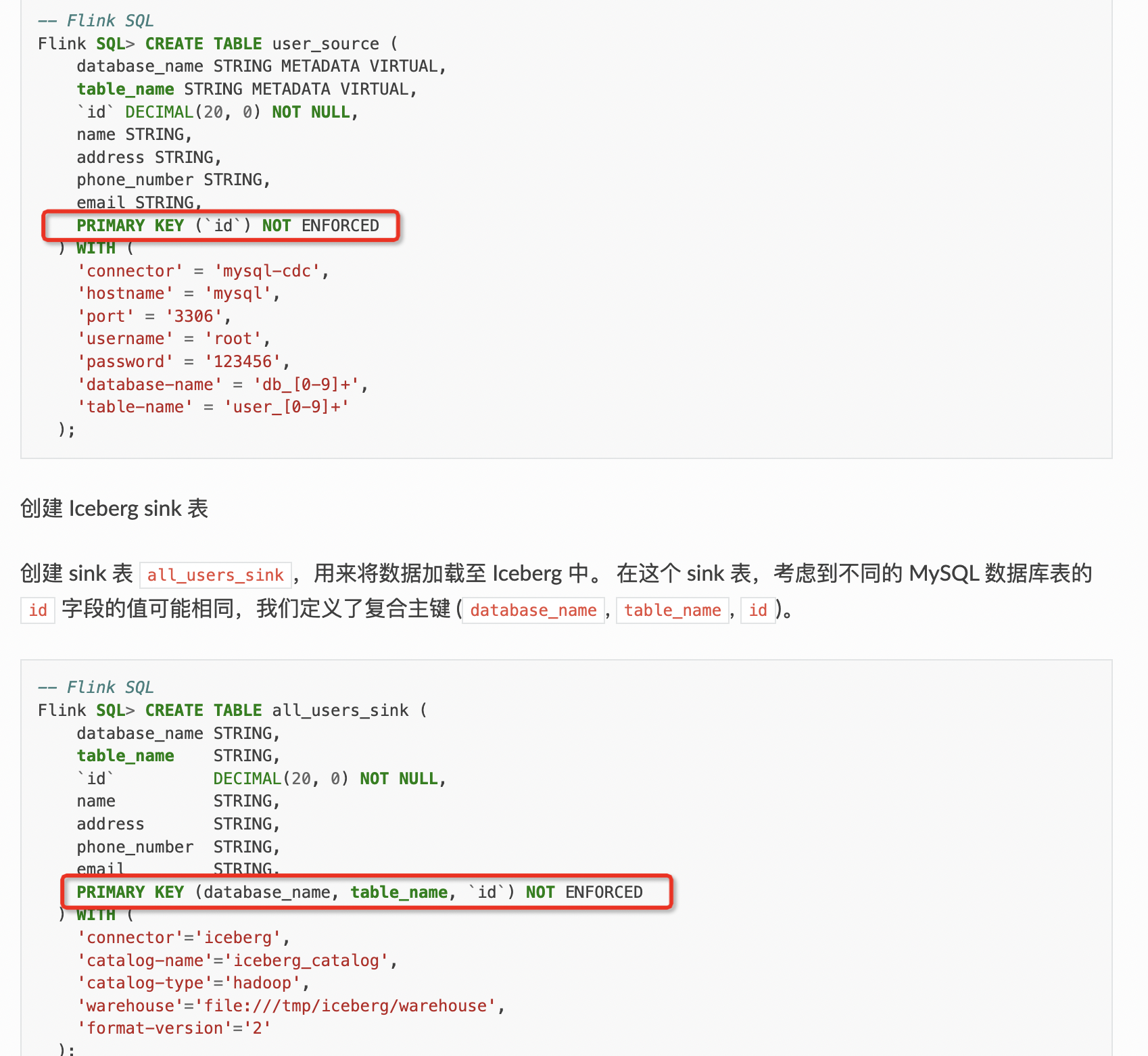
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC的分库分表同步场景下,如果源表和目标表的主键不一致,目前CDC 3.0 pipeline确实不支持这种场景。以下是详细分析和相关说明:
在分库分表合并同步的场景中,Flink CDC会将多张分库分表的数据合并到一张目标表中。为了保证数据的唯一性,通常会将库名、表名和原主键组合成一个新的联合主键。
- 如果目标表的主键与源表主键不一致(例如目标表使用了不同的字段作为主键),Flink CDC无法自动处理这种映射关系。 - 这种限制主要源于Flink CDC的设计原则:它依赖于源表的Schema信息来推导目标表的Schema,而主键是Schema的重要组成部分。
根据知识库中的描述,CDC 3.0 pipeline在处理Schema变更时,支持多种模式(如LENIENT、EVOLVE等)来适配目标端的Schema变更需求。然而: - 主键字段的变更或不一致属于较为复杂的Schema变更类型,CDC 3.0 pipeline并未提供直接支持。 - 如果目标表的主键与源表主键不一致,可能会导致以下问题: - 数据写入失败。 - 主键冲突或数据重复。 - 同步作业报错并停止运行。
针对源表和目标表主键不一致的情况,可以考虑以下解决方案:
ADD COLUMN功能添加计算列,生成新的主键字段。例如:
CREATE TABLE IF NOT EXISTS target_table
WITH ('jdbcWriteBatchSize' = '1024')
AS TABLE source_catalog.db_name.table_name
ADD COLUMN (
new_pk AS CONCAT(database_name, '_', table_name, '_', id) -- 新主键字段
);
transform模块,对流经Flink管道的数据进行ETL处理,生成符合目标表主键要求的字段。例如:
transform:
- columns:
new_pk: CONCAT(database_name, '_', table_name, '_', id)
IGNORE模式处理主键冲突。例如:
pipeline:
schema.change.behavior: IGNORE
综上所述,Flink CDC 3.0 pipeline在分库分表同步场景下确实不支持源表和目标表主键不一致的情况。建议通过手动调整目标表主键、使用Transform模块或配置Schema变更行为来解决该问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

