
Flink CDC还是会有sid冲突的情况 会是因为我整库表太多了? 他是一个整库任务一个sid还是多个 我看他启动日志里面刷了很多的sid ?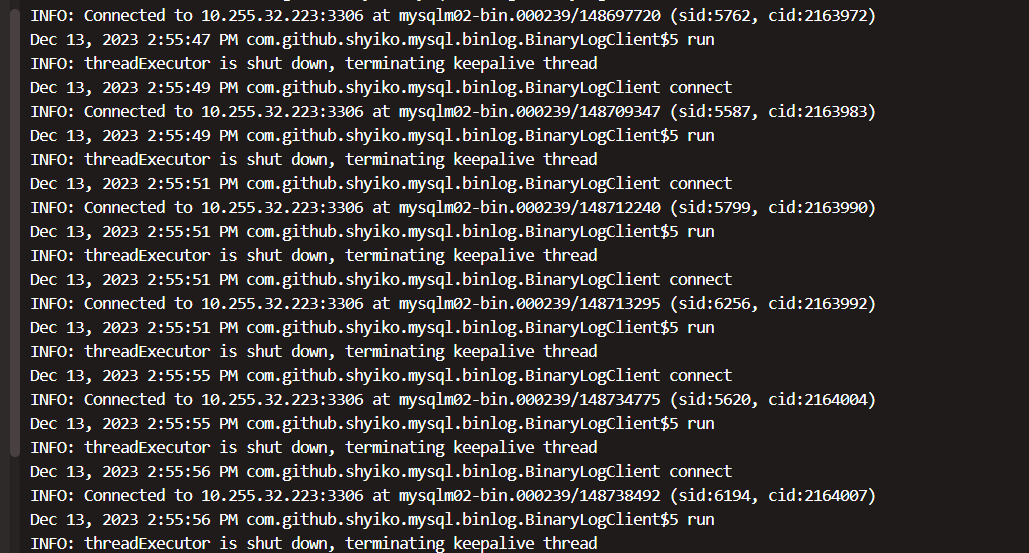
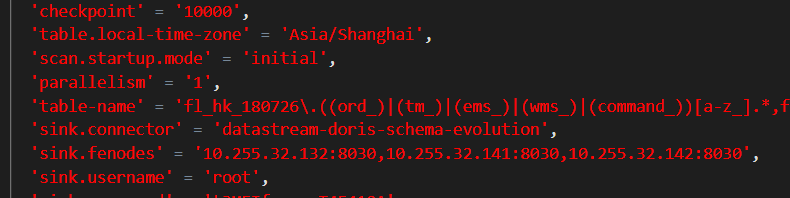
我运行一个任务 他会刷出来很多server-id 会有这三个 但是还会有别的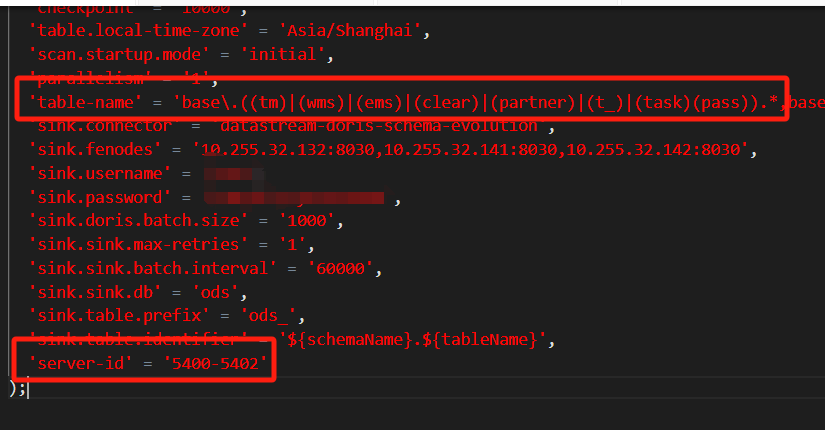
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC进行整库同步时,出现多个server-id的情况是正常的,但这可能会导致server-id冲突的问题。以下是详细的原因分析和解决方案:
server-id?整库同步的实现机制
Flink CDC在整库同步时,会为每个需要读取的表启动一个独立的Binlog Client连接。每个Binlog Client都需要一个唯一的server-id来标识自己,因此在日志中会看到多个server-id被分配。
动态生成server-id
如果未显式配置server-id,Flink CDC会自动为每个表生成一个随机的server-id。这可能导致在同一个任务中生成大量不同的server-id,尤其是在整库同步涉及大量表的情况下。
Source复用的影响
在Flink计算引擎VVR 8.0.7及以上版本中,支持MySQL CDC Source复用功能。如果启用了Source复用(通过SET 'table.optimizer.source-merge.enabled' = 'true';),Flink会尝试合并多个CDC源表的连接,从而减少server-id的数量。但如果未启用或无法完全合并,仍然会生成多个server-id。
server-id冲突的原因MySQL实例限制
MySQL要求每个连接到Binlog的客户端必须具有唯一的server-id。如果多个Flink CDC任务或同一个任务中的不同表使用了相同的server-id,会导致冲突,进而引发连接失败或数据读取异常。
整库表数量过多
当整库同步涉及大量表时,如果没有合理配置server-id,可能会因为自动生成的server-id范围不足而导致冲突。
server-id为了避免server-id冲突,建议为每个MySQL CDC源表显式配置server-id,并确保其唯一性。例如:
CREATE TABLE mysql_source (...) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'your-mysql-host',
'port' = '3306',
'username' = 'your-username',
'password' = 'your-password',
'database-name' = 'your-database',
'table-name' = 'your-table',
'server-id' = '1001-2000' -- 配置一个范围,避免冲突
);
server-id范围(如1001-2000),可以让Flink CDC在该范围内动态分配server-id,从而避免冲突。server-id范围不重叠。如果您的Flink版本支持Source复用(VVR 8.0.7及以上),可以通过以下方式减少server-id的数量:
SET 'table.optimizer.source-merge.enabled' = 'true';
server-id的分配数量。server-id外)完全相同时,才能进行合并。server-id范围MySQL实例对server-id的范围有一定的限制,默认范围为1-4294967295。如果您的Flink CDC任务使用的server-id超出了MySQL实例的允许范围,也会导致冲突。可以通过以下命令检查MySQL的server-id配置:
SHOW VARIABLES LIKE 'server_id';
如果需要调整范围,可以在MySQL配置文件中修改server-id相关参数。
如果整库表数量过多,可以考虑将数据同步任务拆分为多个子任务,分别处理不同的库或表。例如,使用正则表达式匹配部分表进行同步:
'table-name' = 'user_.*' -- 只同步以"user_"开头的表
启用Source复用的注意事项
在开启Source复用后,不建议将作业配置项pipeline.operator-chaining设为false,因为断开算子链会增加序列化和反序列化的开销,尤其是在合并的Source较多时。
升级Flink版本
如果您使用的是较旧版本的Flink,建议升级到VVR 8.0.1及以上版本,以获得更好的性能和稳定性。
监控server-id分配情况
在任务启动日志中,关注server-id的分配情况,确保没有重复或超出范围的server-id。
通过以上方法,您可以有效解决Flink CDC任务中server-id冲突的问题,并优化整库同步的性能和稳定性。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

