
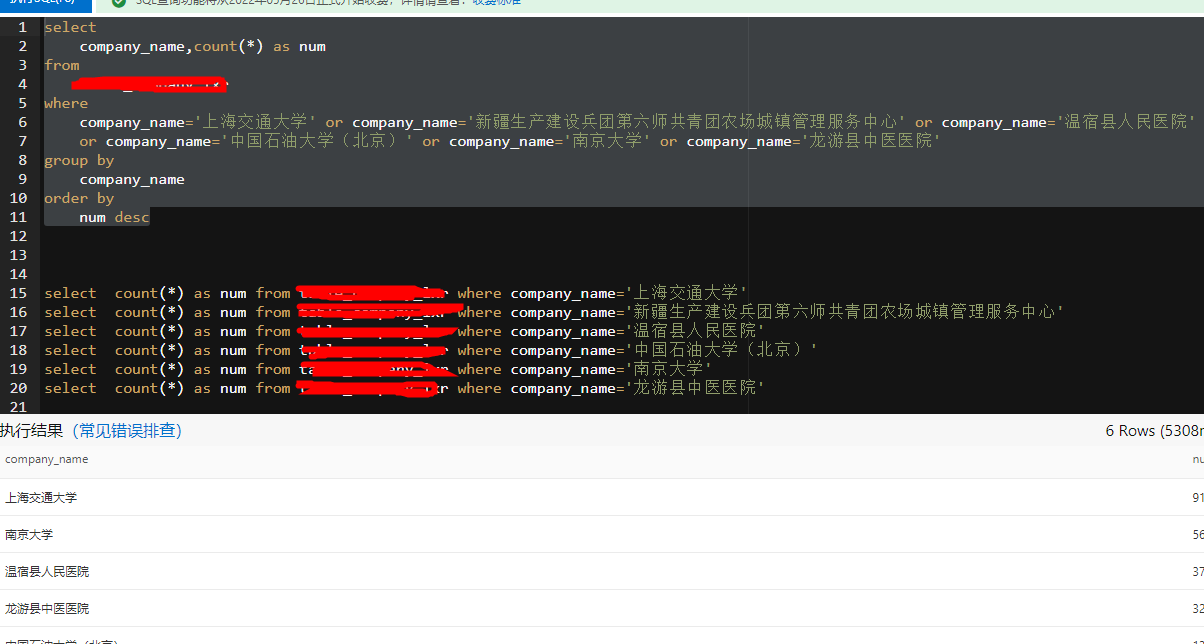
 表格储存查这样一个分组查询 5秒多见最快的时候224毫秒单独查一个公司1秒以内有什么方式能快点吗?
表格储存查这样一个分组查询 5秒多见最快的时候224毫秒单独查一个公司1秒以内有什么方式能快点吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要优化表格存储的分组查询性能,您可以从以下几个方面入手,结合知识库中的信息进行调整和优化:
GROUP BY)或聚合(如COUNT、SUM等),建议为相关字段创建多元索引。SELECT明确指定需要的字段,减少数据传输量。LIMIT限制返回的结果数量,避免不必要的数据处理。SELECT company, COUNT(*) AS count
FROM test_table
WHERE company = '目标公司'
GROUP BY company
LIMIT 100;
这种方式可以显著减少查询时间和资源消耗。
enableRequestCompression和enableResponseCompression为true,可以减少网络传输的数据量,从而提升查询速度。syncClientWaitFutureTimeoutInMillis或setQueryTimeout来避免因超时导致的失败。例如:
statement.setQueryTimeout(60); // 设置超时时间为60秒
LIMIT和OFFSET分批获取数据,避免一次性加载过多数据。EXPLAIN)来识别性能瓶颈。例如:
EXPLAIN SELECT company, COUNT(*) AS count
FROM test_table
GROUP BY company;
根据查询计划的输出,优化索引设计或调整查询逻辑。
WHERE子句)缩小查询范围,减少扫描的数据量。__time__字段明确指定时间范围,避免扫描无关数据。通过以上方法,您可以有效提升表格存储分组查询的性能。如果问题仍然存在,建议联系阿里云技术支持团队,提供具体的查询语句和场景,以便进一步诊断和优化。
