
CSANMT我想使用本地的数据集,数据集的格式是不是两个文件,例如训练集有两个txt文件,一个en,一个zh,文件里面的内容就是一句话或者一个词?这是我数据集的格式: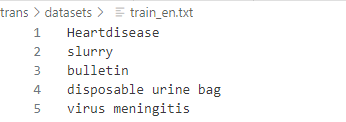
但是我使用下面的代码时报错了: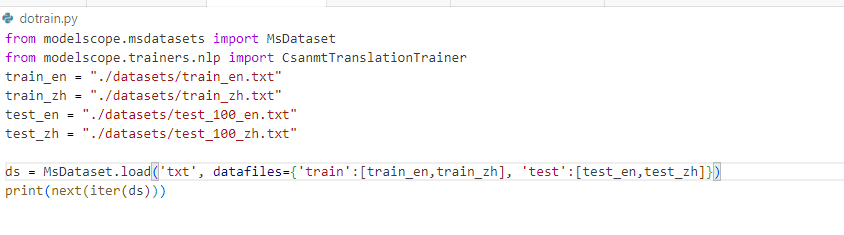
这是我的报错信息,请您指导我一下: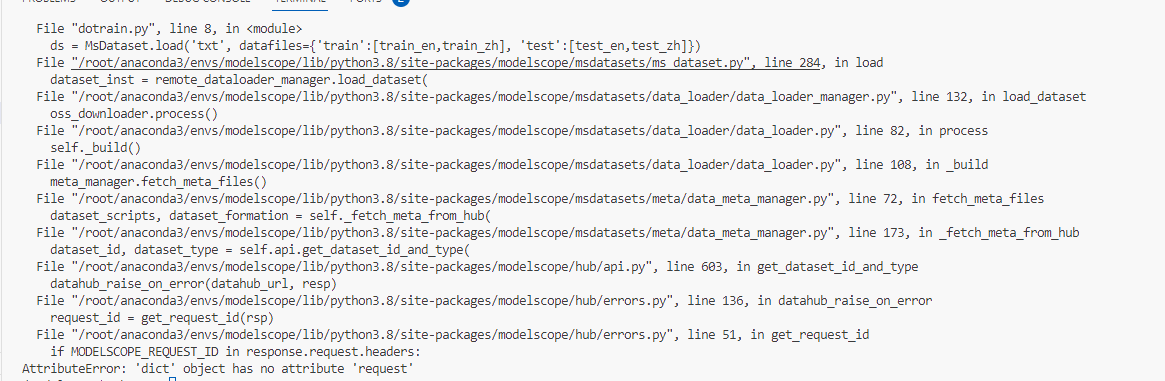
它上面不是说的两个文件,每一行一一对应啊。。。
在ModelScope中,文件里面的内容并非一句话或者一个词。更准确地说,ModelScope是阿里达摩院推出的一个开源模型共享平台,包括计算机视觉、多模态、自然语言处理等多个领域的预训练模型。这些模型是由网络结构和相应参数组成的具体模型实例。用户可以通过ModelScope Library,使用特定的方法,完成模型的推理、训练和评估等任务。同时,ModelScope Hub作为社区成员可以托管模型的地方,提供了模型的存储、版本管理和相关操作
看起来你的数据集格式可能不符合预期的格式。根据你提供的信息,你的数据集似乎是一个包含多个图片文件的文件夹,而不是一个文本文件,其中每一行都包含一对英语和中文句子。
对于CSANMT模型,你需要提供一个文本文件作为数据集,其中每一行都包含一对英语和中文句子。这些句子应该是分开的,一行只包含一个句子对。例如:
This is a cat. 这是一只猫。
This is a dog. 这是一只狗。
如果你的数据集是图片形式的,你可能需要使用其他的方法来处理,例如使用OCR技术来识别图片中的文字,然后将这些文字转换成文本数据。
模型卡片上数据集加载和您这里的不同,https://www.modelscope.cn/models/damo/nlp_csanmt_translation_en2zh/summary 修改Configuration.json相关训练配置,根据用户定制数据进行微调。。此回答整理自钉钉群:魔搭ModelScope开发者联盟群 ①

