
这里两个不同版本的FLink 中如果设置了jdbc_fixed模式都会去重吗?如果去重 是按照什么条件规则去重呢?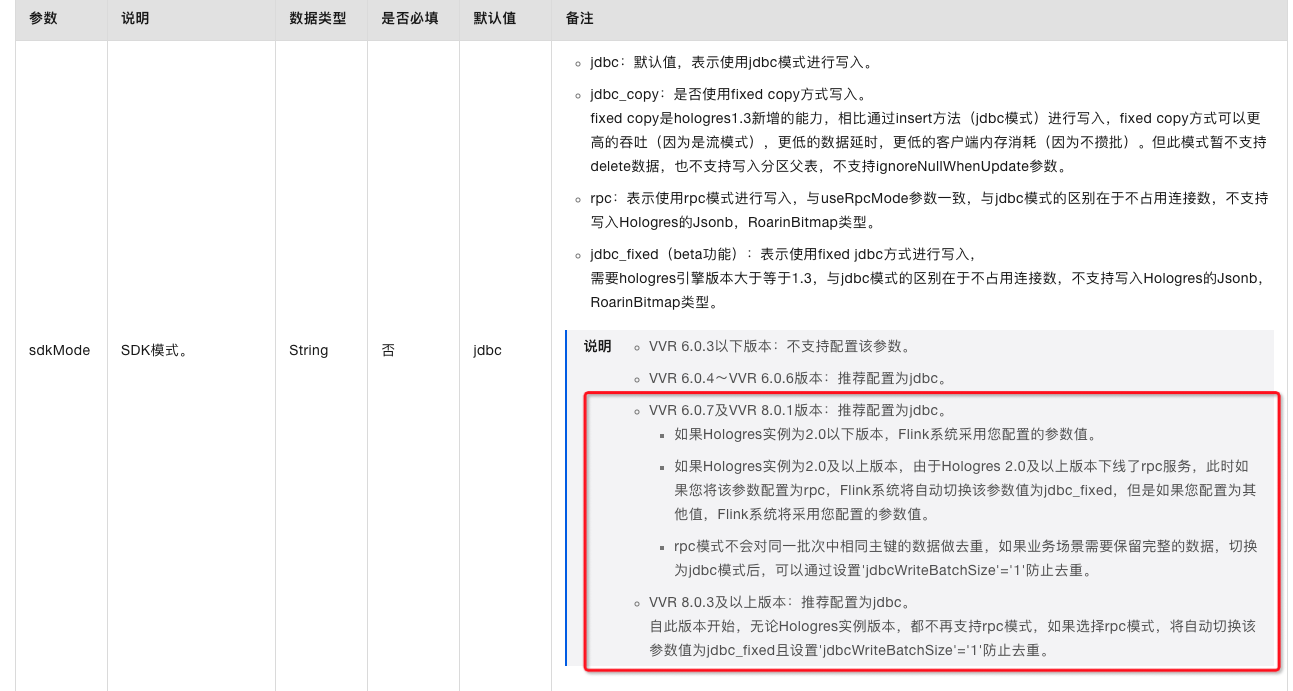
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink中,是否进行去重操作与是否设置jdbc_fixed模式并无直接关系。jdbc_fixed模式只是Flink的一种数据源连接模式。而关于去重,这通常涉及到具体的数据处理逻辑。在大数据处理过程中,例如统计每日每个类目下的用户的订单信息,就需要按类目分组,然后对数据进行去重。
至于具体的去重规则,这取决于实际的业务需求和数据处理逻辑。常见的去重方案包括MapState方式去重、SQL方式去重、HyperLogLog方式去重以及Bitmap精确去重等。例如,通过使用HyperLogLog算法,Flink可以高效地实现对大规模数据的去重。此外,还可以根据业务需求,采用Bitmap精确去重等不同的策略。因此,如果您希望在Flink中实现去重操作,需要根据您的具体业务场景和需求来选择合适的去重方案。
在两个不同版本的 Flink 中,如果设置了 jdbc_fixed 模式,并不一定会进行去重操作。jdbc_fixed 模式是 Flink 的一种数据源连接模式,它假定数据源的数据是可靠的,因此在读取数据时不会进行去重操作。
然而,具体的去重规则取决于您在 Flink 作业中的实现和配置。如果您的 Flink 作业需要进行去重操作,您可以在数据流的处理逻辑中实现去重逻辑,例如使用 distinct 操作符或自定义的去重函数。
在 Flink 中,去重操作可以根据不同的条件规则进行。例如,您可以使用 distinct 操作符对数据进行去重,它根据数据的唯一性进行去重操作。您还可以使用其他聚合函数,如 count、sum 等,对数据进行聚合计算,以实现更复杂的去重逻辑。
对于不同版本的 Flink SQL,JDBC 模式是否支持去重是不确定的,具体取决于您使用的版本和功能。在某些版本中,JDBC 模式支持精确去重,而在某些版本中则不支持。
在支持精确去重的情况下,Flink SQL 会按照输入流中的记录数进行去重。换句话说,如果一条记录出现在多个输入流中,那么这条记录只会被处理一次。您可以使用 DISTINCT 关键字来实现精确去重。
①使用 jdbc_fixed 默认走去重②按照主键去重
非去重模式就是上游来一条请求一次写一条
去重就是,因为物理表主键相同的数据最终只需保留最新数据,所以在 Flink 引擎侧先做去重,减少对 DB 的请求,高效些。此回答整理自钉群“实时计算Flink产品交流群”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


