
请教一下ModelScope,微调mPLUG视觉问答模型-中文-base模型是,内存一直涨有人遇到过吗?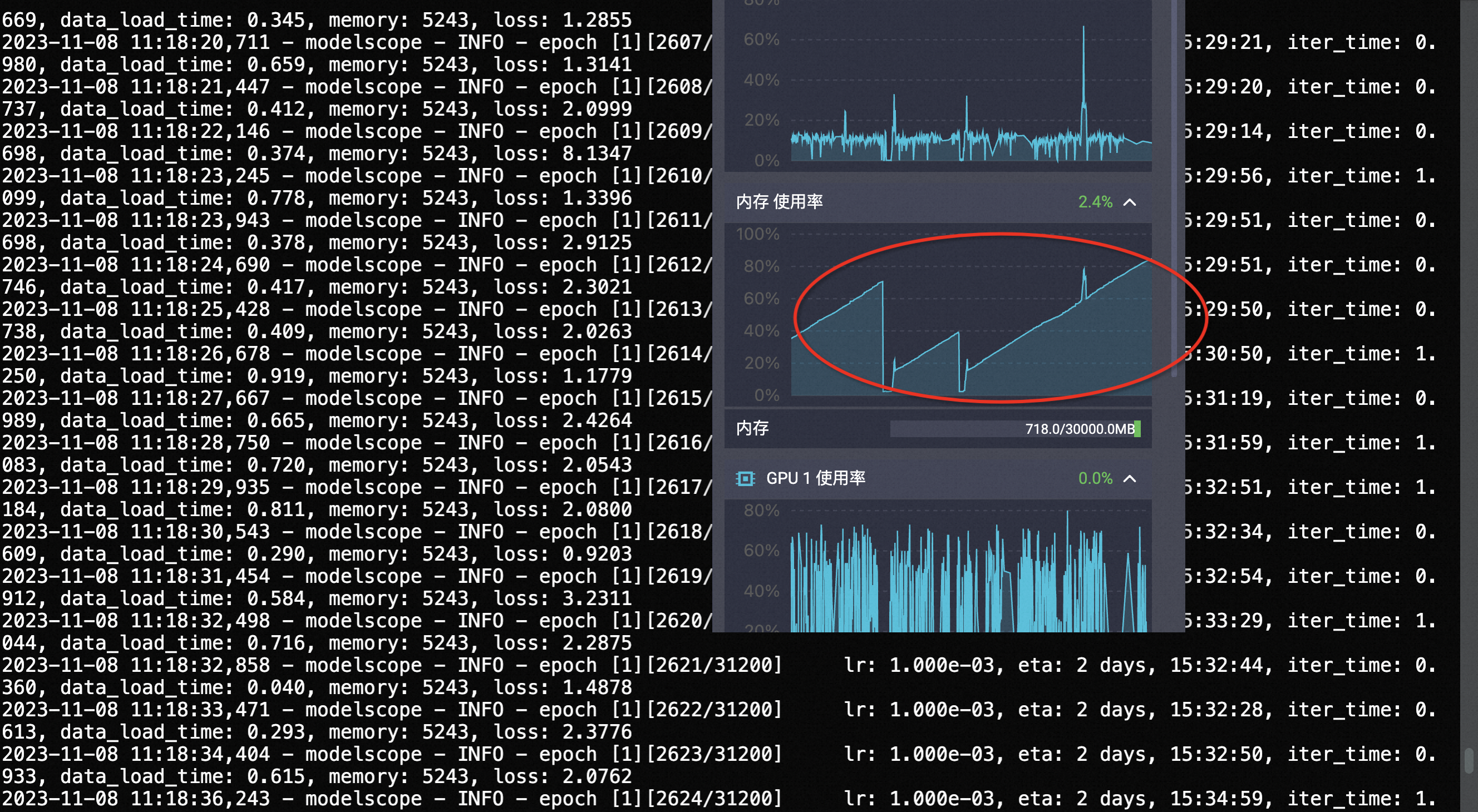
最终导致内存爆了
对于 ModelScope 中的 mPLUG 视觉问答模型(mPLUG Visual Question Answering Model),在微调过程中遇到内存占用不断增加的情况是可能的。这种情况通常是由于以下原因导致的:
批量处理和梯度累积: 在微调过程中,经常使用批量梯度下降来更新模型参数。如果您设置了较大的批量大小,并且使用了梯度累积技术(accumulated gradient),则可能会导致内存占用不断增加。梯度累积会在每个批次之间保留梯度信息,从而导致内存占用量增加。
缓存数据和计算图: 在模型训练期间,为了进行反向传播和优化计算,PyTorch 会自动构建计算图并保存中间结果。这些结果会占用额外的内存,尤其是在长时间的训练过程中。此外,模型参数和梯度也会占用一定的内存空间。
模型复杂性和参数数量: 如果您使用的模型非常复杂或具有大量的参数,那么它可能需要更多的内存来存储权重、梯度和其他相关信息。
针对这些情况,您可以尝试以下方法来减轻内存压力:
torch.autograd.grad() 和 torch.Tensor.detach_() 等方法实现。在微调mPLUG视觉问答模型-中文-base的过程中,内存使用量可能会持续增加。这是因为mPLUG是一种基于skip-connections的高效跨模态融合框架,其模型庞大且复杂,因此在运行过程中需要大量的内存来存储和处理数据。特别是当模型运行时,大约会占用9GB的内存。
如果您的内存一直在涨,可能有几个原因:

