
Flink sql-client 针对kafka的protobuf格式数据建表,老是找不到pb类名,报java.lang.ClassNotFoundException 有人遇到过吗?求给点思路,不知道如何解决了?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,根据你的描述,可能是缺少依赖造成的,请确保你的项目中已经正确地引入了Protobuf相关的依赖,在Flink SQL Client中使用Protobuf格式的数据,需要使用Protobuf生成的Java类进行解析,你需要将生成的Java类打包并添加到Flink的依赖中,以便能够正确地加载和使用。
还有就是Classpath配置问题,请检查你的Flink SQL Client的运行环境,确保classpath配置正确,在运行时可以找到Protobuf生成的Java类。你可以先尝试在命令行中手动添加Protobuf生成的类所在的jar包或目录,并再次运行SQL Client。
如果你在使用 Flink SQL Client 针对 Kafka 的 Protobuf 格式数据建表时遇到了 java.lang.ClassNotFoundException,这通常意味着 Flink 在运行时找不到所需的类。以下是一些建议和可能的解决方案:
1、 确保 Protobuf 编译的类存在:
* 确保你已经正确地编译了 Protobuf 文件,并且生成的 Java 类文件存在于 Flink 可以访问的路径中。
* 如果你的 Protobuf 文件在 Kafka 中,确保它们被正确地读取并转换为了 Java 类。
2、 检查类路径:
* 确保 Flink 的类路径(Classpath)中包含了你的 Protobuf 生成的 Java 类。你可以通过添加这些类的 jar 包到 Flink 的 classpath 来解决这个问题。
3、 使用正确的版本:
* 确保 Flink 和 Kafka 以及它们的依赖库的版本是兼容的。有时候,不同版本的库之间可能存在不兼容性,导致某些类无法找到。
4、 检查 Flink SQL Client 的配置:
* 确保 Flink SQL Client 的配置是正确的,特别是与 Kafka 和 Protobuf 相关的配置。
5、 查看日志:
* 检查 Flink 的日志,可能会有更详细的错误信息或堆栈跟踪,这可以帮助你定位问题。
6、 更新或回退版本:
* 如果你使用的是较新的版本,考虑回退到一个稳定的版本,或者更新到最新版本,看看问题是否仍然存在。有时候,新版本中可能已经修复了这个问题。
java.lang.ClassNotFoundException是Java应用程序中常见的一种异常,它表示类加载器无法找到特定的类。
当类加载器试图动态地加载一个类,但无法在程序的classpath中找到该类的二进制表示时,就会抛出这个异常。
处理java.lang.ClassNotFoundException可以通过以下几种方法:
1、检查类的二进制名称:确保你在代码中引用的类名是正确的,并且大小写也要完全匹配。
2、校验Classpath:确保你的类存在于classpath路径下。如果不确定classpath路径,可以使用System.getProperty("java.class.path")来打印出当前的classpath路径。
3、检查库和JAR文件:如果你使用的类来自外部库或JAR文件,确保这些库和JAR文件已经被正确地添加到了项目的classpath中。
4、动态加载类:如果你在代码中使用了动态加载类的方法,比如Class.forName(),那么你需要确保指定的类确实存在。
——参考来源。
首先,使用protoc编译器将.proto文件编译成对应编程语言(如Java)的类文件,这样Flink作业可以通过这些生成的类来反序列化Kafka消息中的protobuf数据。
Apache Flink 是一个流处理和批处理的开源框架,而 Flink SQL 是 Flink 的一部分,允许用户使用 SQL 语言处理数据。至于你提到的 "protobuf" 格式,这是 Google Protocol Buffers 的缩写,它是一种数据交换格式,通常用于序列化结构化数据。
对于 Kafka 中的 protobuf 格式数据,你可以使用 Flink SQL 客户端来处理,但首先需要确保以下几点:
Kafka 主题格式:确保 Kafka 主题中的数据是 protobuf 格式。这意味着 Kafka 中的消息应该是 protobuf 序列化后的字节流。
Flink 版本和依赖:确保你使用的 Flink 版本支持处理 protobuf 数据。可能需要添加特定的依赖或插件来解析 protobuf 数据。
定义源表:使用 Flink SQL 客户端,你可以定义一个连接到 Kafka 的表。这通常涉及使用 Kafka 的 CREATE TABLE 语句,指定主题、键和分区等。
可参考官方文档 如何解决Flink依赖冲突问题
问题原因
作业JAR包中包含了不必要的依赖(例如基本配置、Flink、Hadoop和log4j依赖),造成依赖冲突从而引发各种问题。
作业需要的Connector对应的依赖未被打入JAR包中。
排查方法
查看作业pom.xml文件,判断是否存在不必要的依赖。
通过jar tf foo.jar命令查看作业JAR包内容,判断是否存在引发依赖冲突的内容。
通过mvn dependency:tree命令查看作业的依赖关系,判断是否存在冲突的依赖。
解决方案
基本配置建议将scope全部设置为provided,即不打入作业JAR包。
DataStream Java
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
DataStream Scala
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
DataSet Java
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
DataSet Scala
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
添加作业需要的Connector对应的依赖,并将scope全部设置为compile(默认的scope是compile),即打入作业JAR包中,以Kafka Connector为例,代码如下。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
其他Flink、Hadoop和log4j依赖不建议添加。但是:
如果作业本身存在基本配置或Connector相关的直接依赖,建议将scope设置为provided,示例如下。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<scope>provided</scope>
</dependency>
如果作业存在基本配置或Connector相关的间接依赖,建议通过exclusion将依赖去掉,示例如下。
<dependency>
<groupId>foo</groupId>
<artifactId>bar</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</exclusion>
</exclusions>
</dependency>
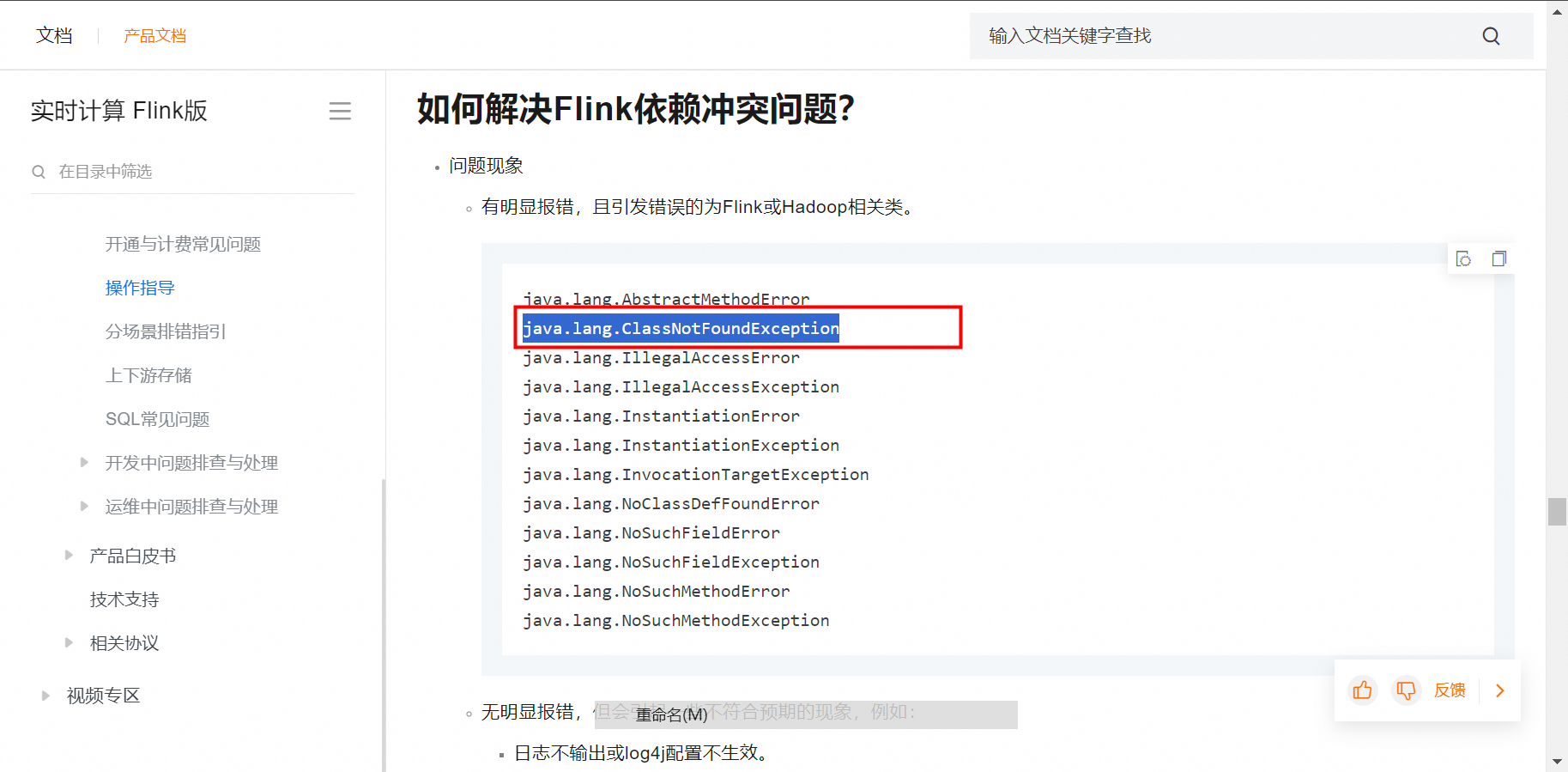
你正在尝试创建一个TableSink用于Kafka Protobuf数据流,但遇到了ClassNotFoundException,那很可能是Protobuf生成的Java类没有加载进来。以下有一些可能的解决方案
添加JAR到FLINK_CLASSPATH
确保protobuf相关的库已经被加入到Flink的classpath中。可以通过增加以下参数来实现这一点:
--conf org.apache.flink.client.program.PackagedProgram FLICKER=/path/to/flinker-classloader:/path/to/flink-jar:/path/to/flink-plugin-jar
这里的"/path/to/flink-class-loader"应该指向包含了protobuf jar的class path。
尝试手动导入protobuf Java API
有时候,即使将protobuf JAR添加到FLINK_CLASSPATH中也不足以让系统自动发现这些类。这时,您还可以尝试直接导入protobuf Java API。为此,您可以按照以下方式更新POM文件:
<!-- protobuf dependency for kafka connector -->
<dependency>
<groupId>io.github.resilience4j.cassandra</groupId>
<artifactId>cassandra-resilience4j-feature-pack</artifactId>
<version>${resilience4j.version}</version>
</dependency>
<!-- protobuf java api -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protoc-gen-java</artifactId>
<optional>true</optional>
</dependency>
更新protobuf插件
如果您使用的不是最新版的protobuf插件,则有可能会因为插件本身存在的bug而引起 ClassNotFoundException。建议升级至最新版本的protobuf插件,并重载Flink作业。
检查protobuf生成的Java类位置
确保protobuf生成的Java类存在于FLINK_CLASSPATH中。如果它们不在那里,您需要移动它们到该位置,或者设置适当的环境变量来告诉Flink查找它们的位置。
在Flink SQL Client中,使用Kafka作为数据源时,确实可以使用Protobuf格式。但是,在创建表时,您需要确保已经正确地定义了对应的Protobuf类,并且这些类是可以被Java识别的。
当您使用Flink SQL Client创建表时,它会根据输入数据源的格式自动推断表结构和字段。对于Kafka的Protobuf格式数据,您需要在创建表时指定FIELD_DELIMITER和FIELD_QUOTE等属性,以便Flink能够正确解析数据。
例如,以下是一个创建表的示例:
CREATE TABLE my_table (
field1 INT,
field2 VARCHAR,
field3 DOUBLE
)
PROTOBUF(
field1 INT,
field2 VARCHAR,
field3 DOUBLE,
FIELD_DELIMITER '|',
FIELD_QUOTE '"',
FIELD_NULL '\N'
);
请确保您已经正确地定义了Protobuf类,并将其包含在项目的类路径中。如果您使用的是Maven或Gradle等构建工具,可以将这些类添加到项目的build.gradle或pom.xml文件中。
如果您仍然遇到问题,可以尝试以下方法:
依赖安装下。
如何解决Flink依赖冲突问题?https://help.aliyun.com/zh/flink/support/reference?spm=a2c4g.11186623.0.i78
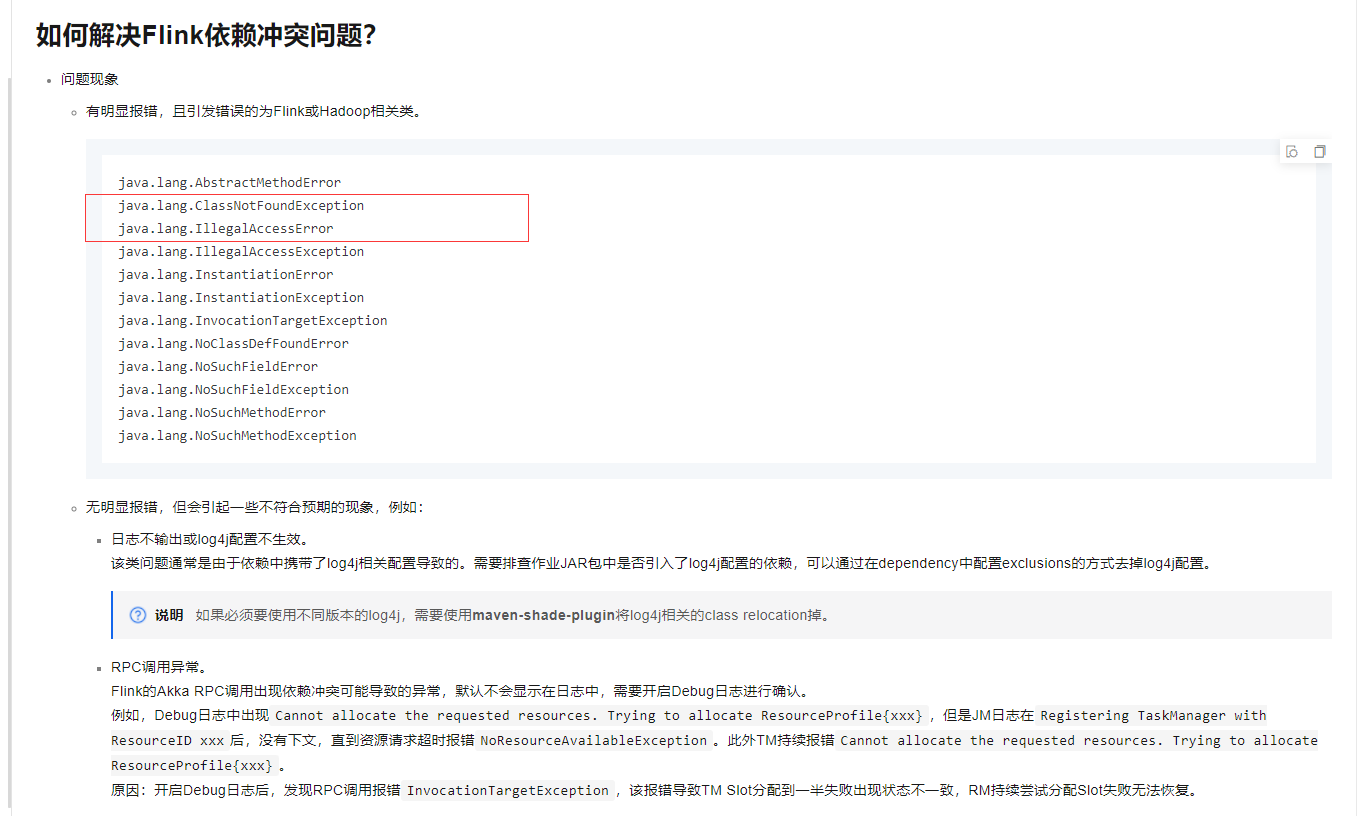
问题原因
作业JAR包中包含了不必要的依赖(例如基本配置、Flink、Hadoop和log4j依赖),造成依赖冲突从而引发各种问题。
作业需要的Connector对应的依赖未被打入JAR包中。
排查方法
查看作业pom.xml文件,判断是否存在不必要的依赖。
通过jar tf foo.jar命令查看作业JAR包内容,判断是否存在引发依赖冲突的内容。
通过mvn dependency:tree命令查看作业的依赖关系,判断是否存在冲突的依赖。
解决方案
基本配置建议将scope全部设置为provided,即不打入作业JAR包。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


