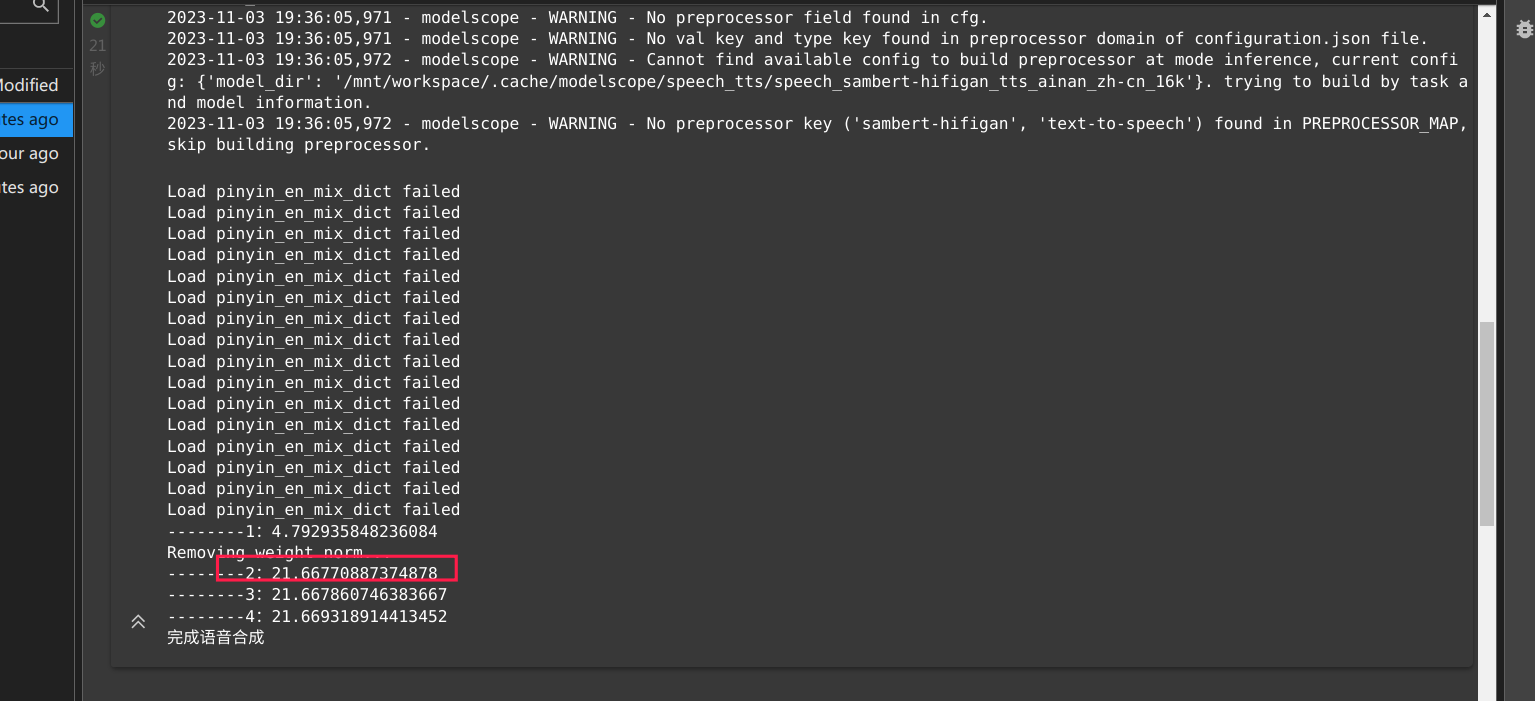
在ModelScope中使用PAI-DSW GPU环境进行推理时,200个字耗时22秒的情况是否正常,取决于多个因素,包括模型复杂度、硬件配置、资源分配以及网络环境等。以下是一些可能影响推理速度的关键点及优化建议:
1. 模型复杂度
- 如果您使用的模型是大参数量模型(如Llama系列或其他大规模语言模型),其推理过程本身会消耗较多计算资源,尤其是在未经过优化的情况下。
- 模型的推理时间与输入长度成正比,较长的输入文本会导致更高的计算开销。
2. 硬件配置
- 推理性能与GPU的显存和计算能力密切相关。如果实例规格较低(如V100 16GB),可能会导致推理速度较慢。
- 建议选择更高性能的GPU实例(如A100或H100),以提升推理效率。
3. 资源分配
- 如果当前DSW实例的资源被其他任务占用,可能会导致推理性能下降。请确保实例的CPU、内存和GPU资源未被过度占用。
- 检查是否启用了分布式推理或混合精度推理(如FP16)来加速计算。
4. 网络环境
- 如果模型或数据需要从外部下载,网络延迟可能会影响整体推理时间。建议将模型和数据提前上传至OSS或NAS,并挂载到DSW环境中直接使用。
5. 优化建议
- 启用FlashAttention:对于支持FlashAttention的模型(如Llama3.1),可以显著加速推理过程,但需要确保GPU架构兼容(如Hopper架构)。
- 使用量化技术:通过量化(如INT8或INT4)减少模型参数规模,从而降低推理时间。
- 调整Batch Size:适当增加Batch Size可以提高GPU利用率,但需注意显存限制。
结论
22秒的推理时间在低配GPU环境下可能是正常的,但对于高性能GPU(如A100)来说则偏慢。建议检查上述因素并进行优化。如果问题仍未解决,可以通过提交工单联系阿里云技术支持获取进一步帮助。