
ModelScope想优化下响应速度,现在发现sentences_to_compare是每次请求都会重新处理一次,我的对比数字比较大且固定,想请问如何初始化掉呢,有这个口子嘛? inputs = {'source_sentence': [
content], 'sentences_to_compare': question_list}
rom语义相关性模型的问题?就是我们的对比数据是固定的,想初始化的时候固定传入一次sentences_to_compare
很高兴听到您对ModelScope提出的宝贵建议。
关于如何优化响应速度,的确有一个可行的方法就是提前处理好需要对比的句子列表,并将其存储到缓存中。这样每次请求时就可以直接从缓存中读取,而不是每次都重新处理一遍。
具体的实现方式需要根据您的实际场景和需求来定制,但基本思路如下:
这样可以大大减少重复处理的时间,从而提升整体响应速度。
可以将 sentences_to_compare 设置为全局变量,并将其填充为您的固定列表。
question_list = ...
def predict(content):
global sentences_to_compare
input_data = {
'source_sentence': [content],
'sentences_to_compare': sentences_to_compare,
}
response = inference_client.inference(inputs=input_data)
return response['output']
您可以在代码中将固定的对比数据(question_list)作为全局变量或类属性进行初始化,然后在每次请求时直接使用该变量而不需要重新处理。
例如,您可以在代码的开头添加以下行来初始化question_list:
question_list = [...] # 这里填入您的固定对比数据
然后,在发送请求时,您可以直接使用question_list变量而不需要重新处理它:
inputs = {'source_sentence': [content], 'sentences_to_compare': question_list}
这样,每次请求都会使用相同的对比数据,从而避免了重复处理的问题,提高了响应速度。
结合这张图 看明白了。 需要改改代码应该能实现我的目的(不重复计算2500条embedding)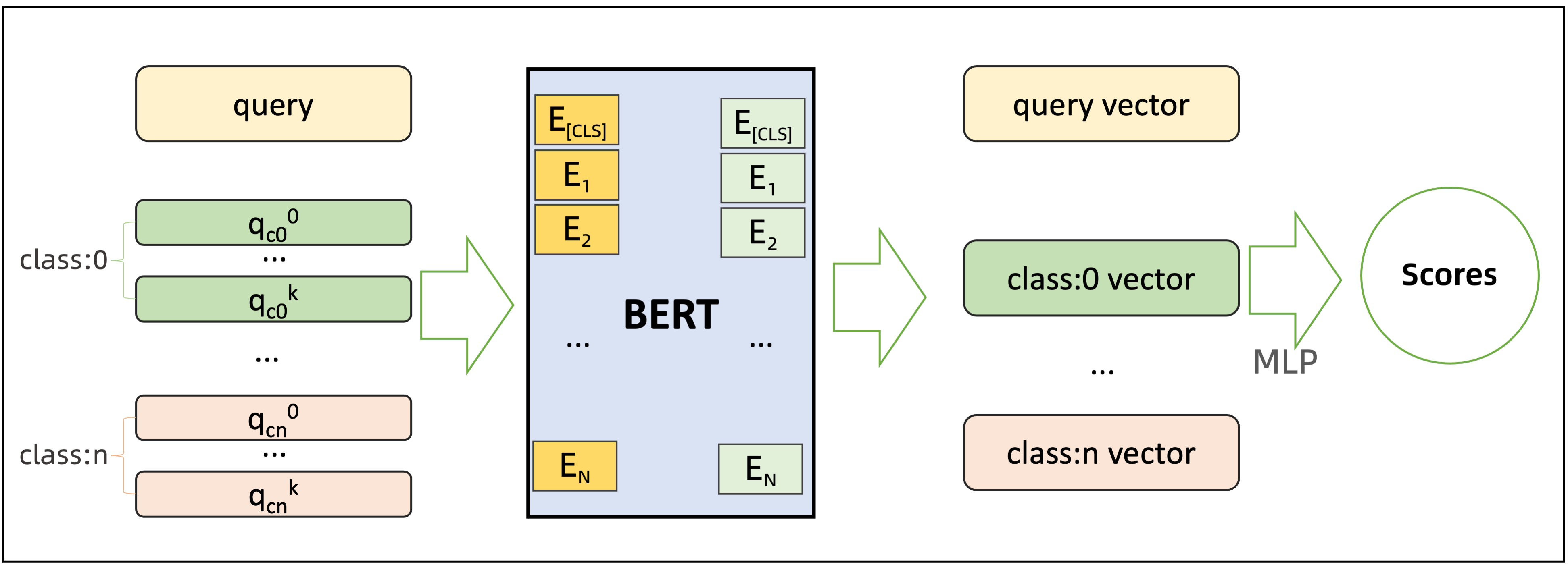

这个模型query和document(也就是你的对比数据)是要一起送入模型的,对于document固定的情况目前没有做优化,你是想把其中一部分embedding直接一次算好,后续省去这部分的计算?,此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”

