
DataWorks中maxcompute如何设置用户访问权限?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,MaxCompute的用户访问权限可以通过以下步骤进行设置:
首先,你需要进入MaxCompute的数据开发界面。
在开发界面中,找到并点击"权限管理"选项。
在权限管理页面中,你可以看到所有的RAM用户(包括子账号)。你可以为每个用户分配不同的权限,包括读取、写入、删除等操作。
对于生产环境的MaxCompute项目,只有被赋予调度访问身份的RAM用户(子账号)才能拥有较大的权限。其他RAM用户(子账号)则没有生产环境项目的权限。如果你需要操作生产表,你需要前往安全中心申请权限。
DataWorks为你提供了一个默认的审批流程。你可以根据实际情况,自行修改或者添加新的审批流程。
总的来说,DataWorks通过空间预设角色或空间自定义角色与开发环境引擎Role映射,来让被授予空间角色的RAM用户,拥有该空间角色映射的开发引擎Role所拥有的MaxCompute引擎权限,但默认无生产权限。
在DataWorks中,您可以按照以下步骤设置MaxCompute用户的访问权限:
设置用户访问权限的常见方法有如下几种:Package方案,通过打包授权进行权限精细化管控。 Package用于解决跨项目空间的数据共享及资源授权问题。通过Package授予用户开发者角色后,用户拥有所有权限,风险不可控。详情请参见基于Package的跨项目空间资源访问。下图为DataWorks开发者角色的权限。
由上图可见,开发者角色对工作空间中的Package、Functions、Resources和Table默认有全部权限,不符合权限配置的要求。下图为通过DataWorks添加子账号并赋予开发者角色的权限。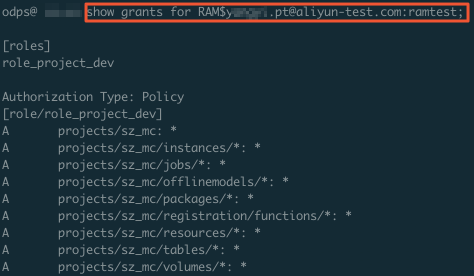
由此可见,通过打包授权和DataWorks默认的角色都不能满足特定用户访问指定UDF的需求。例如,授予子账号RAM$xxxxx.pt@aliyun-test.com:ramtest开发者角色,则默认该子账号拥有当前工作空间中全部对象的所有操作权限,详情请参见用户授权。在DataWorks中新建角色进行权限管控。 进入DataWorks的工作空间管理 > MaxCompute高级配置页面,在左侧导航栏上单击自定义用户角色进行权限管控。但是在MaxCompute高级配置中,只能针对某个表或项目进行授权,不能对资源和UDF进行授权。Role Policy结合Project Policy实现指定用户访问指定UDF。通过Policy可以精细化地管理具体用户对特定资源的具体权限粒度。说明 为了安全起见,建议初学者使用测试项目来验证Policy。因此您可以通过Policy方案实现特定UDF被指定用户访问:如果您不想让其他用户访问工作空间内具体的资源,在DataWorks中添加数据开发者权限后,再根据Role Policy的操作,在MaxCompute客户端将其配置为拒绝访问权限。如果您需要指定用户访问指定资源,通过Role Policy在DataWorks中配置数据开发者权限后,再根据Project Policy的操作,在MaxCompute客户端将其配置为允许访问权限。
https://help.aliyun.com/document_detail/106081.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


