
ModelScope今天用swift调llama7b有这样的报错,不知道大牛们有没有什么建议和解决办法呢?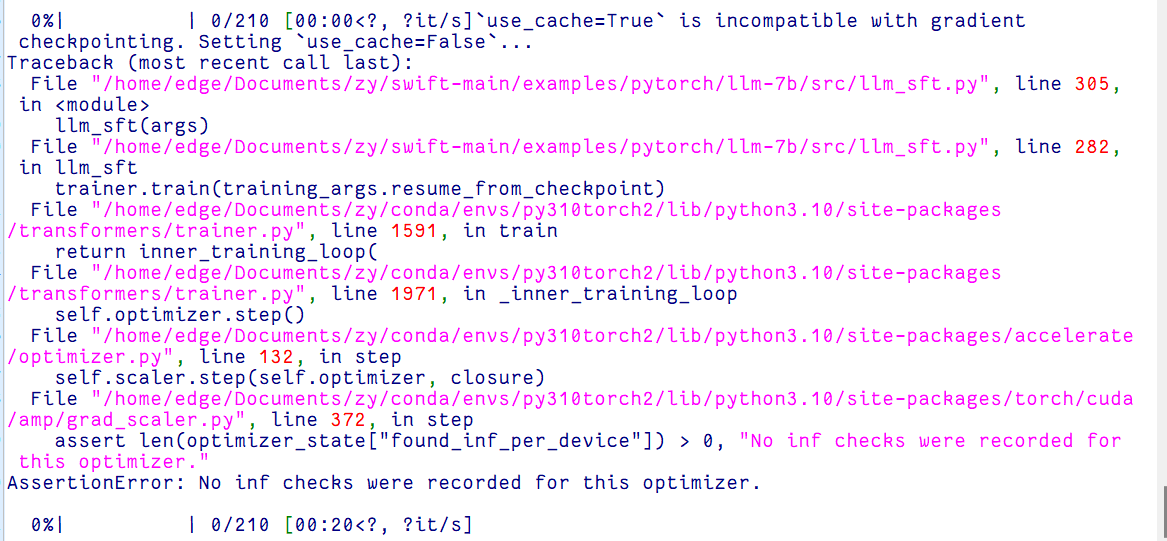
根据您提供的报错信息以及知识库中的相关资料,以下是针对ModelScope使用swift调用Llama-7B模型时可能遇到问题的分析与解决建议:
在调用Llama-7B模型时,环境配置是关键。请确保以下几点: - Python版本:建议使用Python 3.9及以上版本。 - 依赖库版本:需要安装正确的transformers和modelscope版本。例如:
pip install modelscope==1.12.0 transformers==4.37.0
如果版本不匹配,可能会导致调用失败。 - CUDA和GPU驱动:确保您的GPU驱动和CUDA版本与torch兼容。如果使用的是NVIDIA A10或V100等高性能GPU,请确认显存是否满足需求(推荐至少16GB显存)。
重要提示:如果环境未正确配置,可能会出现类似ModuleNotFoundError或CUDA out of memory的错误。
根据知识库中的说明,Llama-7B模型文件较大,下载过程中可能会因网络问题或磁盘空间不足导致文件损坏或不完整。建议按照以下步骤重新下载模型: 1. 使用modelscope的snapshot_download方法下载模型:
from modelscope.hub.snapshot_download import snapshot_download
snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='.', revision='master')
pytorch_model.binconfig.jsontokenizer.model如果环境和模型文件均无问题,但仍然报错,请检查以下内容: - Swift代码实现:确保调用逻辑符合modelscope的API规范。例如:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 初始化pipeline
pipe = pipeline(task=Tasks.text_generation, model='LLM-Research/Meta-Llama-3-8B-Instruct')
# 调用模型生成文本
result = pipe('Hello, who are you?')
print(result)
如果调用方式不符合规范,可能会导致AttributeError或TypeError。
Failed to load model,可能是模型路径或版本号设置错误。请确认cache_dir和revision参数是否正确。根据知识库中的案例,以下是几种常见报错及其解决方法: 1. 报错:CUDA out of memory - 原因:显存不足,无法加载模型。 - 解决方法: - 尝试使用量化版本的模型(如Int8或Int4)。 - 减少batch_size或max_length参数。 - 如果使用多卡训练,确保正确配置tensor parallelism。
报错:ModuleNotFoundError: No module named 'xxx'
pip install colossalai gradio
报错:HTTP 403 Forbidden
export http_proxy=http://your-proxy-server:port
export https_proxy=http://your-proxy-server:port
如果上述方法仍无法解决问题,建议采取以下措施: - 查看日志文件:检查wandb或其他日志工具生成的输出文件,定位具体错误原因。 - 加入技术支持群:通过钉钉群(群号:64970014484)联系阿里云工程师,提供详细的报错信息和复现步骤。
通过以上步骤,您可以逐步排查并解决ModelScope使用swift调用Llama-7B模型时的报错问题。如果仍有疑问,请提供更多具体的报错信息,以便进一步分析和解决。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
