
ModelScope中,部署创空间之前,在云端Notebook上先跑一个语音识别(长语音)的模型, 无论是CPU还是GPU环境, 云端都是自动杀死进程, 这是何理?
2023-10-10 13:46:04,459 - modelscope - INFO - Model revision not specified, use the latest revision: v1.2.0
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 518/518 [00:00<00:00, 354kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 15.1k/15.1k [00:00<00:00, 4.23MB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 27.3k/27.3k [00:00<00:00, 16.1MB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 7.85k/7.85k [00:00<00:00, 5.28MB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1.64M/1.64M [00:00<00:00, 33.0MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 1.19k/1.19k [00:00<00:00, 824kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 2.16M/2.16M [00:00<00:00, 30.1MB/s]
2023-10-10 13:46:07,906 - modelscope - INFO - loading vad model from /mnt/workspace/.cache/modelscope/damo/speech_fsmn_vad_zh-cn-16k-common-pytorch ...
2023-10-10 13:46:08,098 - modelscope - INFO - Model revision not specified, use the latest revision: v1.1.7
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 2.72M/2.72M [00:00<00:00, 44.2MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 452/452 [00:00<00:00, 280kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 278M/278M [00:01<00:00, 176MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 2.72M/2.72M [00:00<00:00, 173MB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 863/863 [00:00<00:00, 597kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 15.6k/15.6k [00:00<00:00, 9.68MB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 151k/151k [00:00<00:00, 16.4MB/s]
2023-10-10 13:46:12,765 - modelscope - INFO - loading punctuation model from /mnt/workspace/.cache/modelscope/damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch ...
2023-10-10 13:46:30,116 - modelscope - INFO - Decoding with pcm files ...
batch_size_token: 6000
已杀死
总是在batch_size_token: 6000之后,出现"已杀死".
您试一下cd到/mnt/workspace/.cache/modelscope/damo,把这个模型的缓存删除,然后pipeline中指定model_revision=None。inference_pipeline = pipeline(
task=Tasks.voice_activity_detection,
model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',
model_revision=None,
)这里model_revision="v1.2.4"这几个模型的缓存您都清理一下,inference_pipeline中punc_model和vad_model两个参数您先去掉跑一下试试。模型卡片代码可以跑。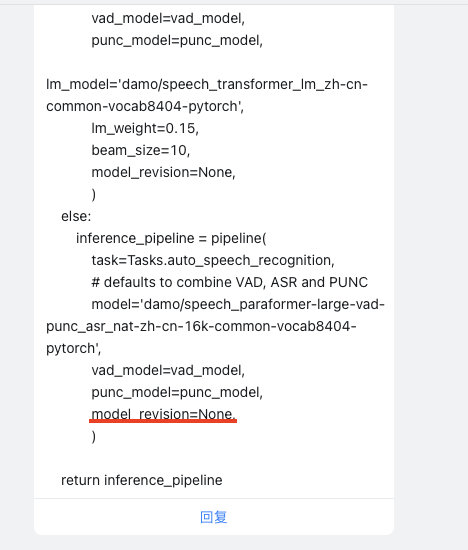
——此回答整理自钉群:魔搭ModelScope开发者联盟群 ①
