
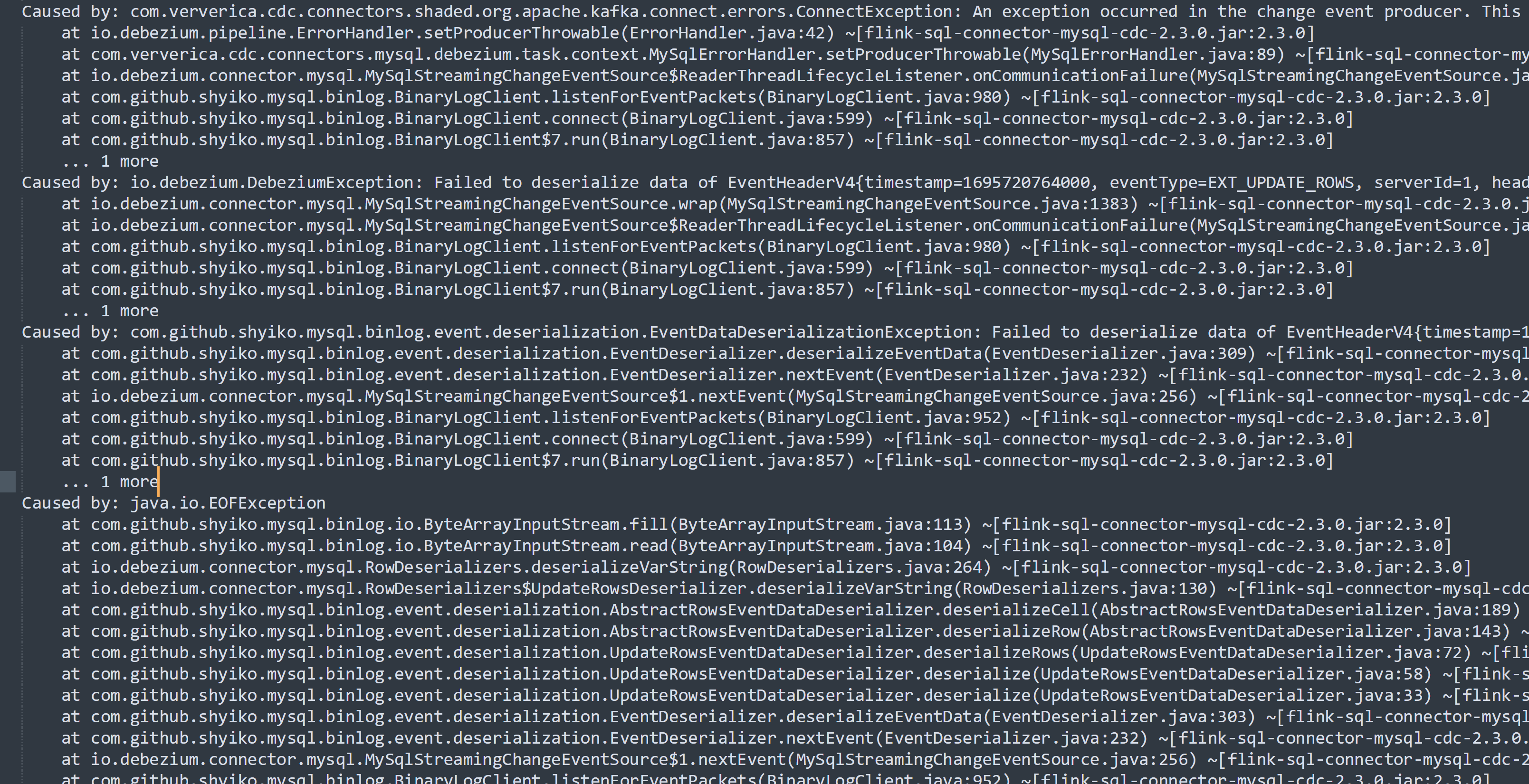
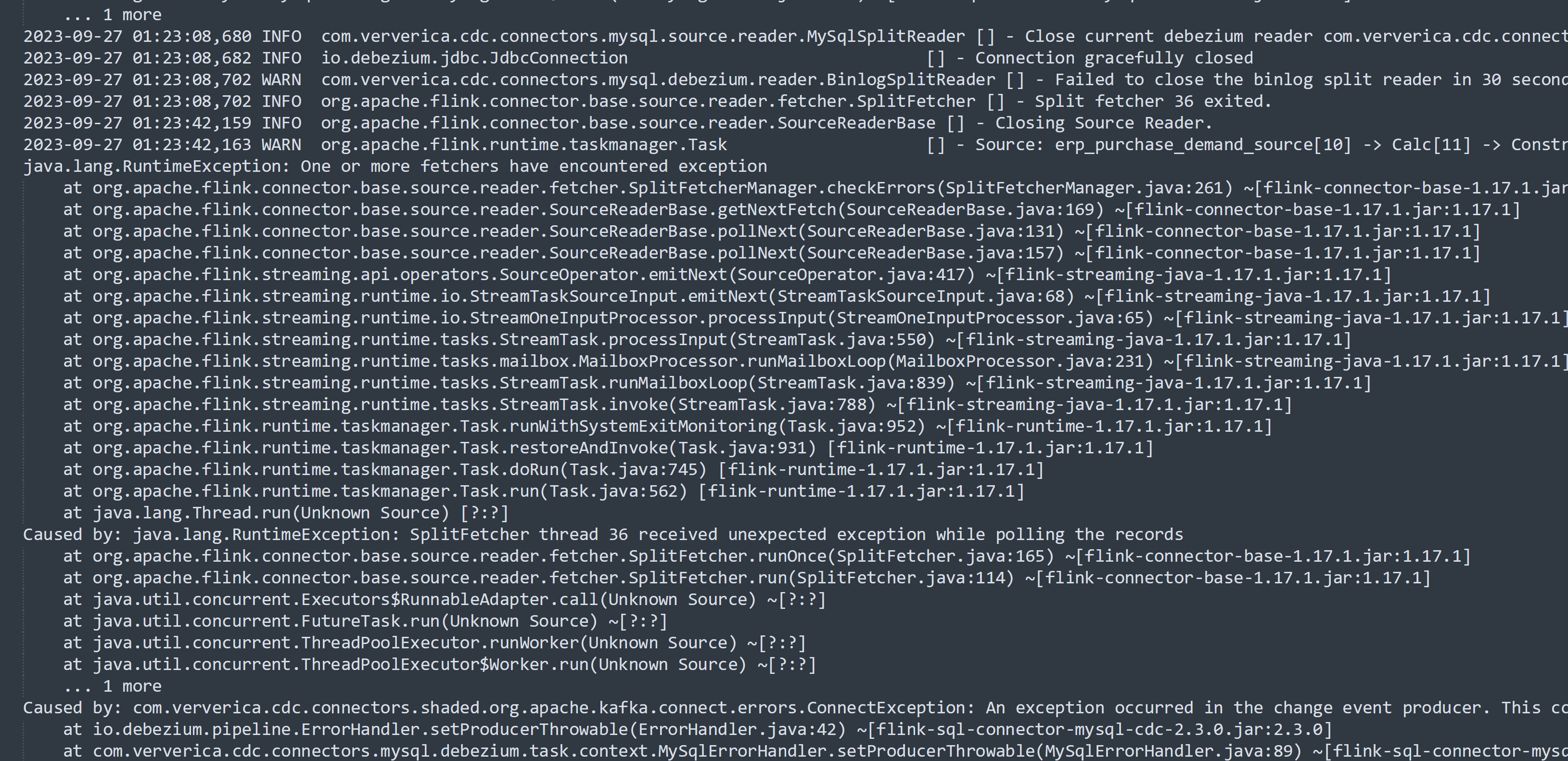
Flink CDC这个问题究竟修复了没?https://github.com/ververica/flink-cdc-connectors/issues/432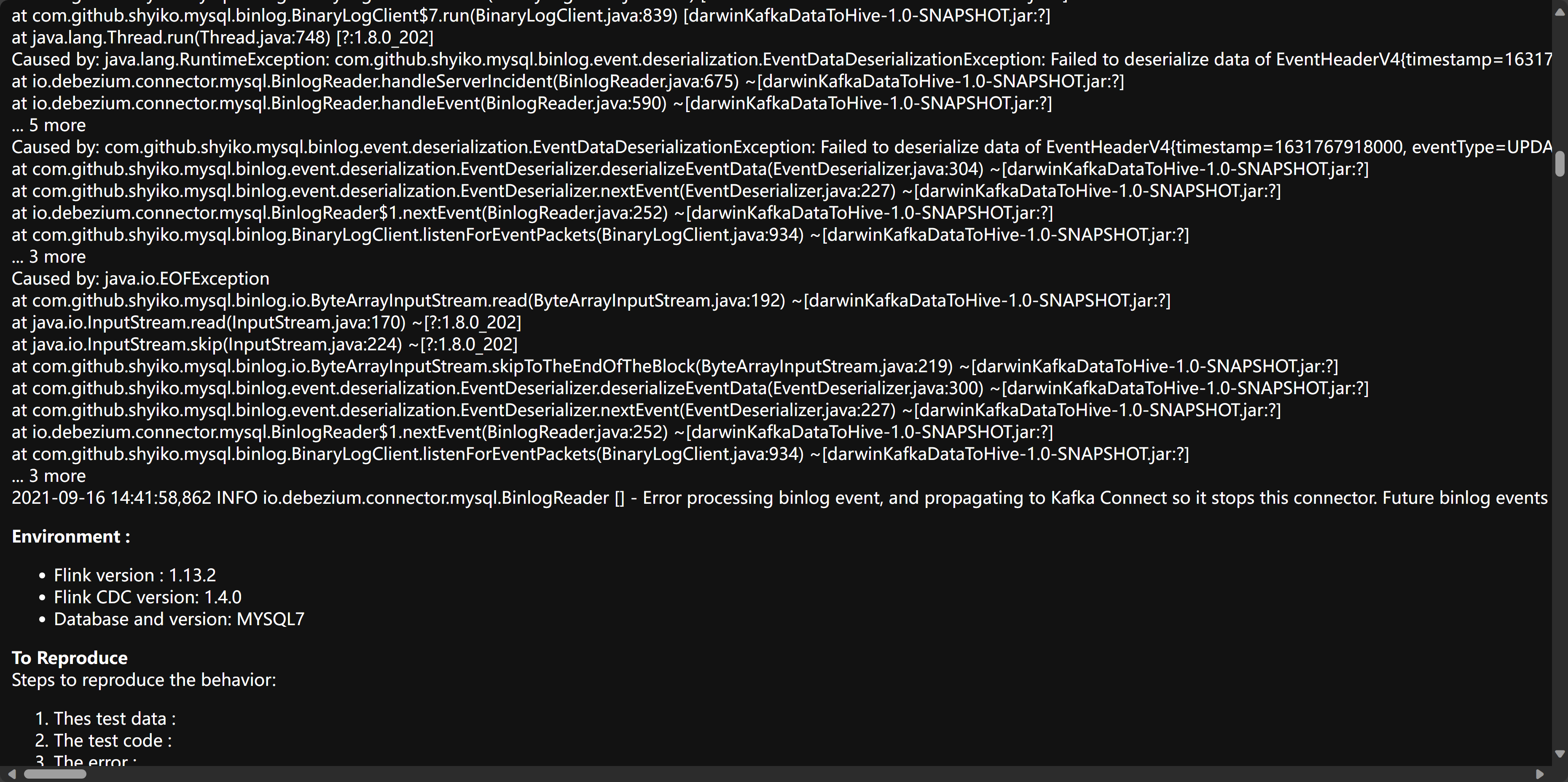
这个版本
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题和知识库中的参考资料,以下是关于Flink CDC相关问题的详细解答:
您提到的问题与Flink CDC连接器在处理MySQL CDC源表时的行为有关,具体表现为作业失败或无法正确消费增量数据。该问题曾在GitHub上被报告(Issue #432),并附带了相关的错误截图。
问题描述
根据知识库中的信息,Flink CDC作业在以下场景中可能会出现问题:
修复情况
知识库中提到,阿里云实时计算Flink版在后续版本中对MySQL CDC连接器进行了多项优化和修复,包括:
op_type虚拟列获取数据操作类型(如+I、-D等),从而增强下游业务逻辑的灵活性。sink.ignore-null-when-update参数时的批量执行优化。这些改进表明,部分已知问题已在较新的版本中得到修复。如果您使用的是VVR 8.0.7或更高版本(基于Apache Flink 1.17.2的企业级引擎),上述问题可能已被解决。
升级到最新版本
建议您将Flink引擎升级至VVR 8.0.7或更高版本,以利用最新的MySQL CDC连接器优化和修复。升级步骤可参考官方文档中的[作业引擎版本升级指南]。
调整Checkpoint配置
如果您的作业在全量阶段完成后卡住,可能是由于Checkpoint间隔时间设置不合理。建议根据业务需求调整Checkpoint间隔时间,例如设置为1分钟或更短。
启用Source复用功能
如果您的作业中存在多个MySQL CDC源表,且它们的配置项(如库名、表名和server-id除外)相同,可以启用Source复用功能以减少MySQL服务器的连接压力。
检查MySQL实例类型
确保您使用的MySQL实例支持Binlog写入。如果使用的是RDS MySQL 5.6备库或只读实例,建议升级至更高版本或切换至可写实例。
验证消费位置
在作业重启时,确保MySQL CDC源表能够从正确的Binlog位点继续消费。您可以通过配置scan.startup.mode参数选择消费模式,例如latest-offset或specific-offset。
ClassNotFoundException等错误,请确保正确配置pipeline.classpaths以加载所需的uber JAR包。同时,在作业打包上传到阿里云实时计算Flink版之前删除该配置。flink-sql-connector-mysql-cdc-2.2-SNAPSHOT.jar),请自行下载源码并编译对应的JAR包。建议优先使用稳定版本(如flink-sql-connector-mysql-cdc-2.1.0.jar)以避免潜在问题。根据知识库中的信息,Flink CDC连接器的相关问题已在较新的版本中得到了显著优化和修复。建议您升级至VVR 8.0.7或更高版本,并根据上述解决方案调整配置以确保作业的稳定性和性能。如果问题仍然存在,请联系阿里云技术支持团队获取进一步帮助。
希望以上信息对您有所帮助!
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


{kind=link}