
有人用过flink官方operator的reactive模式吗?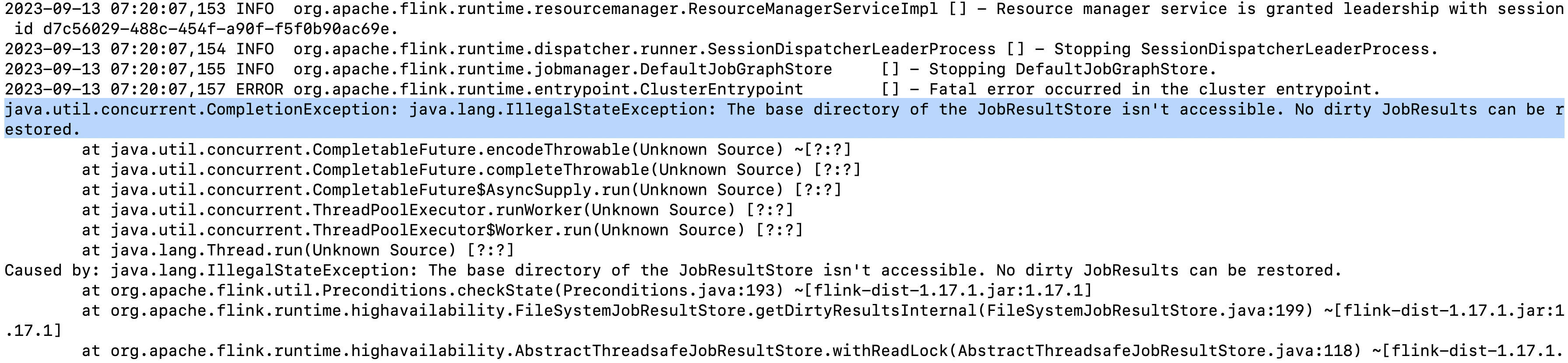
这个错是什么原因呀?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
需要在Flink作业中正确配置checkpointLocation。这可以通过.option("checkpointLocation", "path/to/checkpoint_directory")来完成,其中path/to/checkpoint_directory应该指向一个可访问的文件系统路径。
df.writeStream
.format("console")
.option("truncate", false)
.option("checkpointLocation", "path/to/checkpoint_directory")
.outputMode("complete")
.start()
.awaitTermination()
——参考链接。
Apache Flink 的 Reactive 模式是一种资源管理模式,它允许 Flink 作业根据当前的资源需求动态地请求和释放资源。在 Reactive 模式下,Flink 作业会根据实际的负载情况自动调整其并行度,从而更好地利用集群资源。
使用 Flink 官方的 Operator(操作符)在 Reactive 模式下,通常意味着你的 Flink 作业能够响应集群的资源变化,并根据需要调整其计算资源。这对于处理动态负载和高效利用集群资源非常有用。
在 Reactive 模式下,Flink 的 JobManager 会监控集群的资源使用情况,并根据需要向 ResourceManager 发送请求,以增加或减少 TaskManager 的数量。这样,Flink 作业可以在运行时动态地扩展或缩减其计算能力,以适应工作负载的变化。
要使用 Flink 官方的 Operator 在 Reactive 模式下,你需要确保你的 Flink 集群配置正确,并且支持动态资源分配。此外,你还需要编写能够适应资源变化的 Flink 作业,这可能涉及到使用 Flink 提供的 API 和操作符来动态调整作业的并行度和资源需求。
需要注意的是,Reactive 模式是 Flink 1.13 版本引入的一个功能,并且在后续的版本中可能会有所改进和变化。因此,建议查阅 Flink 官方文档以获取最新和详细的信息,以了解如何使用 Reactive 模式以及相关的配置和操作指南。
总结来说,使用 Flink 官方的 Operator 在 Reactive 模式下可以帮助你更好地管理 Flink 作业的资源需求,提高集群的资源利用率,并应对动态负载的挑战。但是,你需要确保你的 Flink 集群和作业都配置正确,并且能够适应资源的动态变化。
ProcessFunction: ProcessFunction允许用户对事件进行逐条处理,并且可以注册定时器来实现反应式编程逻辑,根据事件到达或者定时器触发来改变状态或发出新的事件。
在传统的 Flink 批处理和流处理模式中,数据是以有界的形式进行处理的,需要等待所有数据到达后才能开始执行计算。而在 Reactive 模式中,Flink 可以以无界流的方式进行处理,即可以在数据到达之前就开始执行计算。这种模式对于需要快速响应和低延迟的应用场景非常有用,例如实时监控、反欺诈、实时推荐等。
使用 Flink 的 Reactive 模式可以通过以下步骤进行:
升级到 Flink 1.14 版本或更高版本。Reactive 模式从 Flink 1.14 开始引入,并且在后续版本中得到了改进和优化。
在代码中使用 ReactiveExecutor 创建一个 Reactive 执行环境。可以选择使用 ExecutionEnvironment 或 StreamExecutionEnvironment,具体取决于你的应用场景。
java
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ReactiveExecutor reactiveExecutor = new ReactiveExecutor(env);
使用 Reactive 执行环境创建具有 Reactive 特性的算子。Flink 官方提供了一些支持 Reactive 模式的算子,例如 ReactiveSource、ReactiveSink、ReactiveOperator 等。可以根据具体的需求选择适合的算子。
java
DataSet input = env.fromElements(1, 2, 3);
ReactiveSource source = ReactiveSource.from(input);
ReactiveOperator operator = ReactiveOperator
.fromFunction((Integer i) -> "Number: " + i);
ReactiveSink sink = ReactiveSink.println();
source.transform(operator).addSink(sink);
执行作业。在 Reactive 模式中,作业会立即开始执行,无需等待数据到达。
java
reactiveExecutor.execute();
使用 Flink 的 Reactive 模式需要根据具体的应用场景和需求进行调整和测试。这种模式对于一些特定的实时应用非常有用,但并不适用于所有情况。因此,在使用之前,请确保了解你的应用是否适合使用 Reactive 模式,并进行充分的测试和评估。
根据错误信息,看起来是Flink JobResultStore相关的异常。具体来说,问题出在JobResultStore(用于存储作业结果)的基础目录不可访问。这可能是由于以下几种情况导致:
要解决这个问题,请尝试检查以下几个方面:
这段log的信息指出,Flink的ClusterEntrypoint抛出了一个严重的错误,原因是JobResultStore无法访问基目录。同时,也有一个CompletableFuture.encodeThrowable线程停止了。
这个错误可能是由以下几个原因引起的:
文件权限不足:默认情况下,Flink会在本地磁盘上创建一个临时目录来存储作业的状态。如果没有足够的权限,可能会出现此问题。确认一下你的机器有足够的权限来访问这个路径。
系统资源耗尽:如果内存不足或是CPU负载过高,可能导致文件系统服务出现问题,进而影响到JobResultStore的正常工作。
兼容性问题:有时,特定的操作系统或软件组合可能存在兼容性问题,这也可能导致类似的错误。
冲突:如果有其他应用程序正在占用相同的文件夹,可能会阻止Flink获取对JobResultStore的访问。
为了确定问题的根本原因,您可以按照以下顺序采取行动:
查看您的系统状态,特别是内存和CPU利用率,确保它们处于合理水平。
检查文件权限,确保Flink能够访问指定的目录。如果您怀疑这是问题所在,可以尝试提升Flink对该目录的所有者和组的权限。
尝试禁用HDFS高可用性特性,因为这可能会涉及到更少的并发活动,从而减轻潜在的压力。
更新Flink到最新版本,因为它可能已经修复了一些早期版本中存在的bug。
如果以上措施都无法解决问题,联系Flink团队寻求技术支持也是一个可行的选择。他们可能需要远程登录到您的服务器来进行诊断。
问题可能是由于JobResultStore的基本目录不可访问导致的。这可能是由于以下原因:
jobmanager.rpc.address: jobmanager
jobmanager.rpc.port: 6123
jobmanager.local.dir: /path/to/your/local/dir
Flink 的 Reactive Programming 模式允许你以非阻塞的方式处理数据流,这对于构建响应式应用程序非常有用。
以下是一个简单的示例,演示了如何使用 Flink 的 DataStream API 以 reactive 模式处理数据流:
我们创建了一个自定义的数据源,每秒发送一个数据。然后使用 map 操作将字符串转为大写。注意,这里的数据流处理是非阻塞的,因此 run 方法中的数据处理不会阻塞主线程。这种处理方式非常适合构建响应式应用程序。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


