
文字识别OCR文件经常会超过页数和大小的限制 有什么办法吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,文字识别OCR的API接口对于请求参数中的资源文件大小以及尺寸通常都会有一定限制,比如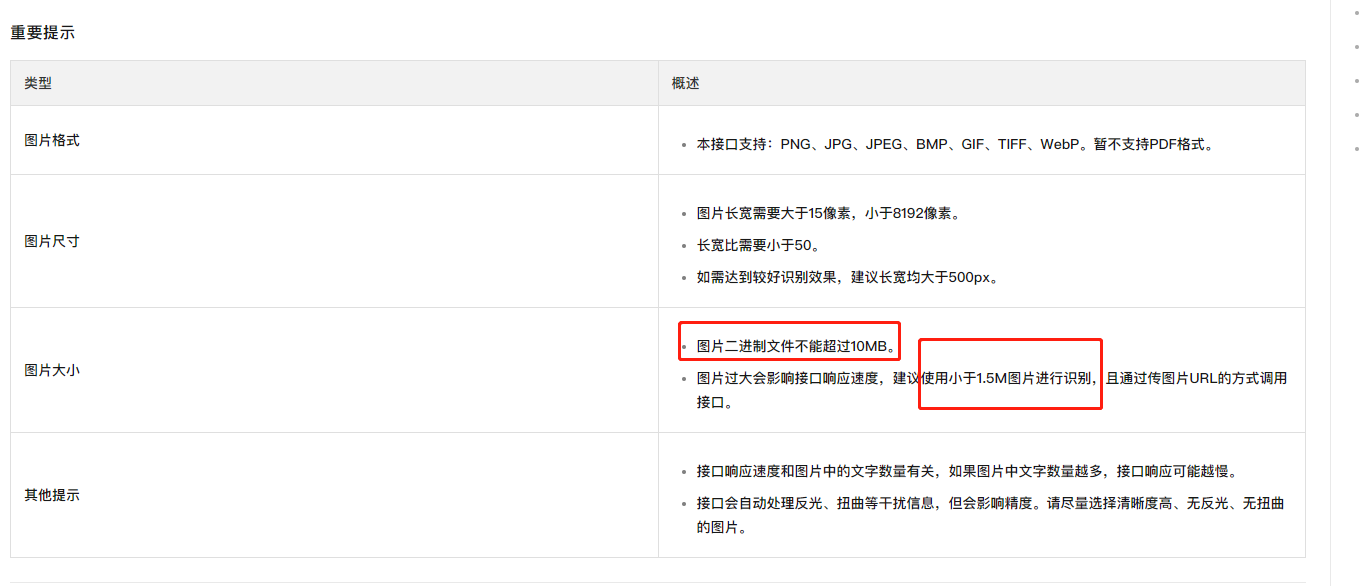
如果您上传的文件页数或者大小超过API接口限制的话,那么通常是不能识别的,您可以先通过其他工具对资源文件进行切割或者压缩后再进行文字识别。
楼主你好,如果您使用的是阿里云的文字识别OCR服务,那么您需要遵守阿里云的相关限制规定,即每次请求的文件大小不能超过20MB,每个文件最多支持处理50页。如果您的文件超过了这些限制,建议您将文件拆分成多个小文件进行处理。您可以使用一些文件分割工具,如 Adobe Acrobat Pro、WinRAR 等软件将大文件拆分成多个小文件,然后再逐个进行识别处理。
另外,您也可以考虑使用其他的OCR识别服务,如百度OCR、腾讯OCR 等,这些服务可能具有不同的文件大小和页数限制,您可以根据自己的需求选择合适的服务进行使用。

对于OCR文件超过页数和大小限制的问题,可以考虑以下几种解决方案:
分批处理:将大型OCR文件分成多个小文件进行处理,然后将结果合并。这样可以避免一次性处理过大的数据量,减轻计算负担。
优化OCR引擎:选择更高效的OCR引擎,可以提高识别速度和准确率,减少文件大小。
压缩文件:使用压缩软件对OCR文件进行压缩,可以减小文件大小。但需要注意的是,压缩可能会影响文件的准确性,因此需要在压缩前备份原始文件。
使用云计算:将OCR任务分发到云端进行处理,可以利用云计算的强大计算能力和弹性扩展能力,处理大型OCR文件。
优化扫描质量:在进行OCR扫描时,可以调整扫描参数,优化扫描质量,减少识别错误和文件大小。
总之,针对OCR文件超过页数和大小限制的问题,需要根据具体情况选择合适的解决方案,以确保OCR处理的准确性和效率。

当文字识别OCR文件超过页数和大小的限制时,您可以考虑以下解决方案:
分割文件:如果文件超过了OCR服务提供商所允许的最大页数或大小限制,您可以将文件分割成多个较小的部分进行识别。使用适当的工具或方法,将文件拆分为多个文件,确保每个文件都在限制范围内。
压缩和优化:对于文件大小超过限制的情况,您可以尝试压缩文件以减小其大小。使用常见的文件压缩算法(如ZIP),可以有效地减小文件的大小,从而满足OCR服务的要求。此外,还可以优化图像质量和格式,以减少文件大小。
增加配额或升级计划:一些OCR服务提供商可能基于配额来限制文件大小和页数。您可以考虑增加配额或升级到更高级别的计划,以获得更大的文件处理能力。这需要根据具体的OCR服务提供商来确定可行性和可用性。
使用本地OCR:如果OCR服务提供商无法满足您的文件大小和页数需求,您可以考虑使用本地OCR解决方案。本地OCR软件通常不受限于在线服务的限制,并且可以适应更大规模的文件处理。这种解决方案可能需要更多的资源和技术支持,但可以提供更大的灵活性和控制权。


