
文字识别OCR现在pdf 能解析吗?有个图 高的像素 10000+ 是不是解析不出来。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,文字识别OCR部分场景功能支持PDF解析,比如增值税发票识别、混贴发票识别、火车票识别、航空行程单识别、定额发票识别、通用机打发票识别、增值税发票卷票识别。l
另外OCR识别接口均支持图片格式数据,包括:.jpg/.jpeg/.png/.bmp./gif./tiff./webp,请注意图片大小不超过10M,最短边大于15像素,最长边不超过8192像素;超过指定像素可能解析不出来或者解析出错
楼主你好,是的,阿里云文字识别OCR目前支持PDF格式的解析,但对于像素数过高的图片,可能无法完全识别其中的文本。建议将图片进行压缩或切割,以提高识别效果。
是的,文字识别OCR可以解析PDF文件。但是,如果PDF文件中的高像素图像导致OCR无法解析文本,则可能会出现问题。为了解决这个问题,您可以尝试以下方法:
只有票证支持pdf,单张图片大小不超过10M, 且图片最长边不超过8192像素,最短边不小于15像素。当长边超过1024像素时,长宽比不超过1:50。
建议单字大小保持在10-50像素内,以获得较好的识别效果。
.pdf/.ofd 类型文件,仅识别第一页阿里云混贴发票识别,是阿里云官方自研OCR文字识别产品,适用于获取多种发票集合在一个页面的场景,需要获取多种发票上的关键信息。
阿里云OCR产品基于阿里巴巴达摩院强大的AI技术及海量数据,历经多年沉淀打磨,具有服务稳定、操作简易、实时性高、能力全面等几大优势。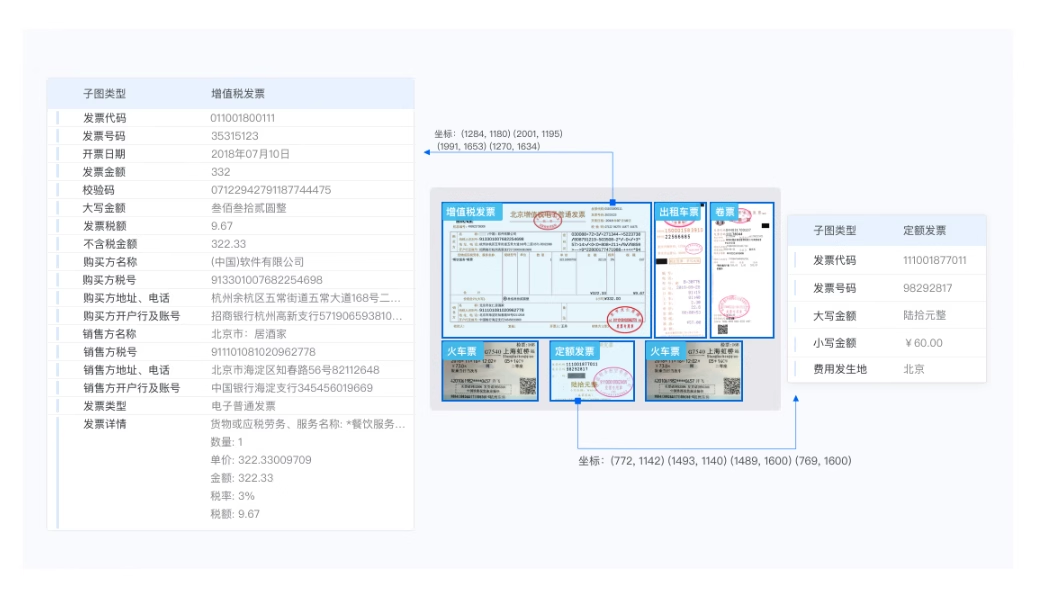
阿里云的文字识别OCR服务目前是支持解析PDF文件的,可以提取其中的文字内容。无论PDF的像素多高,OCR服务都应该能够处理。
然而,对于非常高分辨率的图像(例如像素数超过10,000的图像),会有一些注意事项:
处理时间:对于高分辨率的图像,OCR可能需要更长的处理时间来完成解析。这是因为高分辨率图像包含更多的细节和数据量,需要更多的计算资源来进行处理。
图像预处理:在将高分辨率图像传递给OCR服务之前,建议先进行必要的图像预处理。这可能包括降低图像的分辨率、压缩图像大小或者裁剪图像以减少处理的复杂性。这样做可以提高处理效率并降低潜在的问题。
阿里云的文字识别OCR服务可以处理PDF文档,并且支持对PDF中的文字进行识别和提取。您可以将PDF文档作为输入,进行文字识别操作。
关于图像的大小和分辨率,OCR服务通常有一定的限制。阿里云OCR服务对于图像的大小和分辨率有一定的限制,超过一定范围可能会导致识别结果不准确或无法识别。
对于高像素的图像,例如像素超过10000的图像,其中的细节可能会对识别结果产生影响。较大的图像需要更长的处理时间,并且在分析图像时会对计算和内存资源有更高的要求。因此,处理较大图像时可能会导致性能下降或无法正常识别。
参考https://market.aliyun.com/products/57124001/cmapi00043678.html?spm=5176.730005.result.2.78cd3524WMVOlS&innerSource=search_pdf%E8%AF%86%E5%88%AB#sku=yuncode37678000010 页数不超过20页,此回答整理自钉群“阿里云读光OCR客户交流反馈群 1”


