
请问一下PolarDB 广播表和分区表有什么差别,主要体现在那些地方?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
PolarDB的广播表和分区表是两种不同的表类型,它们之间的差别主要体现在以下几个方面:
1、数据存储方式:广播表和分区表的数据存储方式不同。广播表的数据会被存储在所有节点上,而分区表的数据会被分散存储在不同的分区上。
2、查询性能:广播表和分区表的查询性能也不同。广播表的查询性能较差,因为需要在所有节点上进行查询,而分区表的查询性能较好,因为可以在特定的分区上进行查询。
3、数据管理:广播表和分区表的数据管理方式也不同。广播表的数据管理比较简单,因为数据会被存储在所有节点上,而分区表的数据管理比较复杂,因为需要管理不同的分区。
4、数据备份和恢复:广播表和分区表的数据备份和恢复方式也不同。广播表的数据备份和恢复比较简单,因为数据会被存储在所有节点上,而分区表的数据备份和恢复比较复杂,因为需要备份和恢复不同的分区。
总的来说,广播表和分区表各有优缺点,您可以根据实际需求选择适合的表类型。
PolarDB中的广播表和分区表是两种不同的表设计方式,它们在数据存储和查询方面有一些差别。
数据存储方式:
广播表:广播表将数据复制到每个节点上,每个节点都存储完整的表数据。这种方式适用于小型表或者需要在所有节点上进行全局查询的场景。
分区表:分区表将数据按照某个列的值进行分区,不同分区的数据存储在不同的节点上。每个节点只存储部分数据,可以根据查询条件只在特定的节点上进行查询。这种方式适用于大型表或者需要按照特定条件进行查询的场景。
数据查询方式:
广播表:由于每个节点都存储完整的表数据,所以在广播表上的查询可以在任何节点上进行,不需要数据传输。这种方式适用于全局查询或者需要在任意节点上进行查询的场景。
分区表:由于数据分布在不同的节点上,查询时只需要在包含所需数据的节点上进行查询,可以减少数据传输和查询时间。这种方式适用于按照特定条件进行查询的场景。
数据维护和管理:
广播表:由于每个节点都存储完整的表数据,对广播表的维护和管理需要在每个节点上进行。例如,对表结构的修改需要在每个节点上执行。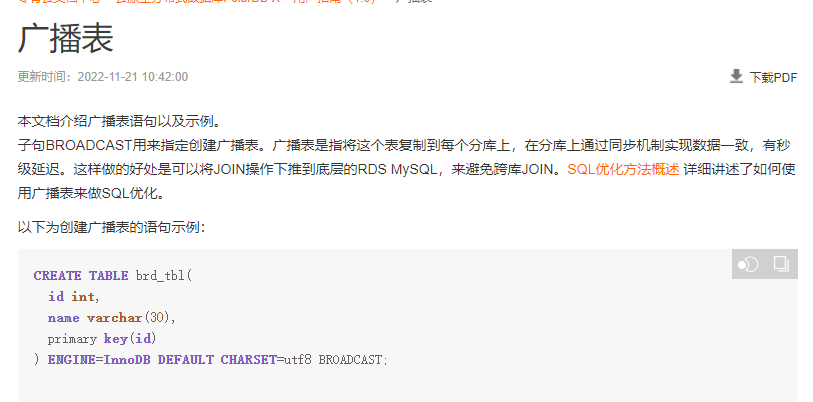
分区表:由于数据分布在不同的节点上,对分区表的维护和管理可以在特定的节点上进行。例如,对某个分区的数据进行操作只需要在包含该分区的节点上执行。
选择广播表还是分区表取决于具体的业务需求和查询模式。广播表适用于小型表和全局查询,而分区表适用于大型表和按照特定条件查询的场景。需要根据具体的数据量、查询需求和维护成本等因素进行权衡和选择。
楼主你好,阿里云PolarDB广播表和分区表的主要区别在于数据的存储方式和查询性能。
广播表将表的全部数据以相同的方式复制到每个节点上存储,适用于全节点的查询或少量节点的查询。广播表的查询性能较好,但存储空间和写入性能相对较差。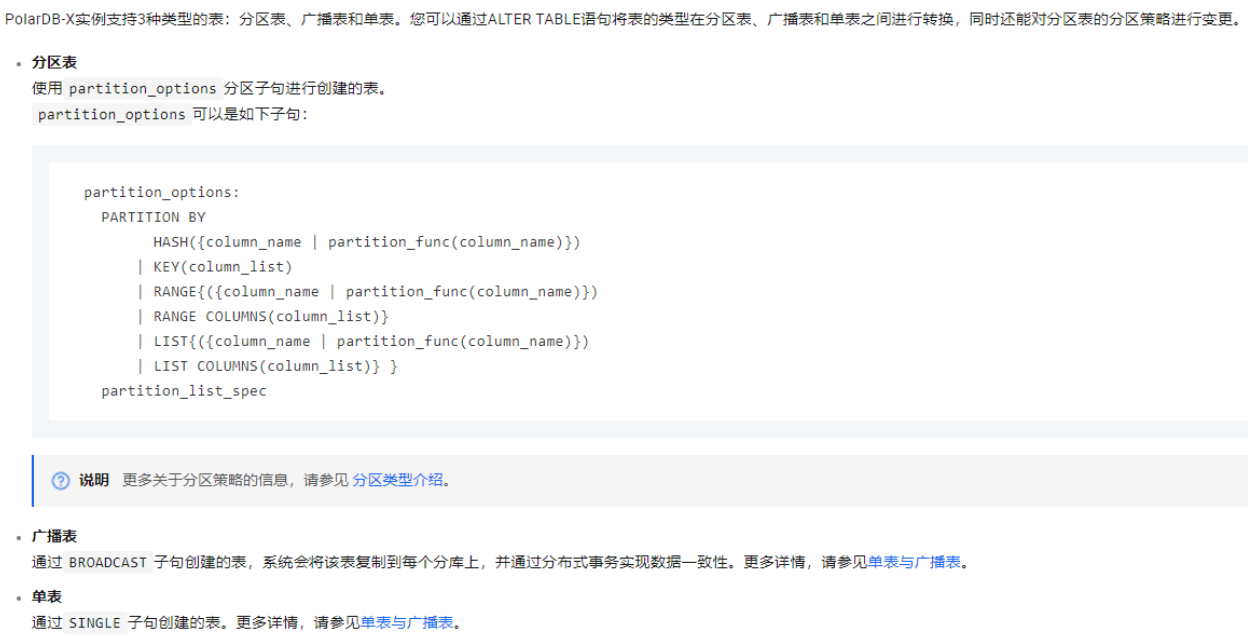
分区表将表的数据按照用户定义的分区键进行划分,每个分区存储在不同的节点上。分区表适用于大数据量的查询和高并发的写入,具有更好的存储空间和写入性能,但查询性能相对较差。
因此,选择广播表还是分区表要根据实际场景和需求来进行选择。
PolarDB 中的广播表(Broadcast Table)和分区表(Partition Table)是两种不同的数据存储方式,它们的主要差别和体现在以下几个方面:
PolarDB分区表完全兼容原生MySQL的语法和功能。同时,PolarDB分区表相对于原生MySQL进行了性能增强,支持丰富的分区类型及组合,使您可以更加便捷、简单和高效的使用分区表。
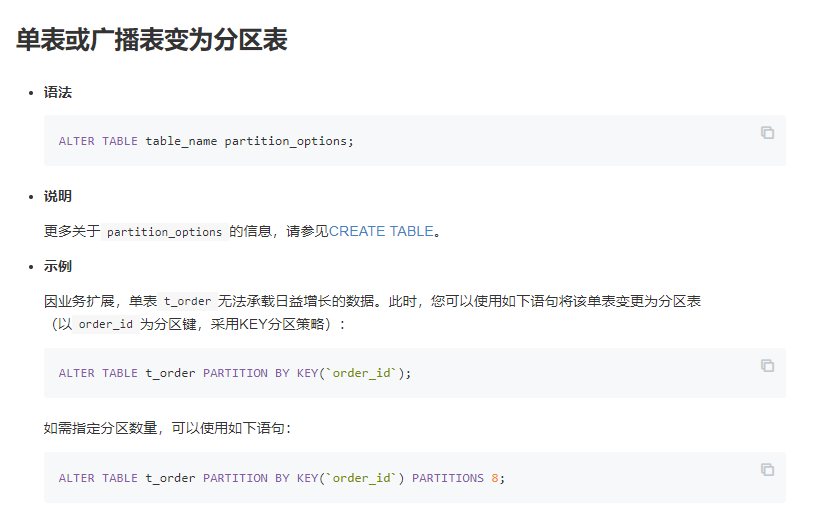
分区表是将一个大的逻辑表,按照分区规则分割成多个小的物理表, 大的逻辑表为分区表,小的物理表为分区,每一个分区在存储引擎上独立组织管理数据和索引。分区规则主要包括RANGE、LIST、HASH三种,您需要指定分区键, 根据分区键字段的值按照这三种规则把数据划分到不同的分区。PolarDB还支持创建混合分区,可以将每个分区放在不同的存储引擎上。Orders表做二级分区的示意图如下: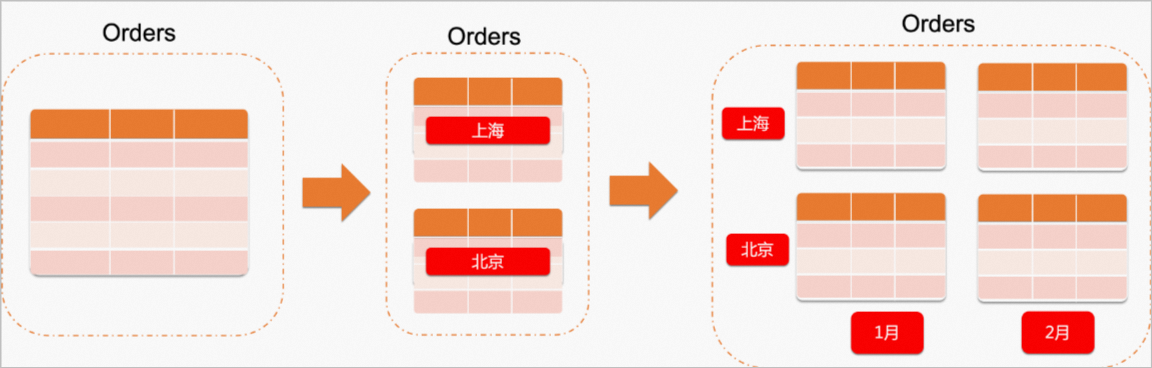
优势如下: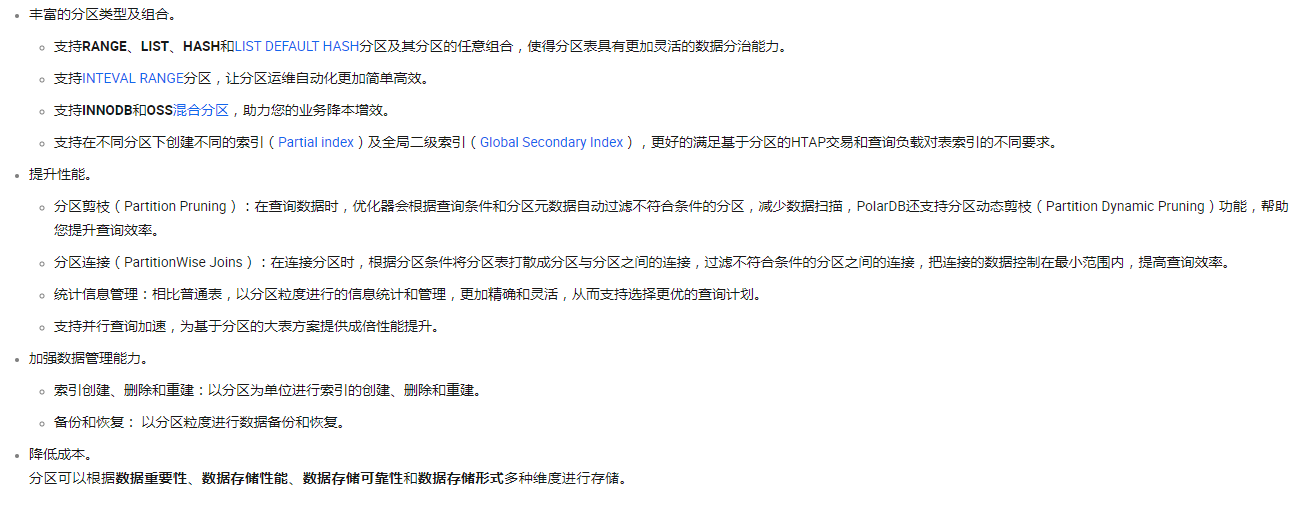
广播表是指将这个表复制到每个分库上,在分库上通过同步机制实现数据一致,有秒级延迟。这样做的好处是可以将JOIN操作下推到底层的RDS(MySQL),来避免跨库JOIN。
CREATE TABLE brd_tbl(
id bigint not null auto_increment,
name varchar(30),
primary key(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;
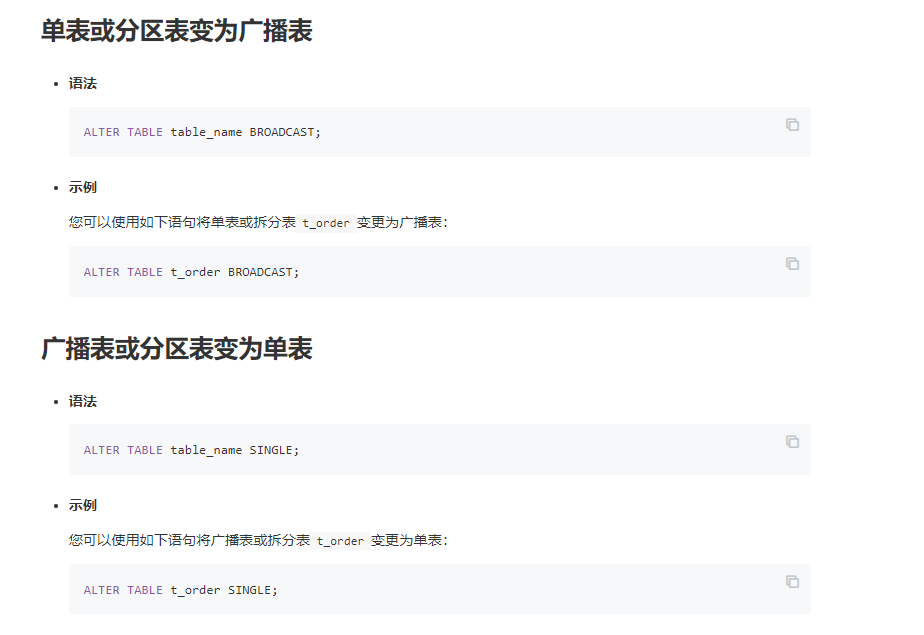
PolarDB支持广播表和分区表两种不同的数据分布方式。
广播表(Broadcast Table):
分区表(Partitioned Table):
主要体现在以下方面:
选择广播表还是分区表要取决于具体的业务需求和数据特征。广播表适用于数据量较小、对查询性能要求较高的场景;而分区表适用于数据量较大、需要水平扩展和灵活查询的场景。
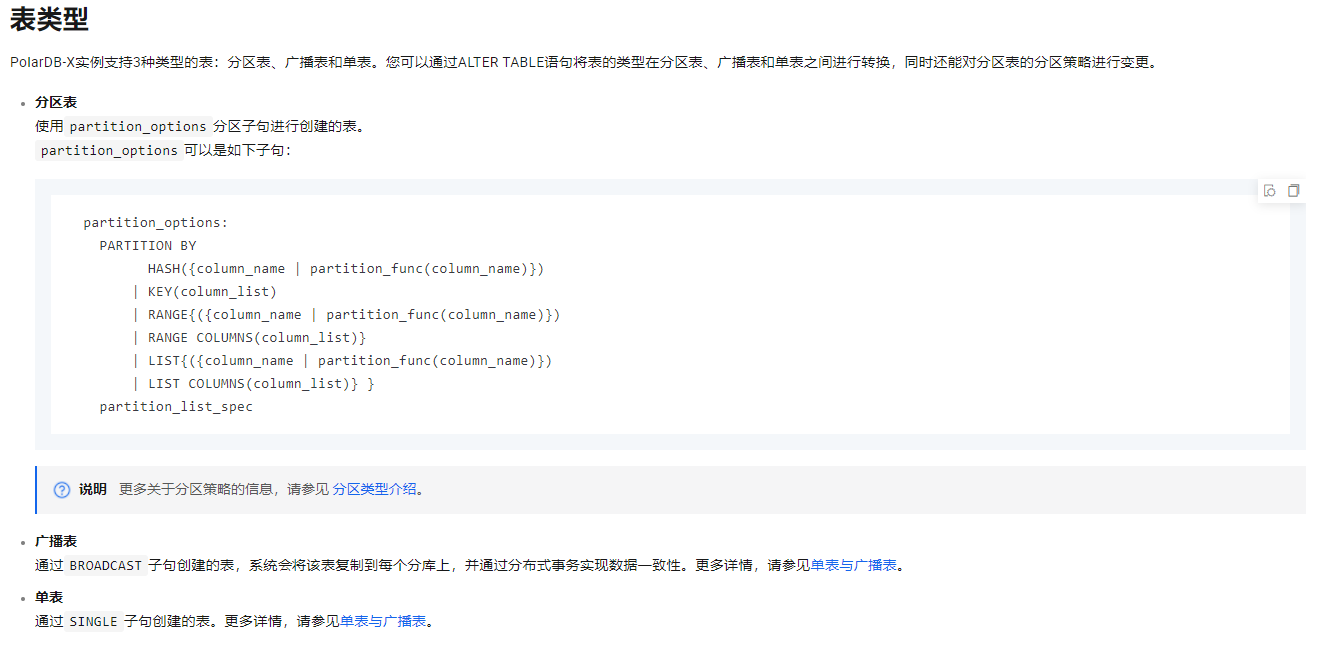
PolarDB 广播表和分区表是两种不同的表设计方式,主要体现在以下几个方面的差异:
数据存储方式:
数据访问效率:
存储空间利用率:
数据的一致性和容错性:
广播表和分区表的选择取决于具体的业务需求和数据访问模式。如果数据量较小、并发性能较重要,可以考虑使用广播表;如果数据量较大、查询性能和存储空间利用率较重要,可以考虑使用分区表。同时,在设计和选择表类型时,还需要综合考虑系统的容错性和一致性需求。
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


