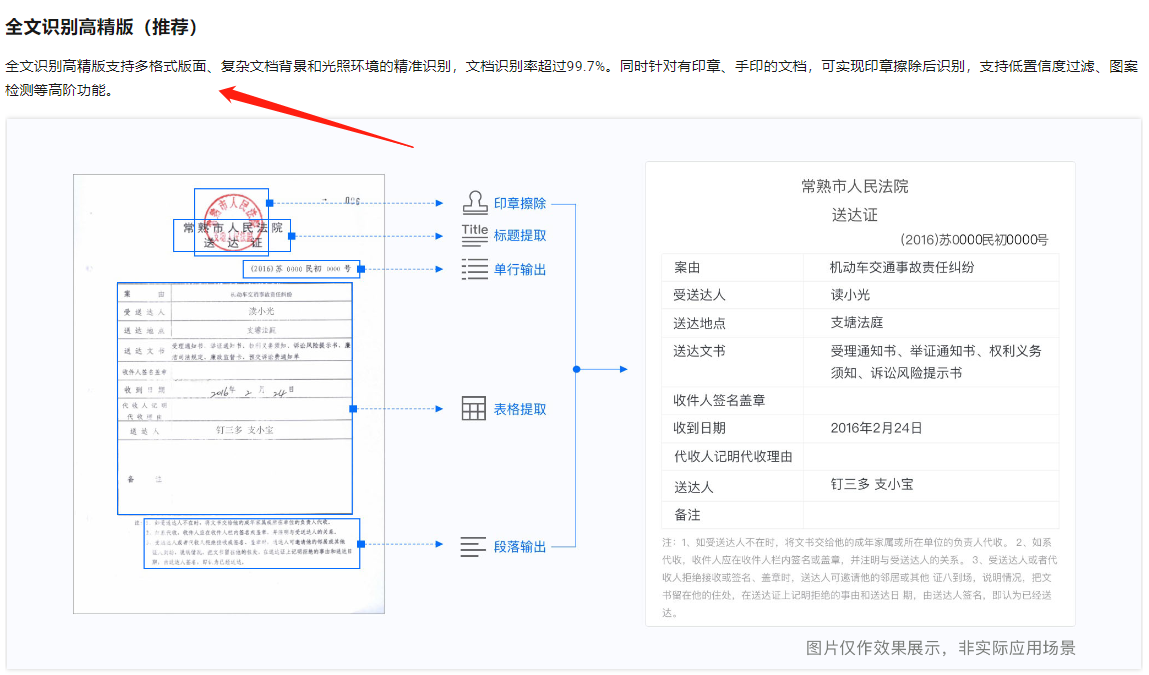
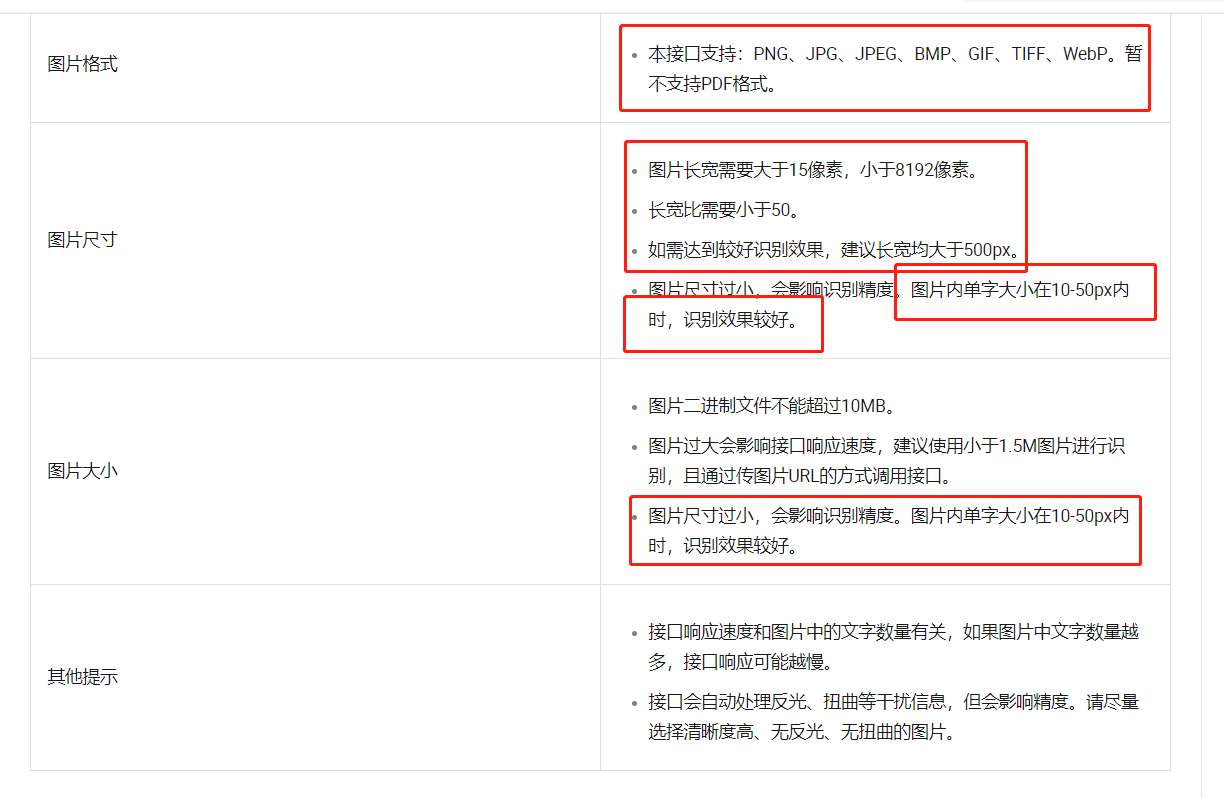
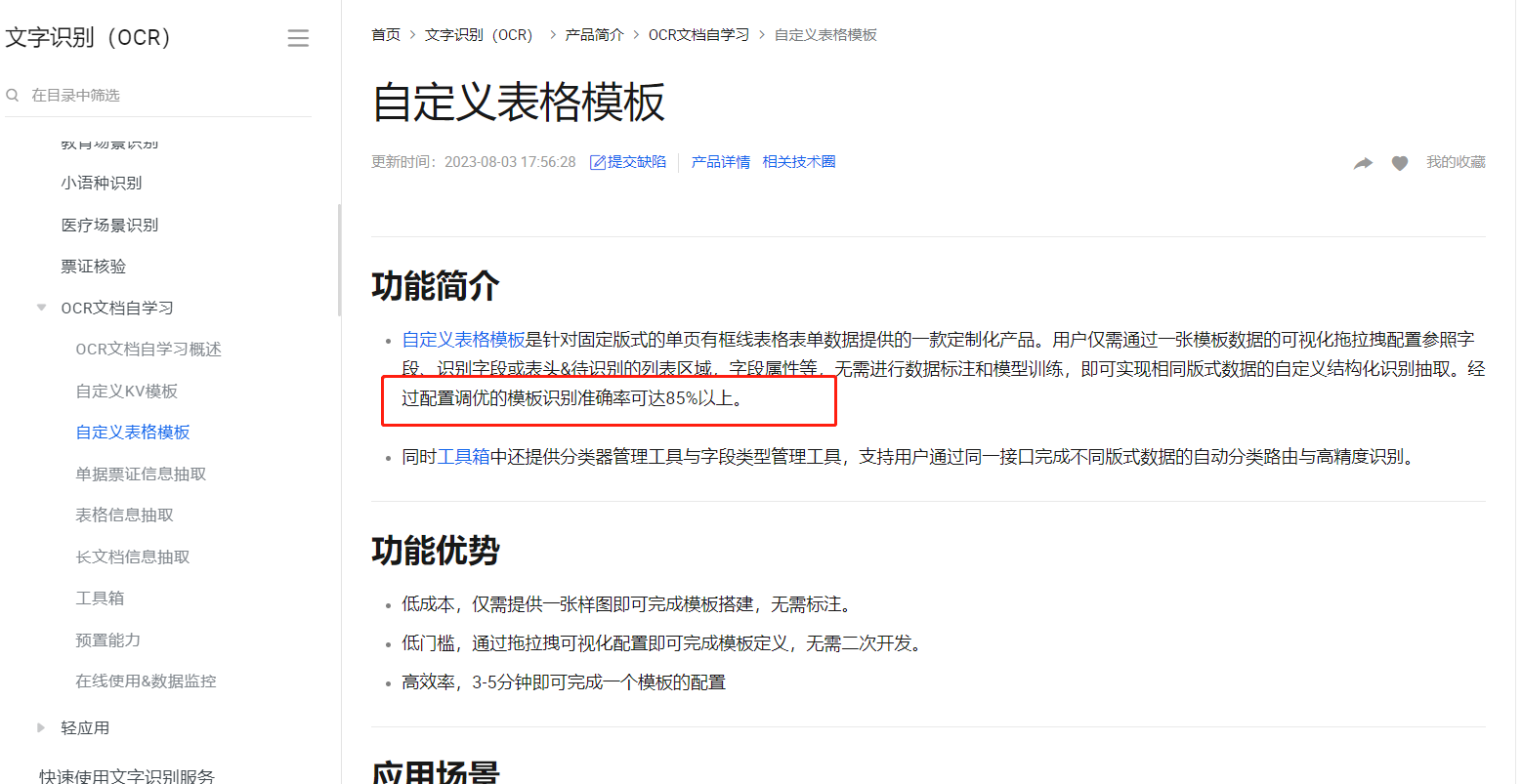
文字识别OCR这个c识别成了e,怎么解决?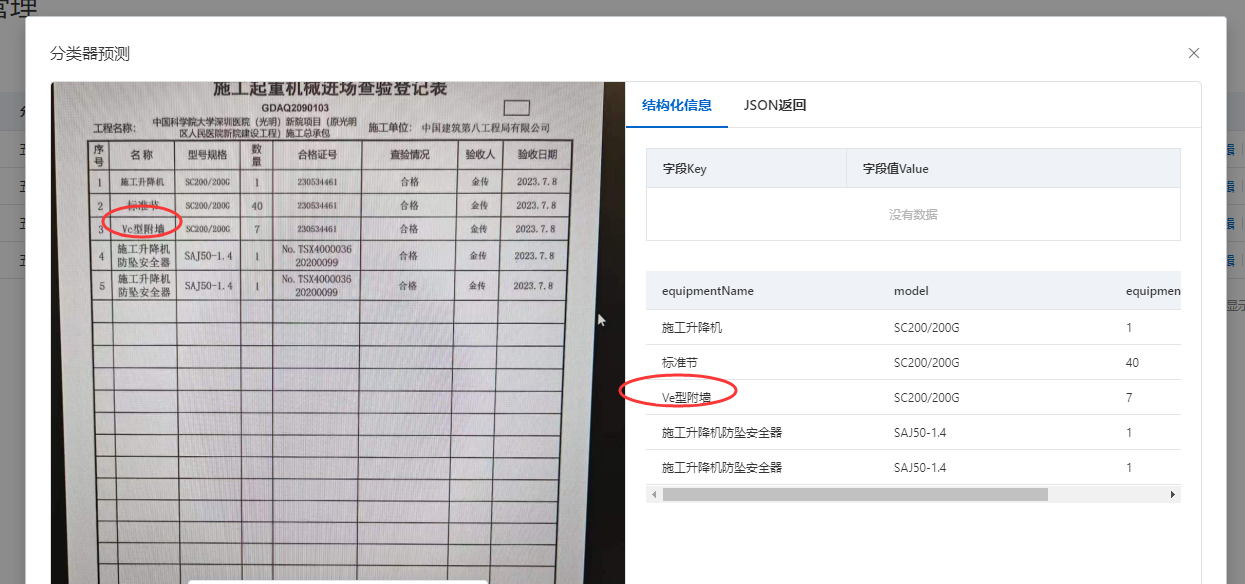
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
调整识别参数:您可以尝试调整识别参数,例如调整识别精度、调整识别区域等,以改善识别效果。
校准识别模板:如果您使用的是基于模板的OCR识别,可以尝试校准识别模板,以减少误识别的概率。
重新训练模型:如果以上两种方法都无法解决问题,您可以考虑重新训练OCR模型。阿里云提供了重新训练模型的接口,您可以根据接口文档进行操作。
联系客服:如果您无法解决问题,可以联系阿里云的客服人员,寻求帮助。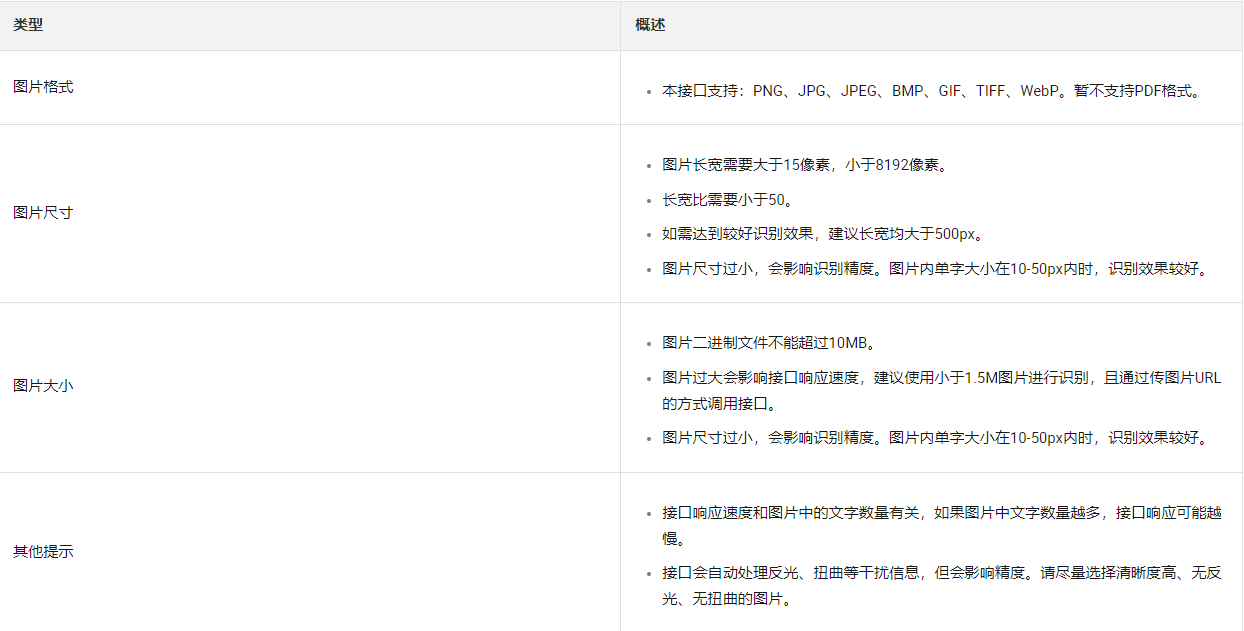
文字识别OCR将字符 "c" 误识别为 "e" 是一个常见的问题,可能由于字体、图像质量、预处理等因素导致。以下是一些可能的解决方案:
改善图像质量:
图像预处理:
使用适当的OCR引擎和设置:
自定义训练:
后处理和纠正:
人工审核:
识别OCR将"c"识别成了"e",可能是由于以下几个原因导致的:

字体相似性:某些字体的"c"和"e"可能在形状上非常相似,使得OCR算法难以准确区分。特别是当字体模糊、扭曲或存在细微差异时,识别错误的可能性会增加。
上下文语境:有时,基于图像中其他字符或单词的上下文语境,OCR算法可能会错误地将"c"识别为"e"。这种情况下,整体的上下文信息可能对OCR的结果产生影响。
要解决OCR将"c"识别为"e"的问题,您可以尝试以下方法来提高准确性:
优化图像质量:确保输入图像的清晰度和对比度,减少模糊和噪点。这可以通过合适的光线条件、摄像设备和图像处理技术来实现。
选择更具区分度的字体:选择字体时,尽量避免那些"c"和"e"之间形状相似度很高的字体。选择清晰、易于区分的字体能够提高OCR的准确性。
使用自定义字体模型:根据您的需求和特定场景,可以尝试创建自定义字体模型,训练OCR算法以更好地识别"c"和"e"。这需要一些额外的工作和数据来训练和优化模型。
后处理和校正:在OCR结果中,可以使用后处理和校正技术对错误的识别进行修正。例如,可以利用语言模型或规则匹配来验证结果,并进行必要的纠正。
如果阿里云文字识别 OCR 将 "c" 识别成了 "e",您可以尝试以下方法解决问题:
检查识别文本:首先,检查阿里云 OCR 返回的识别文本结果,确保问题确实是由 OCR 引起的,而不是其他环节的误解。通过输出日志或调试工具查看 OCR 返回的文本结果。
调整图像参数:OCR 的识别结果受到图像质量的影响。您可以尝试调整图像的清晰度、对比度、亮度等参数,以获得更好的识别结果。可以尝试使用图像处理算法或工具对图像进行预处理,提升图像质量。
校正后处理:如果 OCR 识别出的结果确实存在误判,您可以考虑在识别结果上进行后处理和校正。可以使用规则引擎或编写自定义逻辑来校正 OCR 识别结果中的错误字符。例如,将 "e" 替换为 "c"。
使用自定义字典:阿里云 OCR 支持自定义字典功能,您可以创建一个包含特定词汇和字符的字典,并与 OCR 一起使用,以优化识别结果。在您的场景中,您可以将 "c" 添加到自定义字典中,以帮助 OCR 正确识别。
楼主你好,如果阿里云文字识别OCR识别出的字符错误,您可以通过以下方式尝试解决:
优化图片质量。OCR技术对图片质量要求较高,如果图片质量不好,识别结果可能会出错。因此,您可以尝试优化图片质量,比如调整图片亮度、对比度、清晰度等。
换用其他OCR识别引擎。如果阿里云文字识别OCR识别出的字符错误比较严重,您可以尝试换用其他OCR识别引擎,比如百度OCR、腾讯OCR等。
使用OCR识别API提供的参数调整接口。阿里云文字识别OCR提供了一些参数调整接口,您可以尝试通过调整接口参数来提高识别准确率。
最后,试试这个: