
新增一条数据,要等个几分钟报表数据才能同步,应该是后台异步计算的,有啥介绍嘛,是用的 Flink 还是啥技术?计算完数据是存在 mysql/hollow 里面?报表所有数据计算完都单独存一份,不会吃不消嘛。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
宜搭报表使用了流式计算引擎 Flink 作为其后台的计算框架。Flink 是一个开源的分布式流处理和批处理计算框架,具有高吞吐量、低延迟和容错性等特点,非常适合处理实时数据流。
至于您提到的新增一条数据要等几分钟才能同步的问题,这可能是因为宜搭报表使用了异步计算的方式,所以新增一条数据后需要等待一段时间才能在报表中看到最新的数据。
根据你的描述,这个系统可能采用了异步计算的技术来处理数据,并使用某种数据库来存储报表数据。但是,你没有提供足够的上下文信息来确定具体的技术栈。以下是一些可能的解决方案和技术:
Flink:Apache Flink 是一个用于处理无界和有界数据的流处理框架。它可以用于实时数据流的处理,以及批处理数据的处理。如果这个系统需要处理实时数据流,并生成实时报表,那么使用 Flink 是可能的解决方案。 Hadoop/Spark:Apache Hadoop 和 Apache Spark 都是用于大规模数据处理的框架。它们可以处理大量数据,并支持多种语言和数据源。如果这个系统需要处理大量历史数据,并生成报表,那么使用 Hadoop 或 Spark 是可能的解决方案。 MySQL/HBase:MySQL 是一种常用的关系型数据库,而 HBase 是一种分布式、可扩展的、面向列的存储系统,适用于存储大规模的结构化数据。如果这个系统需要存储大量的报表数据,那么 MySQL 或 HBase 都是可能的解决方案。 数据重复存储:对于报表数据,如果每个数据都需要单独存储一份,那么可能会面临存储空间的问题。在这种情况下,可以考虑使用数据压缩和归档技术来减少存储空间的使用。此外,还可以考虑使用数据库的索引和查询优化技术来加快数据的查询速度。
综上所述,根据你的具体需求和技术栈选择合适的解决方案是很重要的。如果你能提供更多的上下文信息,我可以为你提供更具体的建议。
宜搭报表使用的计算框架是 Apache Flink。宜搭的后台计算是通过后台异步计算完成的,数据变更会发送到 Flink 进行实时计算和聚合。计算完成后,报表数据通常会存储在分布式数据库(如MySQL)或内存数据库(如Hollow)中,以便在需要时快速检索和呈现报表数据。
这种架构的好处是,计算过程和存储是分离的,可以通过水平扩展和分布式计算来应对大规模的数据计算需求。同时,存储在数据库中的报表数据可以通过索引和查询进行高效访问。
当然,具体的实现可能因为系统架构和需求而有所不同,以上只是一种常见的设计模式。如果您需要更详细的信息,建议您查阅宜搭官方文档或咨询宜搭客服团队。
宜搭报表使用的计算框架是 Flink。Flink 是一个流处理框架,可以处理实时和批处理数据流,并且支持分布式计算和容错处理。在宜搭报表中,当新增一条数据时,数据会被发送到 Flink 集群进行处理和计算。
至于数据存储方面,我没有找到相关信息。但是,一般来说,如果报表数据量很大,单独存一份可能会导致性能问题。因此,通常会采用一些优化手段来提高查询效率,例如索引、分区等。
据我所了解,宜搭报表是一个数据分析和可视化平台,可以帮助用户通过简单的拖拽操作生成自定义的报表。关于宜搭报表的具体实现细节,我不清楚其内部使用的具体计算框架,因为该信息可能并不公开或者是公司内部的商业机密。所以,我无法确定宜搭报表后台异步计算部分使用的具体技术,比如Flink。
一般情况下,后台异步计算报表数据可能会选择使用实时流处理框架,例如Flink、Spark Streaming等。这些框架可以帮助实现高吞吐量、低延迟的数据处理和计算。
至于数据存储方面,常见的方式是将计算完的报表数据存储在关系型数据库(如MySQL)或者其他高性能的存储引擎中。当然,也可以根据业务需求选择适合的存储方案,例如Hadoop、Hive、HBase、Elasticsearch等。
为了保障性能和可扩展性,可能会采用分布式存储和计算架构,将数据存储在多个节点上,以提高数据读取和查询的并发能力。
楼主你好,根据我所知道的信息,宜搭报表使用的是 Apache Flink 技术进行实时计算。新增数据会被异步发送到 Flink 集群进行实时计算,计算完的结果会存储到指定的存储介质(例如 MySQL、HBase 等)。报表数据会从计算结果中读取,进行聚合统计等操作,而不是单独存储一份数据。这种方式可以避免重复存储数据所带来的资源消耗和存储空间浪费。同时,由于 Flink 支持实时计算,宜搭报表可以实现秒级响应和实时更新报表数据的功能。
宜搭报表使用的是阿里云FusionInsight MRS计算框架。
宜搭报表可以与单据页面进行联动,应用制作者通过单据页面收集到用户数据后,便可以用作制作报表页面的图表。宜搭还提供了三种筛选器组件,筛选器的数据联动有如下几个特点:当图表的数据与筛选器的数据相同时,默认触发联动;当图表与筛选器的数据绑定不相同时,需要人工绑定"跨cube联动设置";筛选器与筛选器之间的数据集相同,默认都不会发生联动,需要人工配置联动(暂不支持不同数据集联动)。
你好,宜搭的核心存储随着用户量的增大,一直在调整,存储有ADB和Hologres,对于不的用户级别存储方式也是不一样的。
宜搭报表使用了 Flink 作为计算框架,并在新增数据时进行后台异步计算,将计算结果存储到数据库中。结合后台异步计算和数据库存储,可以有效地实现报表数据的生成和管理,提供实时性和可靠性,同时支持复杂的数据处理和查询需求。这种架构有助于为用户提供准确、及时的报表数据。
宜搭报表使用的计算框架是 Flink。Flink 是一个流处理框架,可以处理实时和批处理数据流,并且支持分布式计算和容错处理。
在宜搭报表中,当新增一条数据时,数据会被发送到 Flink 集群进行处理和计算。Flink 会使用分布式算法来计算报表数据,并将计算结果存储到数据库中,例如 MySQL 或 Hollow。
在计算完数据后,Flink 会将数据存储在数据库中,而不是单独存储一份。这样可以有效地利用数据库的存储空间,并且可以方便地进行数据查询和分析。
数据同步:新增的数据会被同步到宜搭报表的数据存储系统中,通常是使用 MySQL 或 Hollow 进行数据存储。这些数据存储系统用于持久化数据,并提供高效的数据查询和处理能力。
计算引擎:宜搭报表使用 Flink 作为计算引擎,利用其流式处理和批处理的能力来执行报表数据的计算。Flink 具有高吞吐量、低延迟和容错性等特点,适用于处理实时和批量的大规模数据。
异步计算:宜搭报表将新增数据作为输入,通过 Flink 进行异步计算。这意味着报表数据的计算不是立即发生,而是在后台异步进行。因此,您可能需要等待几分钟或更长时间,以便计算完成并将结果更新到报表中。
报表数据存储:计算完的报表数据会存储在指定的数据存储系统中,例如 MySQL 或 Hollow。这些数据存储系统通常会优化数据的读取和查询性能,以便提供快速的报表数据展示和访问能力。
宜搭报表使用了流式计算引擎 Flink 作为其后台的计算框架。Flink 是一个开源的分布式流处理和批处理计算框架,具有高吞吐量、低延迟和容错性等特点,非常适合处理实时数据流。
当新增一条数据时,宜搭报表会将该数据传输至 Flink 计算引擎进行异步计算。具体的计算过程可能涉及数据聚合、转换、过滤等操作,以生成报表所需的结果。计算完数据后,生成的报表结果可以存储在不同的持久化存储中,如 MySQL 或 Hollow。
关于报表数据的存储方式,具体的实现取决于宜搭报表的架构和配置。可能会根据数据规模、查询性能要求等因素来选择适当的存储方案。如果报表数据量较大,可以采用索引优化、分区划分等技术手段来提高查询性能。此外,使用缓存或者利用列存储等技术也可以进一步提升数据读取效率。
需要注意的是,报表系统通常会经过预先定义的计算逻辑对源数据进行处理,并将处理结果进行存储。这样做的目的是为了提供更快速和高效的报表查询。然而,数据存储的冗余性和资源消耗也是需要考虑的因素。具体的设计和优化策略可能会因应用需求而有所不同。
宜搭报表没有采用特定的计算框架
宜搭报表的数据一般来自于"单据页面",应用制作者通过单据页面收集到用户数据后,便能用作制作报表页面的图表
多表关联不生成具体的物理表,数据实时更新
数据准备是离线数据,数据更新周期T+1
数据准备会提供更多的加工能力,例如允许用户进行跨应用数据关联
宜搭平台是以表单模型驱动的泛业务场景的SAAS平台。
报表提供各式各样的图表组件,可根据自己需求选取组件进行数据展示以及分析。
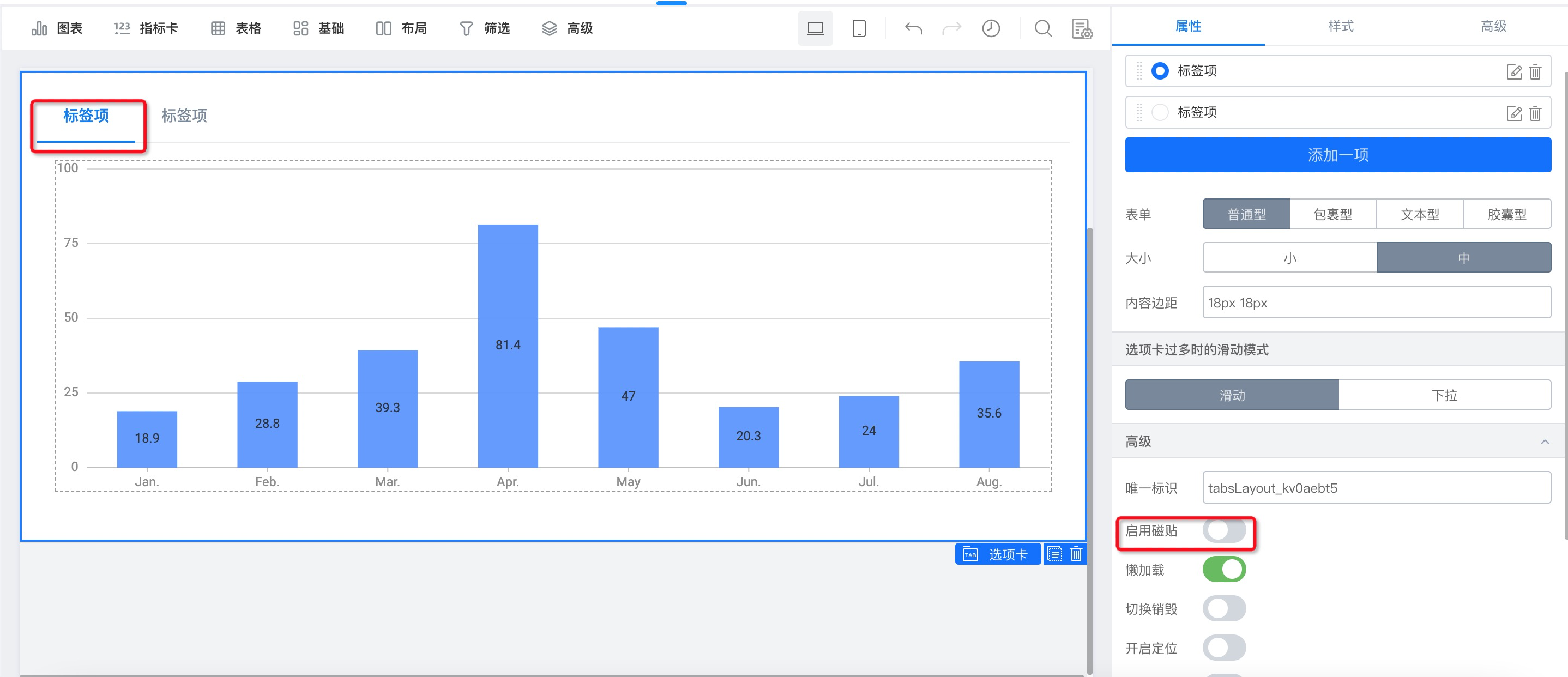
3.0宜搭报表默认对每个组件支持磁贴拖拽,方便快速对图表的宽高及位置进行即时设置。但当要配合多层的容器组件嵌套使用时(例如tab页、分栏、容器等),为了提高页面的性能,推荐将外层的容器的磁贴开关关闭,以提高报表整体的加载性能。
3.0 报表中提供了多种样式的图表,可以通过明细表、数据透视表等查看表单/流程表单数据的明细和汇总;通过柱形、折线、图形、等对数据进行处理,显示出数据的发展趋势、分类对比等结果;通过饼图体现数据中每个部分的比例。
在宜搭报表 3.0 的表格上,你可以不仅仅展示数据,还可以实现【动态下钻】、【显示行序号】等功能,还可以对样式进行灵活的调整,是一个非常强大的可视化数据工具。
目前上线了宜搭报表“跨应用取数”。即老的应用不用动,里面的表单可以继续使用,但是在新应用里取老应用的数据,在新应用里做报表。
宜搭报表用的是宜搭云



