
PolarDB为什么执行SET GLOBAL max_parallel_degree=32,返回错误,怎么才能开启并行查询?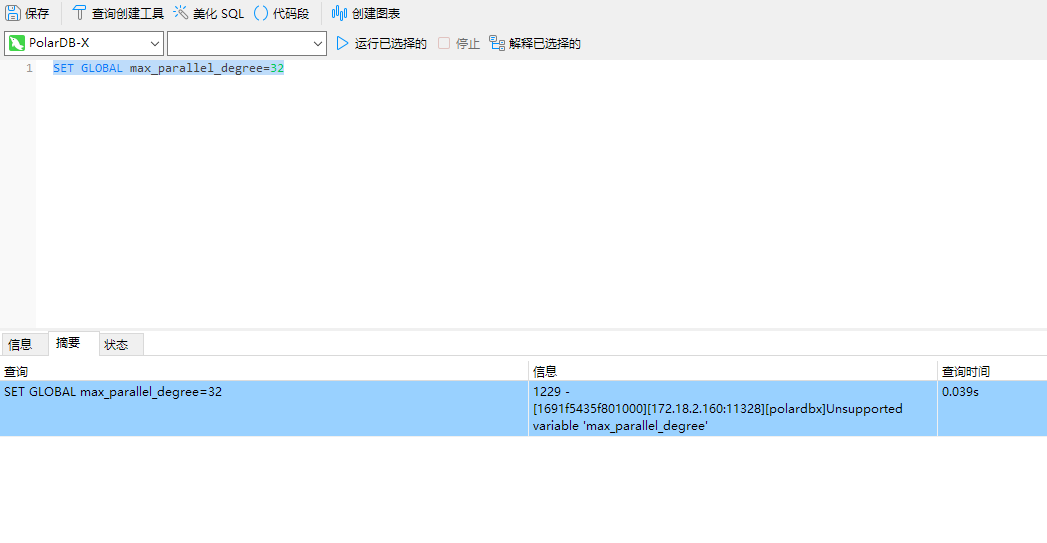
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,执行SET GLOBAL max_parallel_degree=32命令可能会返回错误,因为PolarDB不支持修改max_parallel_degree参数。PolarDB默认使用最大并行度,因此不需要手动设置此参数。
如果您想要进一步优化并行查询的性能,可以考虑以下几点:
索引可以帮助数据库快速定位数据,从而提高查询效率。在使用并行查询时,合理使用索引可以进一步提高查询性能。
并行查询需要将数据分配到多个CPU核心上进行处理,如果存在大量的临时表,则会导致数据分散在不同的节点上,降低并行处理的效率。
并行查询的效率取决于任务的切分粒度和并行度的设置。因此,在应用中,需要根据实际情况合理设置查询任务的切分粒度和并行度,以达到最佳的查询效果。
全表扫描会导致所有数据都被读入内存,降低查询效率。因此,在使用并行查询时,尽量避免全表扫描,可以通过合理使用索引和优化查询语句等方式实现。
错误信息提示 "Unsupported variable 'max parallel degree'" ,表明您尝试设置的变量 "max_parallel_degree" 在 PolarDB 中是不支持或者未找到的。
PolarDB 作为一款基于 InnoDB 存储引擎的分布式数据库,确实支持并行查询,但是其并行查询的配置和 MyISAM 引擎有所不同。在 PolarDB 中,您需要使用 "max_threads" 变量来控制并行查询的最大线程数。
要开启并行查询,您可以执行以下命令:
SET GLOBAL max_threads = 32;
CopyCopy
这里将最大线程数设置为 32。请注意,这个数值需要根据您的具体环境和硬件配置进行调整,以避免过度消耗系统资源。
然后,您需要重启 PolarDB 服务,让更改生效。
PolarDB-X没有这个参数,PolarDB MySQL版本打开并行查询功能时, 需要设置innodb_adaptive_hash_index参数为OFF,innodb_adaptive_hash_index参数开启会影响并行查询的性能。
如果控制台页面未开启并行查询,但系统参数max_parallel_degree被设置为大于0时,相当于默认开启了单机并行。
如果控制台和系统参数max_parallel_degree均有设置,则以控制台参数配置为准,故建议使用控制台开启并行查询。
测试用的PolarDB集群规格为32核256 GB(独享规格)×4节点,单节点并行度max_parallel_degree分别设置为32和0,对比PolarDB串行执行、单节点32并行度执行、4节点128并行度执行的性能数据。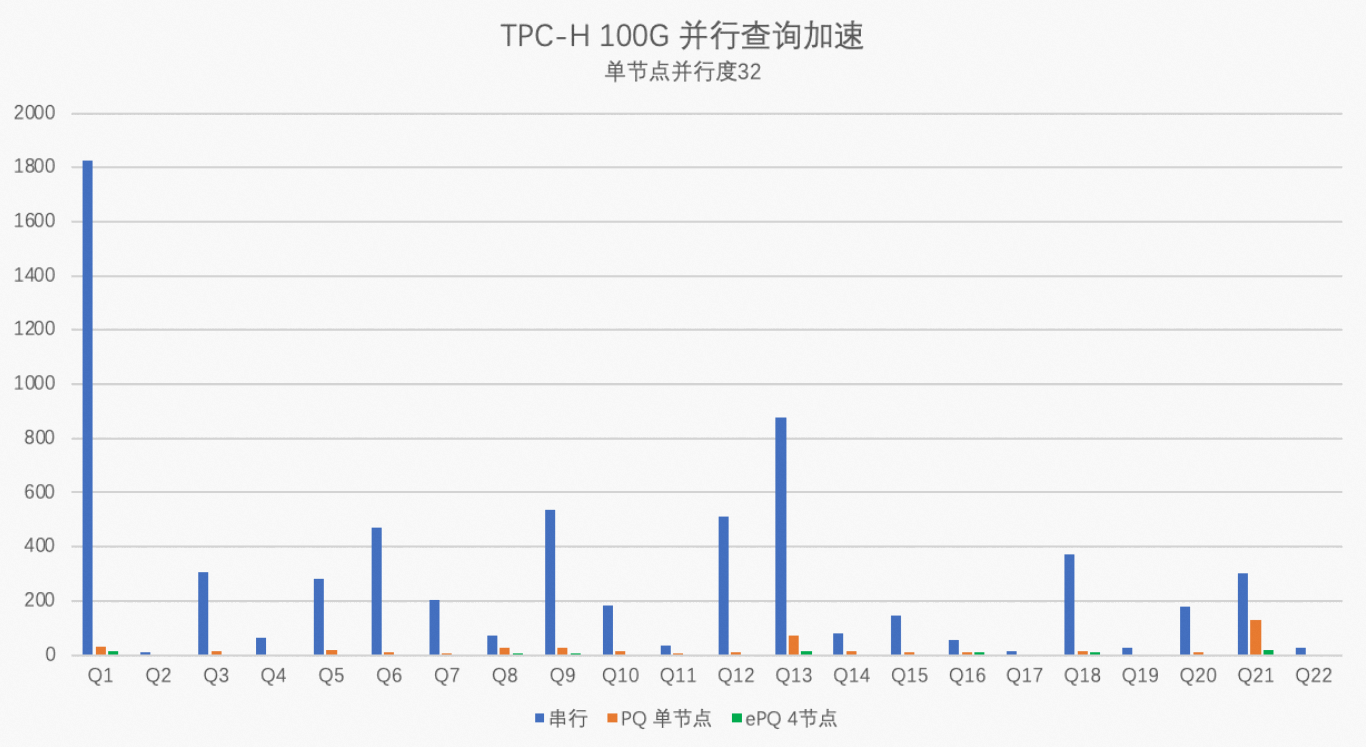
对于大数据量、较复杂的时空查询,Ganos可直接利用PG并行查询的能力从而加速时空查询。
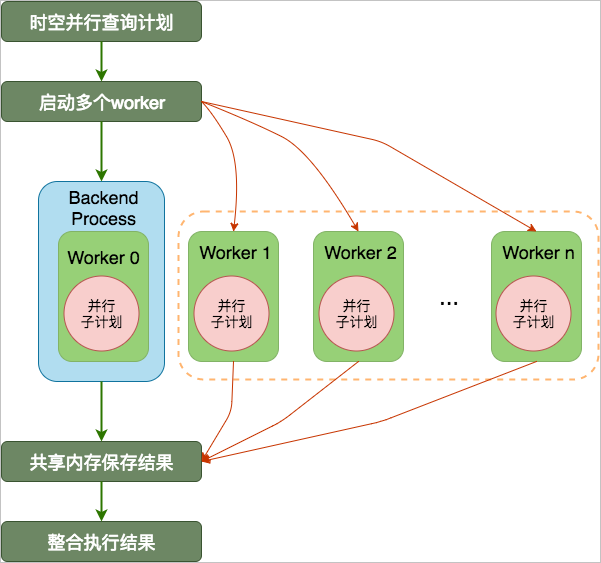
并行查询原理
PG并行查询是表级的并行,其并行查询示意图如下。
开启Ganos并行查询的方法如下:
修改PostgreSQL配置文件postgresql.conf,启用并行查询参数。
开启max_parallel_workers参数,设置能够开启的并行worker总数量,须小于max_worker_processes的值,通常为8-32。
开启max_parallel_workers_per_gather参数,设置单个查询gahter最大并行度,须小于max_parallel_workers的值,通常为2-4。
如果要开启强制并行,须将force_parallel_mode设置为on。
通过执行SQL语句控制单个表的并行粒度:alter table table_name set (parallel_workers=n)。
提高Ganos相关函数的cost成本。
在创建Ganos模块扩展时,通常默认有个函数cost成本,如果表数据量较小,但函数属于计算密集,并且适合开启并行执行,此时默认不会开启并行查询,需要提高函数的cost成本后才能开启并行查询。

如果您在PolarDB中执行SET GLOBAL max_parallel_degree=32时,返回错误,可能是由于以下原因:
系统资源不足:如果您的PolarDB实例的系统资源不足,例如CPU、内存、磁盘等资源不足,可能会导致无法开启并行查询。您可以检查系统资源的使用情况,如果资源不足,可以考虑升级硬件或扩容。
数据库版本不支持:如果您的PolarDB实例的版本不支持并行查询,可能会导致无法开启并行查询。您可以检查PolarDB实例的版本,如果版本不支持并行查询,可以考虑升级PolarDB实例的版本。
参数设置错误:如果您的PolarDB实例的参数设置错误,可能会导致无法开启并行查询。您可以检查PolarDB实例的参数设置,确保参数设置正确。
如果您已经排除了以上原因,但仍然无法开启并行查询,可以尝试使用以下命令重启PolarDB实例:
sudo systemctl restart polardb
这个命令将重启PolarDB实例,重新启动后,您可以再次尝试执行SET GLOBAL max_parallel_degree=32命令,看看是否能够开启并行查询。
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


