
在文字识别OCR这种图片,我创建了模板,但是识别效果不行,该如何改进?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,如果您在阿里云文字识别OCR创建了模板,但是识别效果不佳,可以尝试以下方法进行改进:
调整模板:检查模板的设置是否正确,包括区域位置、大小、颜色等是否准确,可以尝试重新设计模板。
调整图片:检查待识别图片的质量是否良好,包括分辨率、光照、角度等是否合适,可以尝试对图片进行处理,如裁剪、调整亮度、对比度等。
增加样本:如果模板的样本较少,可以尝试添加更多的样本,以提高识别的准确率。
修改算法:如果以上方法都无法改进识别效果,可以尝试使用其他算法,如深度学习等进行识别,或者调整算法的参数等。
图片质量优化:确保图像质量良好。清晰、高分辨率的图像通常能提供更好的识别结果。确保图像没有模糊、光照不足、倾斜或变形等问题。可以尝试使用图像处理工具对图像进行增强、去噪或调整亮度/对比度。
适当的裁剪和对齐:根据模板的要求,裁剪和对齐图像,使需要识别的文本区域尽可能清晰且居中。避免包含无关的图像或干扰物。
字体和字号匹配:确保模板中使用的字体和字号与要识别的文本相匹配。OCR系统在识别时需要准确匹配字体形状和大小。
文本区域标注:在模板中明确定义文本区域。使用框或多边形标注要识别的文本区域,以帮助OCR系统准确地定位和识别文本。
多样性数据集:如果模板的识别效果受限于特定类型的图像,尝试使用更多样化的数据集来训练模板。包括不同字体、大小、颜色、背景和布局的图像,以提高模板的适应性。
改进手写表格的文字识别OCR效果需要考虑以下几个方面:
数据预处理:对于手写表格,首先需要进行适当的图像预处理。可以尝试应用图像增强、去噪、二值化等技术,以减少噪声并提高文字的清晰度和对比度。
模板设计:确保创建的模板与手写表格的特点和结构匹配。适当调整模板的布局和样式,包括行和列的数量、宽度、间距以及单元格大小等。根据表格的特点,可能需要考虑不同的行和列类型,如表头、数据行、合计行等。
字体和样式:对于手写文字,字体和样式的多样性较大,因此确保OCR系统熟悉并支持手写字体的识别。部分OCR服务提供商会有特定的手写字体识别功能,请选择适合手写文字识别的OCR服务或模型。
数据标注和训练:如果OCR服务支持自定义训练和优化,可以尝试使用手写表格的标注数据来训练OCR模型。这涉及到为手写表格提供足够数量和质量的样本,并进行模型调整和优化。
后处理和校正:对于OCR结果,可以应用后处理技术来进一步提升准确性。例如,使用文本校正、模板匹配、上下文理解等方法进行错误修复和结果验证。
持续优化:改进OCR效果可能需要持续的实验和调优过程。通过不断尝试不同的预处理方法、训练数据和后处理技术,以及针对特定表格样式的调整和优化,逐步改善识别结果。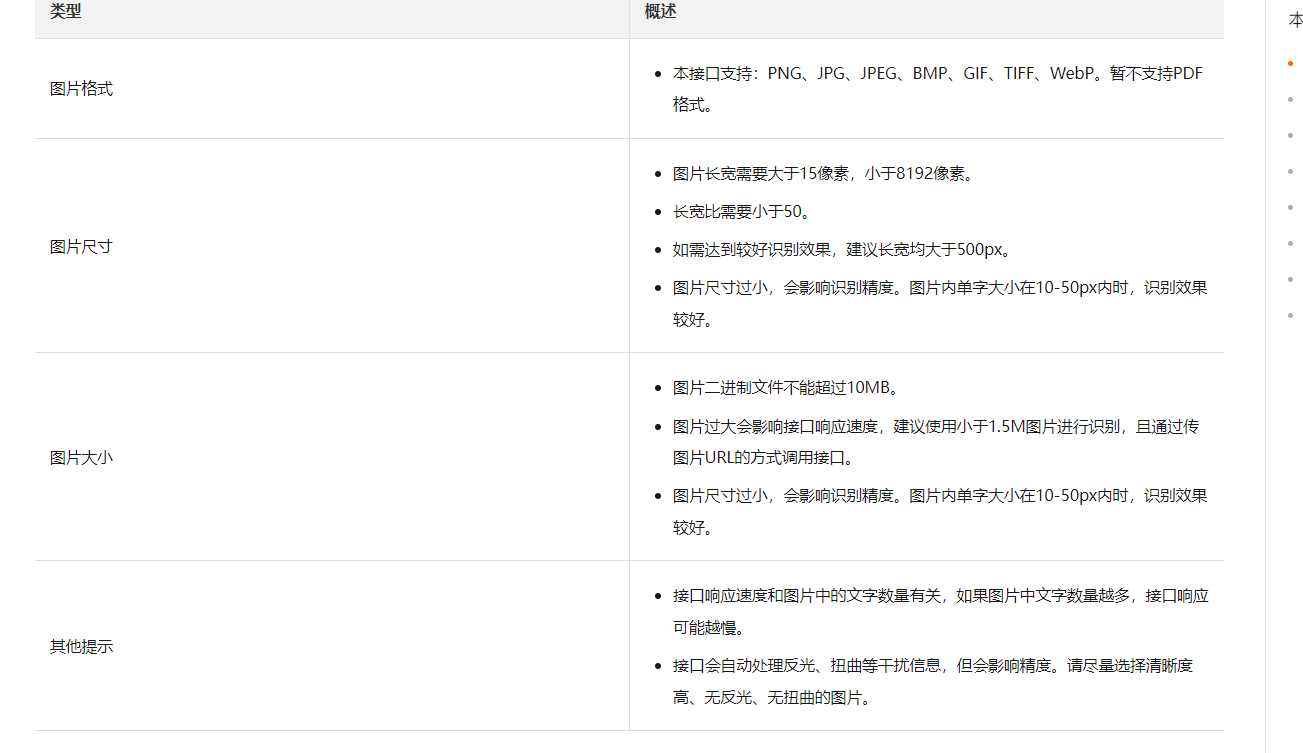

调整模板:根据OCR识别的结果,调整模板的大小、位置、角度等,以提高识别准确率。
增加模板:如果某些区域的文字无法被模板识别,可以增加相应的模板,以提高识别准确率。
调整参数:OCR技术需要一些参数来控制识别的效果,例如阈值、最小字体大小等,可以尝试调整这些参数,以提高识别准确率。
使用深度学习技术:深度学习技术可以提高OCR的识别准确率,例如卷积神经网络、循环神经网络等,可以尝试使用这些技术来改进OCR的识别效果。
你好,如果是用的是表格识别,可以尝试下面的方法提高图片识别率:
1、图片质量要求
2、模型训练
在图像质量较好情况下,通过100+训练样本标注,调优后模型识别准确率可超95%+
您好,文字识别OCR文档自学习表格信息抽取模型,如果想要提高识别准确率的话,首先您需要保证上传的表格图片满足以下条件:
1.单张图片最长边不超过8192像素,最短边不小于15像素。当长边超过1024像素时,长宽比不超过50 :1;
2.单字大小保持在10-50像素内,以获得较好的识别效果;
3.字迹清晰端正的数据能有更高的准确率。
另外模型训练至少准备20-30份以上同类任务的数据用于模型训练与评测,从而提高表格信息抽取的准确率。
您这边需要框选表格类型,分别标注表头和识别列,详情可以参考文档https://help.aliyun.com/document_detail/603349.html?spm=a2c4g.603351.0.0.15773f5dpgYJ6g#c45693bea17cl 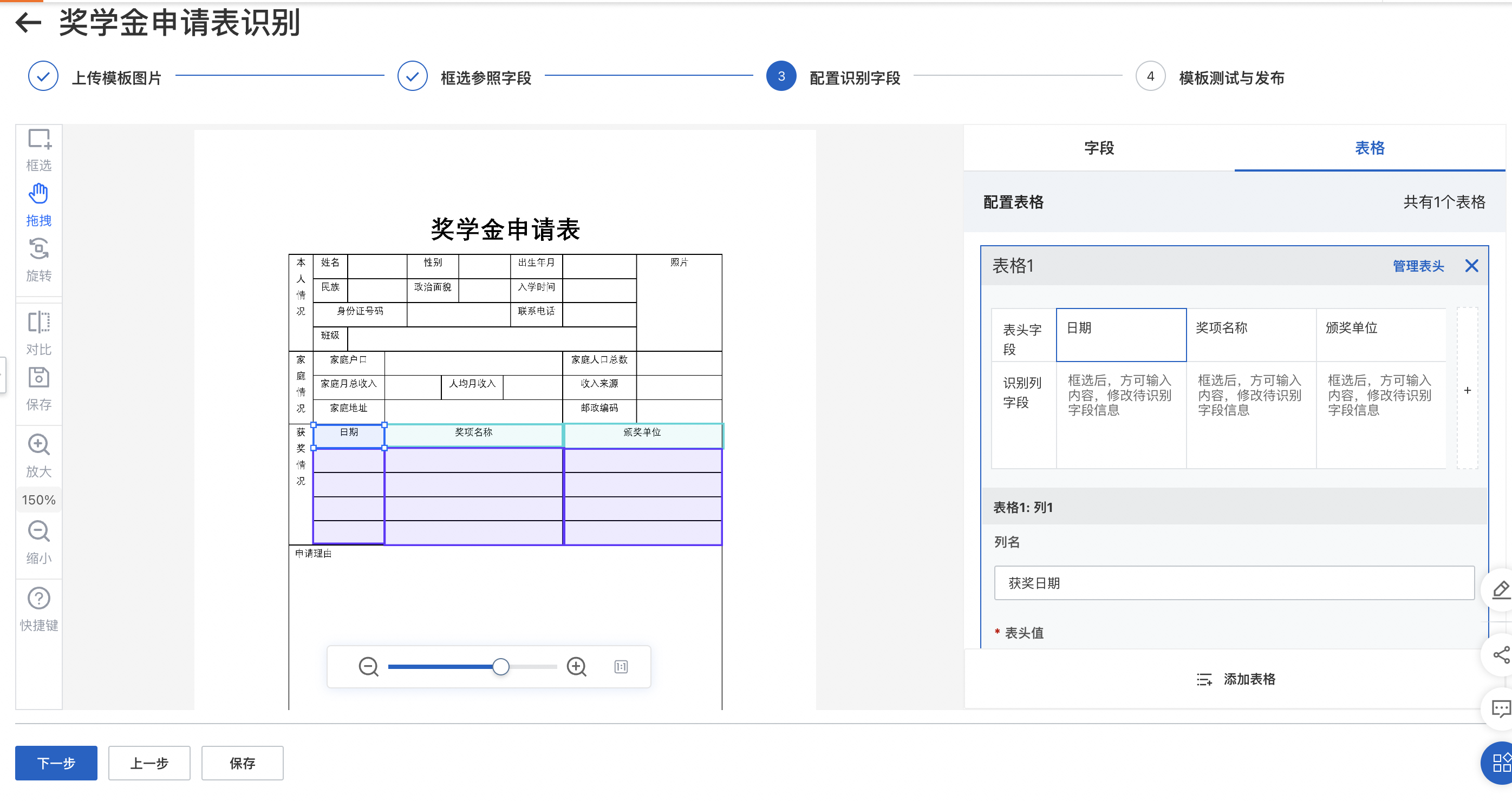
此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”




