
大佬们请问一下flinkcdc怎么同步oracle中的rowid?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC同步Oracle数据库中的数据时,可以通过以下步骤来同步Oracle中的ROWID:
确保在Oracle数据库中创建表时,指定了ROWID作为表的主键或唯一键。ROWID是Oracle数据库中每行数据的唯一标识符,它由数据库自动生成和维护。
在Flink CDC中,使用Table API或SQL API创建一个虚拟表,该表与Oracle数据库中的表结构相同,并包含ROWID列。
配置Flink CDC的Table Source,使其连接到Oracle数据库并捕获数据变更。确保在Table Source的配置中指定了要同步的表,并使用适当的连接字符串和认证信息连接到Oracle数据库。
在Flink CDC的Table Source配置中,启用ROWID同步。这可以通过在配置文件中设置相关参数或使用Flink API中的相关选项来实现。具体配置选项可能因Flink CDC版本和Oracle数据库版本而有所不同,请参考相关文档和示例代码以获取详细信息。
启动Flink CDC作业,并监视数据同步过程。通过查询虚拟表或查看Flink CDC的日志和监控指标,确保数据同步正在进行,并且ROWID列的值正在被正确同步。
需要注意的是,Flink CDC在同步Oracle数据库中的数据时,默认会捕获并同步ROWID列的值。然而,如果在Oracle数据库中对表进行了DDL操作(例如添加、删除或修改列),可能需要重新配置Flink CDC以适应新的表结构,并确保ROWID列的正确同步。
此外,Flink CDC的版本和Oracle数据库的版本可能会对同步ROWID的方式产生影响。在使用特定版本的Flink CDC和Oracle数据库时,请参考相关文档和示例代码以获取详细的配置指南和最佳实践。
在 Flink 中使用 Flink CDC 同步 Oracle 数据库中的数据时,并不直接支持同步 rowid 字段。Flink CDC 是通过监听 Oracle 数据库的 Redo Log 来获取数据变更,并将其转化为 Flink 的数据流。
但是,你可以通过在 Oracle 表中添加一个额外的字段来实现类似的功能。可以创建一个新的列,例如 ROWID,并在表中使用一个触发器来将 ROWID 字段设置为 ROWID 值。
以下是一个示例的 Oracle 表创建语句和触发器定义:
-- 创建表时添加 ROWID 字段
CREATE TABLE your_table (
id NUMBER,
name VARCHAR2(100),
rowid_value VARCHAR2(100)
);
-- 创建触发器,将 ROWID 字段设置为 ROWID 值
CREATE OR REPLACE TRIGGER your_trigger
BEFORE INSERT OR UPDATE ON your_table
FOR EACH ROW
BEGIN
:NEW.rowid_value := :NEW.ROWID;
END;
这样,每次有新的数据插入或更新时,触发器会将 rowid_value 字段设置为当前行的 ROWID 值。然后,你可以使用 Flink CDC 监听 your_table 表并将 rowid_value 字段作为数据的一部分进行同步。
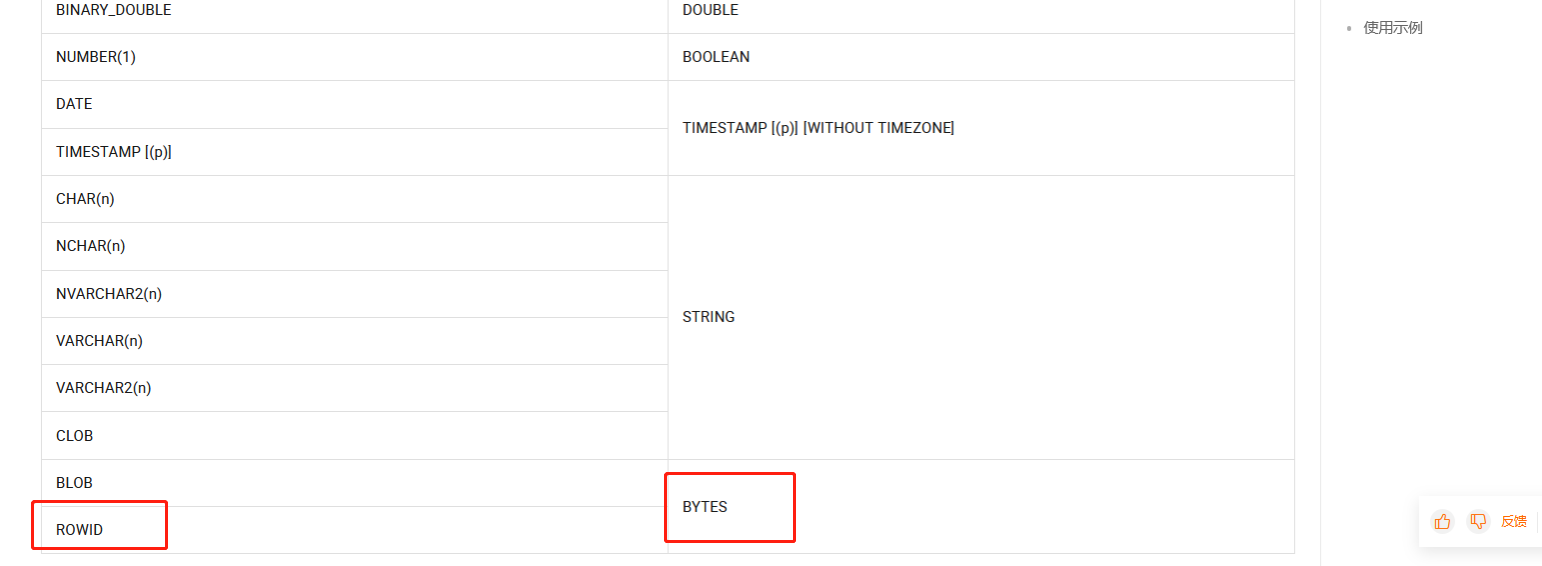
Flink CDC 可以同步 Oracle 中的 rowid,但是需要一些额外的配置。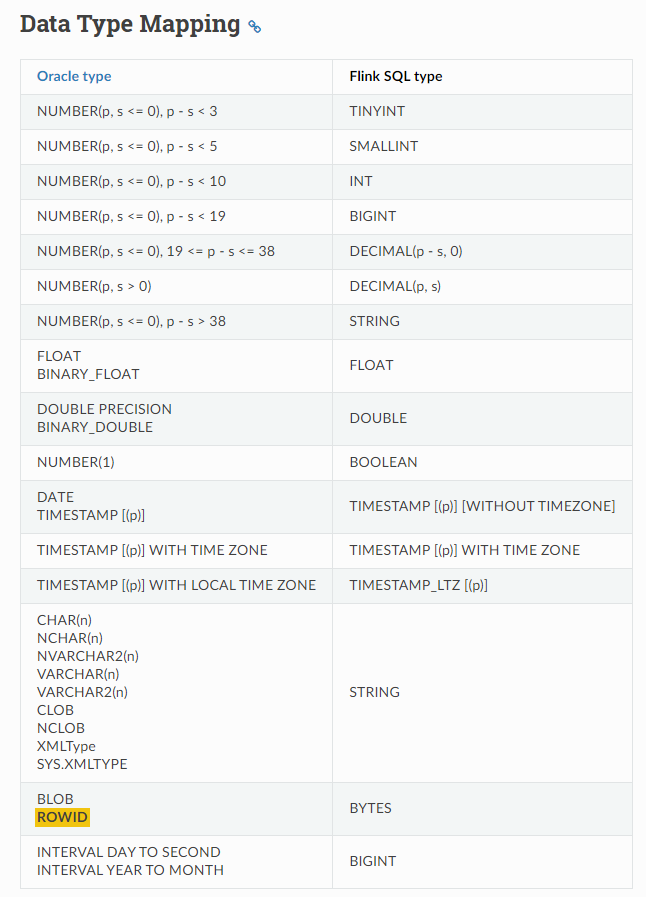
首先,确保 Flink CDC 的版本与 Oracle 数据库的版本兼容。然后,在 Flink CDC 的连接配置中,需要指定要同步的源表和目标表,并启用 rowid 的同步。
# Flink CDC 连接配置
jdbc:
url: jdbc:oracle:thin:@localhost:1521:ORCL
username: username
password: password
driver-class-name: oracle.jdbc.OracleDriver
schema-pattern: "your_schema_pattern"
table-pattern: "your_table_pattern"
fetch-size: 1000
enable-rowid: true
在上述配置中,enable-rowid 参数设置为 true,这将启用 rowid 的同步。同时,需要确保 Flink CDC 使用的 JDBC 驱动与 Oracle 数据库的版本兼容。
在 Flink CDC 的数据流转换部分,需要使用 MapFunction 将 rowid 添加到输出数据中。
StreamRecord<GenericRow> transform(StreamRecord<GenericRow> input) {
// Get the rowid from the input record
String rowId = input.getField(FlinkCdcFunctions.ROWID_FIELD).getString();
// Add the rowid to the output record
GenericRow output = new GenericRow(input.getFieldArray());
output.setField(FlinkCdcFunctions.ROWID_INDEX, rowId);
return new StreamRecord<>(output, input.getTimestamp());
}
在上述代码中,使用 FlinkCdcFunctions.ROWID_FIELD 获取 rowid,并将其添加到输出记录中。
最后,确保 Flink 作业的输出格式与目标表的结构相匹配,包括 rowid 列。例如,如果目标表是 Kafka 主题,则需要将 rowid 列作为消息的一部分进行输出。
楼主你好,在阿里云Flink CDC中同步Oracle中的ROWID需要使用特殊的语法来获取ROWID值。具体步骤如下:
在Flink的DDL语句中,设置ROWID字段的数据类型为VARCHAR2。
在SQL查询语句中,使用ORA_ROWSCN和ROWID函数来获取ROWID值:
SELECT rowid, ORA_ROWSCN FROM table_name
在Flink CDC的源配置中,将ROWID字段映射为VARCHAR2类型的字段。
配置Flink CDC的解析规则,将获取到的ROWID值插入到目标数据库中。
需要注意的是,ROWID值是Oracle特有的数据类型,不同于其他数据库中的自增主键或全局唯一标识符。因此在同步数据时需要特别处理,避免由于ROWID值重复导致数据错误或冲突。最后再排查一下这个参数表: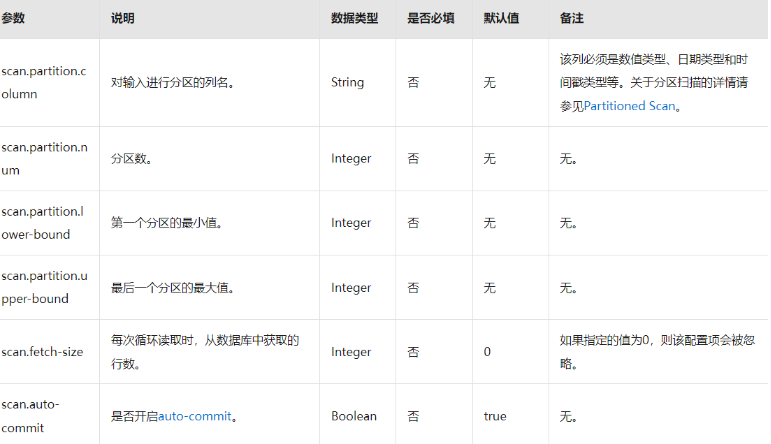
配置Flink CDC:在Flink CDC的配置文件中,将oracle.include-all-columns设置为true,以确保在数据捕获过程中包含ROWID列。例如,你可以在数据转换或过滤操作中根据ROWID进行筛选或分组。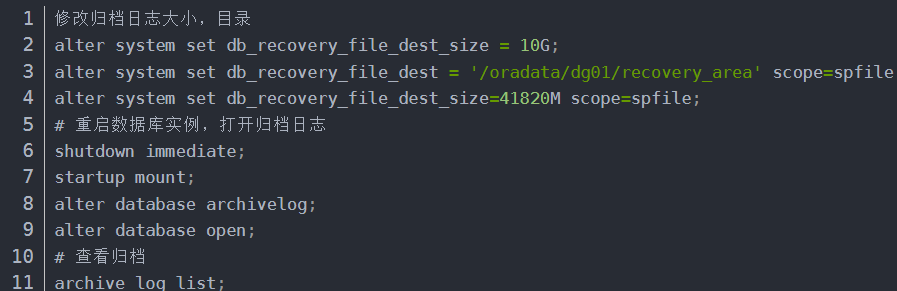
建议参考Flink官方文档或相关社区资源,以获取更准确和详细的指导。https://help.aliyun.com/zh/flink/developer-reference/jdbc-connector?spm=a2c4g.11186623.0.i29
开启Oracle数据库binlog日志输出时需要配置log_row_count和log_row_level参数,以保证输出到binlog中的数据包含rowid列。 请注意,在使用 ROWID 进行更新和删除操作时,需要特别小心确保操作的准确性和安全性。确保您有合适的权限来执行这些操作,并遵循最佳实践来处理敏感数据。
请注意,在使用 ROWID 进行更新和删除操作时,需要特别小心确保操作的准确性和安全性。确保您有合适的权限来执行这些操作,并遵循最佳实践来处理敏感数据。
在Flink CDC中同步Oracle中的ROWID,可以通过在SQL语句中查询ROWID并将其作为字段进行同步。具体操作步骤如下:
SELECT EMP.*, ROWID AS ORA_ROWID FROM EMP
这条SQL语句会查询EMP表中的所有数据以及每条数据对应的ROWID,并将其作为一个名为ORA_ROWID的字段进行同步。
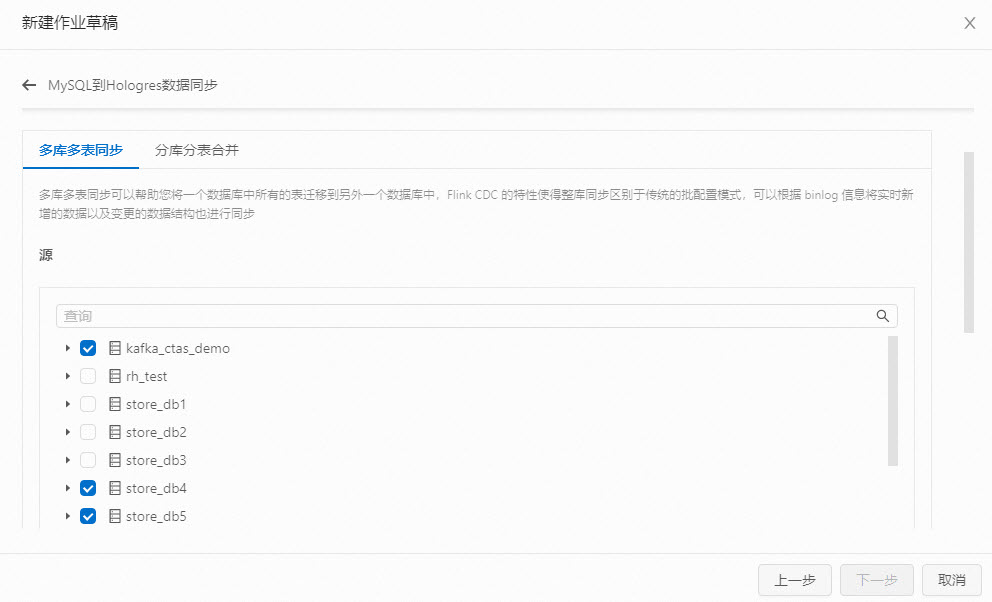
在 Flink CDC 中,同步 Oracle 数据库中的 ROWID 是可能的。以下是一些步骤,可以用于配置 Flink CDC 来同步 ROWID:
配置 Oracle CDC Source:使用 Flink CDC 提供的 Oracle CDC 连接器作为源来捕获变更数据。确保正确配置了连接信息、表名以及其他必要的参数。
设置 ROWID 列:在 Flink CDC Job 的配置中,将 ROWID 列包含在输出数据流中。您可以在 Avro 或 JSON Schema 中添加一个额外的字段来表示 ROWID。
使用 ROWID 进行更新和删除操作:在 Flink CDC Job 中,您可以使用 ROWID 来执行后续的更新和删除操作。通过将 ROWID 包含在输出数据流中,您可以使用它来构造相应的 SQL 语句,从而实现对目标数据库的更新和删除操作。
注意事项:请注意,在使用 ROWID 进行更新和删除操作时,需要特别小心确保操作的准确性和安全性。确保您有合适的权限来执行这些操作,并遵循最佳实践来处理敏感数据。
需要注意的是,具体的实现方式和配置可能会因您使用的 Flink 版本和相关的 CDC 连接器而有所不同。建议根据您的实际情况参考相应的文档和指南,并在需要时向 Flink 社区寻求更详细的支持和指导。
Flink CDC同步Oracle中的rowid需要额外处理,主要有以下几点:
开启Oracle数据库binlog日志输出时需要配置log_row_count和log_row_level参数,以保证输出到binlog中的数据包含rowid列。
在Flink CDC源码中,为Oracle数据库提供了专用的BinlogParser,它可以直接从binlog日志中解析出更多元数据,包括表中的rowid列。
自定义BinlogDeserializationSchema,继承OracleRowDeserializationSchema,重写extractRow()方法,额外解析并提取rowid列数据。
在sink端,自定义UpsertSqlBuilder,根据业务需要决定是否需要更新或插入数据时 where条件使用rowid。
sink的数据结构需要包含rowid列,以便下游程序使用。
示例代码如下:
java
Copy
// 自定义反序列化类
public class OracleRowDeserializationSchema extends OracleRowDeserializationSchema {
public RowData extractRow(GenericRowData row, Schema schema) {
RowData data = super.extractRow(row, schema);
// 解析并设置rowid
data.setField(schema.getFieldIndex("rowid"), row.getField("rowid"));
return data;
}
}
// 自定义UpsertSql生成
public class RidKeyUpsertSqlBuilder implements UpsertSqlBuilder {
public String buildSql(String table, RowData data, Schema schema) {
Long rid = data.getField(schema.getFieldIndex("rowid"));
// where条件使用rowid
return "merge into "+table+" using dual on (rowid = "+rid+")";
}
}
以此方式可以在Flink CDC同步过程中同步传递并使用Oracle表中的rowid主键列。
如果您想要使用Flink CDC同步Oracle中的rowid,可以通过以下方式进行:
查看Flink CDC的配置文件:在Flink CDC的配置文件中,可以查看connector参数,以确定Flink CDC支持的数据库类型。例如,如果您的Flink CDC支持连接Oracle数据库,那么您可以在connector参数中指定Oracle数据库的连接信息。
查看Flink CDC的启动命令:在Flink CDC的启动命令中,可以查看--add-plugins参数,以确定Flink CDC支持的数据库类型。例如,如果您的Flink CDC支持连接Oracle数据库,那么您可以在--add-plugins参数中指定Oracle数据库的插件信息。
需要注意的是,如果您在生产环境中使用Flink CDC同步Oracle中的rowid,那么您需要确保Flink CDC使用的是稳定版本的Oracle数据库连接器。同时,您还需要确保Flink CDC的数据备份和恢复机制,以保证数据的安全性和可靠性。
Flink CDC(Change Data Capture)是一种用于捕获数据库中数据变化的技术。要在Flink中使用CDC同步Oracle中的RowID,您需要按照以下步骤操作:
确保您的Oracle数据库已经启用了归档日志功能。这可以通过修改参数db_recovery_file_dest_size和db_recovery_file_dest来实现。例如,将db_recovery_file_dest_size设置为10GB,并将db_recovery_file_dest指向一个空闲磁盘空间较大的文件夹。
创建一个具有足够权限的Oracle用户,以便Flink可以访问数据库。这个用户应该能够执行DDL(数据定义语言)语句,如ALTER TABLE和CREATE TABLE。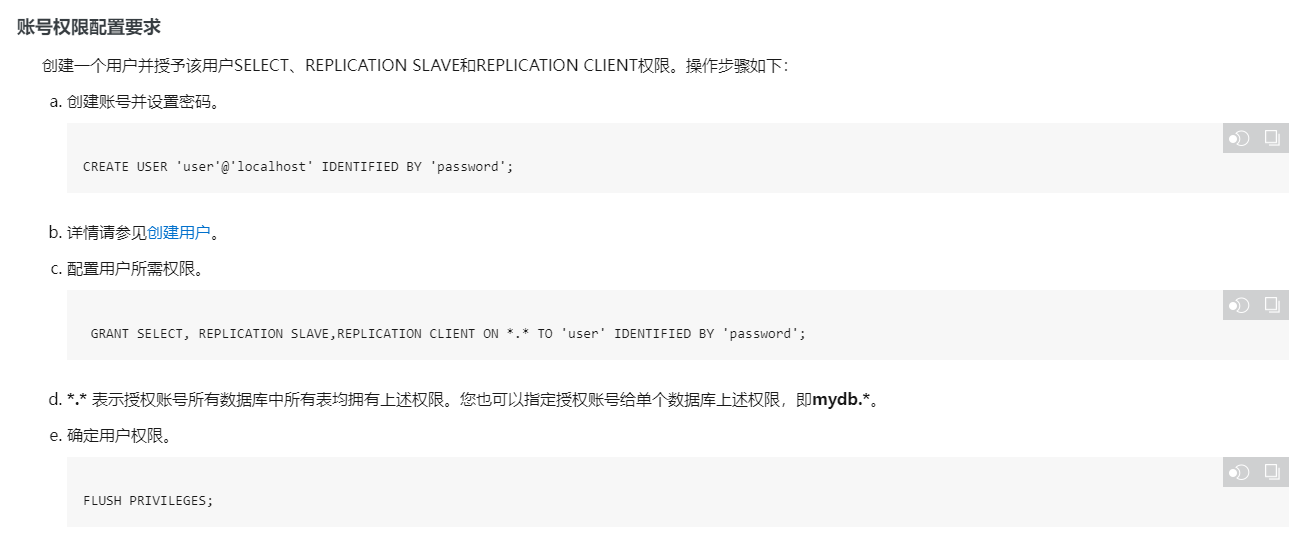
为要同步的表或数据库启用增量日志记录。这通常是通过在ALTER TABLE语句后添加ENABLE ROWID LOGGING来完成的。例如:
ALTER TABLE my_table ENABLE ROWID LOGGING;
安装并配置Apache Flink环境。确保已安装Java JDK和Scala编译器。然后,从Apache Flink官方网站下载最新版本的Flink发行版。
克隆Flink CDC connector for Oracle仓库到本地:
git clone https://github.com/ververica/flink-cdc-connectors.git
将flink-connector-oracle-cdc模块导入到您的项目中。这可以通过将该模块添加到项目的pom.xml文件中来完成。
例如:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-oracle-cdc</artifactId>
<version>{{FLINK_VERSION}}</version>
</dependency>
在Flink作业中添加一个新的DataStream应用程序,并在其中添加一个ReadOnlyTableSourceFunction函数。此函数将读取来自Oracle数据库的数据。例如:
val tableSource = new ReadOnlyTableSourceFunction("jdbc:oracle:thin:@localhost:1521:xe", "my_user", "my_password", "my_schema.my_table")
运行Flink作业以启动数据流处理任务。
这可以通过在命令行中输入以下命令来完成:
```
./bin/flink run -m "exec" -c org.apache.flink.streaming.api.scala.StreamExecutionEnvironment \
-p output_path output_path \
-p checkpoint_interval 1000 \
-p parallelism 1 \
-p table_source tableSource \
-p job_name MyJob \
-p zookeeper_quorum localhost:2181 \
-p group_id testGroup \
-p application_timeout 60 \
-p rest_port 8081 \
-p rest_addresses localhost:8081 \
-p state_backend_type rocksdb \
-p state_backend_path file:///opt/cloudera/parcels/CDH-5.13.-SNAPSHOT/etc/hadoop/conf \
-p keyed_state_backend_path file:///opt/cloudera/parcels/CDH-5.13.-SNAPSHOT/etc/hadoop/conf \
-p default_parallelism 1 \
-p taskmanager_memory 4096 \
-p network_card_memory --- \
-p slot_num 1 \
-p slots_per_task 1 \
-p yarn_session_application_timeout 60 \
-p hadoop_binary_home /usr/lib/hadoop/ \
-p hive_metastore_uris thrift://localhost:9083 \
-p oozie_url http://localhost:11
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


