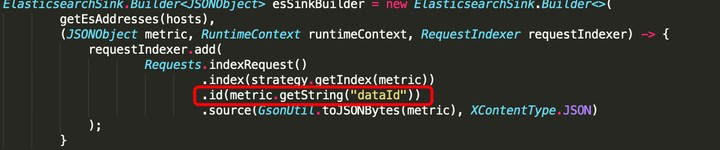
大佬们,我目前的场景是flinkcdc 用sql将mongo数据同步到es,有人做过这样的场景吗?
想问一下,在写es的时候,如何指定_id的值呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
将 MongoDB 中的数据同步到 Elasticsearch 中,可以使用 Flink 的 CDC(Change Data Capture)功能,通过监听 MongoDB 中的数据变更事件来实现数据同步。具体来说,您可以使用 Flink 的 MongoDB Connector 来从 MongoDB 中读取数据,然后使用 Flink 的 Elasticsearch Connector 将数据写入 Elasticsearch 中,实现数据同步。
下面是一个简单的示例代码,演示如何使用 Flink CDC 将 MongoDB 中的数据同步到 Elasticsearch 中:
java
Copy
// 创建 MongoDB 数据源
MongoDBSource mongoDBSource = MongoDBSource.builder()
.withUri(mongoURI)
.withDatabase(database)
.withCollection(collection)
.withDeserializer(new PersonDeserializer())
.build();
// 创建 Elasticsearch 数据源
ElasticsearchSink.Builder esSinkBuilder = new ElasticsearchSink.Builder<>(
elasticsearchUris,
new ElasticsearchSinkFunction() {
public IndexRequest createIndexRequest(Person element) {
Map json = new HashMap<>();
json.put("name", element.getName());
json.put("age", element.getAge());
return Requests.indexRequest()
.index(indexName)
.source(json);
}
@Override
public void process(Person element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
});
// 创建 Flink 程序
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream dataStream = env.addSource(mongoDBSource);
dataStream.addSink(esSinkBuilder.build());
// 启动 Flink 程序
env.execute("MongoDB to Elasticsearch");
需要注意的是,在实际使用过程中,您需要根据具体的业务场景和需求,对代码进行适当的调整和优化。例如,可以根据数据量大小和同
是的,将 MongoDB 数据通过 Flink CDC 同步到 Elasticsearch 的场景是很常见的。使用 Flink SQL 可以方便地实现这样的数据流转过程。
在写入 Elasticsearch 时,可以通过 Elasticsearch Sink 的配置来指定 _id 字段的值。具体而言,您需要在 Elasticsearch Sink 中设置 key-field 参数,指定要作为 _id 的字段名。
以下是一个示例配置:
CREATE TABLE es_sink (
id STRING,
name STRING,
age INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch',
'hosts' = 'http://localhost:9200',
'index' = 'your_index',
'document-type' = 'your_document_type',
'key-field' = 'id'
)
在以上示例中,id 字段被指定为 _id 字段。
通过这种方式,Flink 在将数据写入 Elasticsearch 时会使用指定字段的值作为 _id。如果您的数据中没有唯一标识字段,可以考虑使用组合字段或自定义逻辑生成唯一标识。
总结而言,通过 Flink CDC 和 Flink SQL 结合,您可以将 MongoDB 数据同步到 Elasticsearch 中。在写入 Elasticsearch 时,可以通过 Elasticsearch Sink 的配置来指定 _id 字段的值,使用 key-field 参数来指定要作为 _id 的字段名。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。