
大数据计算MaxCompute中maxcompute spark如何读取 oss 上面的文件?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 MaxCompute Spark 中,可以通过以下方式来读取 OSS 上的文件:
配置 OSS 访问信息:首先,需要在 Spark 的配置文件中配置 OSS 访问信息,包括 AccessKeyId、AccessKeySecret、Endpoint 等信息,示例代码如下:
Copy
spark.hadoop.fs.oss.accessKeyId=your_access_key_id
spark.hadoop.fs.oss.accessKeySecret=your_access_key_secret
spark.hadoop.fs.oss.endpoint=your_oss_endpoint
其中,your_access_key_id 和 your_access_key_secret 分别是您的 OSS 访问凭证,your_oss_endpoint 是您的 OSS 访问域名。
创建 SparkSession:使用 SparkSession 对象来读取 OSS 上的文件,示例代码如下:
stylus
Copy
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder
.appName("Read OSS File")
.master("local")
.config("spark.hadoop.fs.oss.impl", "com.aliyun.fs.oss.nat.NativeOssFileSystem")
.getOrCreate()
val df = spark.read.text("oss://your_bucket/your_path/file.txt")
df.show()
在上述代码中,使用 SparkSession.builder 创建 SparkSession 对象,并指定应用程序名称和主节点地址。在配置信息中,设置了 fs.oss.impl 参数为 com.aliyun.fs.oss.nat.NativeOssFileSystem,表示使用阿里云提供的 OSS 文件系统访问 OSS 上的文件。在读取文件时,使用 spark.read.text 方法读取 OSS 上的文本文件,并使用 df.show() 方法显示文件内容。
在大数据计算MaxCompute中,您可以使用MaxCompute Spark(Spark on MaxCompute)来读取OSS上的文件。以下是一种常用的方法:
确保您已经安装和配置了MaxCompute Spark。请参考MaxCompute官方文档或相关资源以获取详细的安装和配置指南。
在MaxCompute项目中创建一个外部表,定义该表与OSS文件的结构和位置。您可以使用类似以下的SQL语句来创建外部表:
CREATE EXTERNAL TABLE your_table_name (
column1 string,
column2 int
)
STORED BY 'com.aliyun.odps.spark.OdpsRelationProvider'
LOCATION 'oss://your_bucket/your_path';
替换上述参数为您自己的OSS Bucket名称和文件路径。
在Spark中读取该外部表,并进行进一步的处理。您可以使用Spark的DataFrame API或SQL语句来操作数据。示例代码如下:
from odps import ODPS
from pyspark.sql import SparkSession
access_id = 'your_access_id'
access_key = 'your_access_key'
project = 'your_project_name'
endpoint = 'your_endpoint'
table_name = 'your_table_name'
spark = SparkSession.builder \
.appName('Read from OSS') \
.getOrCreate()
# 通过ODPS连接信息创建ODPS对象
odps = ODPS(access_id, access_key, project, endpoint)
# 使用ODPS读取OSS外部表
df = spark.read.format('org.apache.spark.sql.execution.datasources.odps') \
.option('odps.task.development.mode', 'true') \
.option('odps.access.id', access_id) \
.option('odps.access.key', access_key) \
.option('odps.project.name', project) \
.option('odps.endpoint', endpoint) \
.option('odps.tables', table_name) \
.load()
# 对DataFrame进行进一步的操作和处理
# ...
spark.stop()
替换上述参数为您自己的Access ID、Access Key、MaxCompute项目名称、Endpoint和外部表名称。
通过以上步骤,您就可以使用MaxCompute Spark来读取OSS上的文件,并在Spark中进行数据处理和分析。
Endpoint用公网的,用oss上bucket的概览里的oss Endpoint示例参考:https://help.aliyun.com/zh/maxcompute/user-guide/spark-2-x-examples?spm=a2c4g.11186623.0.0#section-97l-j6r-3sxoss Endpoint参考: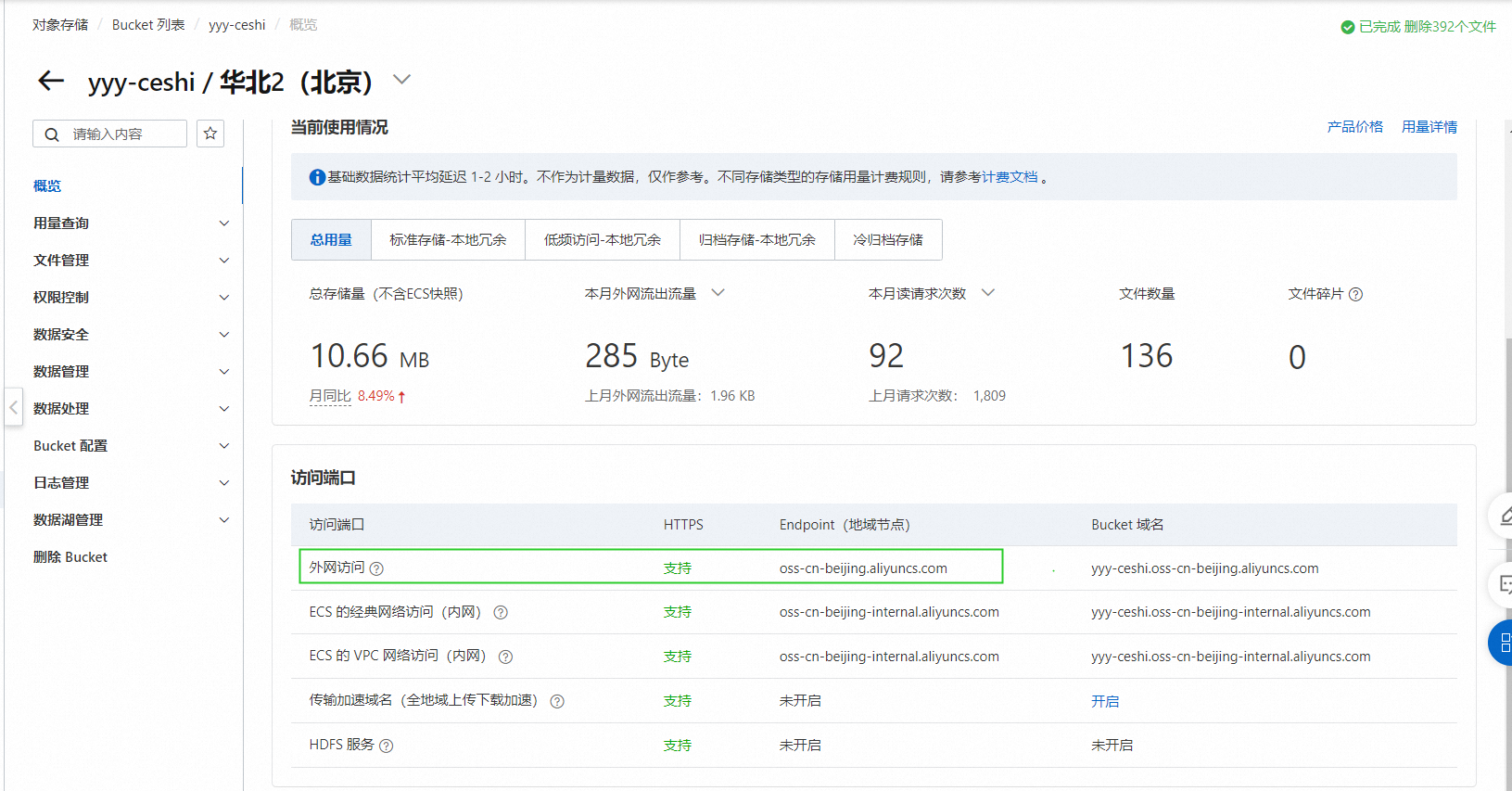 此回答整理自钉群“MaxCompute开发者社区1群”
此回答整理自钉群“MaxCompute开发者社区1群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


