
Dataworks离线同步读取MaxCompuet(ODPS)表数据时,如何同步多个分区数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云 DataWorks 中,可以通过以下步骤同步多个分区的 MaxCompute(ODPS)表数据:
创建数据同步任务:在 DataWorks 中创建数据同步任务,选择要同步的源数据源和目标数据源。
配置同步任务参数:在创建数据同步任务时,需要对同步任务进行参数配置。其中,同步任务参数中包括了分区信息,可以通过参数化配置的方式将多个分区的数据同步到目标数据源中。
添加分区参数:在同步任务参数中,可以添加多个分区参数。每个分区参数都需要指定分区名称和分区值。例如,如果要同步 MaxCompute 表的 2022 年 1 月到 12 月的数据,可以添加 12 个分区参数,每个参数对应一个月的数据。
配置同步规则:在同步任务中,需要配置同步规则,指定要同步的表、同步方式、目标表的结构等信息。
启动同步任务:完成配置后,启动同步任务即可将多个分区的 MaxCompute 表数据同步到目标数据源中。
在DataWorks中,你可以使用同步任务节点来离线同步读取MaxCompute(ODPS)表的多个分区数据。以下是一种可能的实现方式:
创建同步任务节点:在DataWorks中,创建一个同步任务节点用于读取MaxCompute表的数据。
配置源表和目标表:在同步任务节点中,配置源表和目标表的信息。源表是MaxCompute表,而目标表可以是另一个MaxCompute表或其他目标存储位置。
设置分区参数:为了同步多个分区的数据,你可以在同步任务节点的参数中设置分区变量。例如,如果你想同步某个分区的所有数据,可以在参数中使用动态分区变量,如${yyyymmdd},其中yyyymmdd表示分区的日期。
循环执行任务:为了同步多个分区的数据,你可以在同步任务节点外面包裹一个循环节点。循环节点的循环条件可以根据你的需求来定义,例如按照日期范围、特定分区列表等。
按分区参数同步数据:在循环节点内部,将同步任务节点放置在循环节点中,并使用分区参数来动态指定要同步的分区。通过每次迭代循环,同步任务节点都会使用不同的分区参数值来同步对应的分区数据。
完成任务配置:确认所有配置项都填写正确,并保存任务的配置。
读取数据所在的分区信息。ODPS的分区配置支持linux shell通配符,表示0个或多个字符,?表示任意一个字符。默认情况下,读取的分区必须存在,如果分区不存在则运行的任务会报错。如果您希望当分区不存在时任务仍然执行成功,则可以切换至脚本模式执行任务,并在ODPS的Parameter中添加"successOnNoPartition": true配置。例如,分区表test包含pt=1,ds=hangzhou、pt=1,ds=shanghai、pt=2,ds=hangzhou、pt=2,ds=beijing四个分区,则读取不同分区数据的配置如下:如果您需要读取pt=1,ds=hangzhou分区的数据,则分区信息的配置为"partition":"pt=1,ds=shanghai”。
如果您需要读取pt=1中所有分区的数据,则分区信息的配置为"partition":"pt=1,ds=”。
如果您需要读取整个test表所有分区的数据,则分区信息的配置为"partition":"pt=,ds=”。此外,您还可以根据实际需求设置分区数据的获取条件(以下操作需要转脚本模式配置任务):如果您需要指定最大分区,则可以添加/query/ ds=(select MAX(ds) from DataXODPSReaderPPR)配置信息。
如果需要按条件过滤,则可以添加相关条件/query/ pt+表达式配置。例如/query/ pt>=20170101 and pt<20170110表示获取pt分区中,20170101日期之后(包含20170101日期),至20170110日期之前(不包含20170110日期)的所有数据。说明/query/表示将其后填写的内容识别为一个where条件。
https://help.aliyun.com/document_detail/146663.html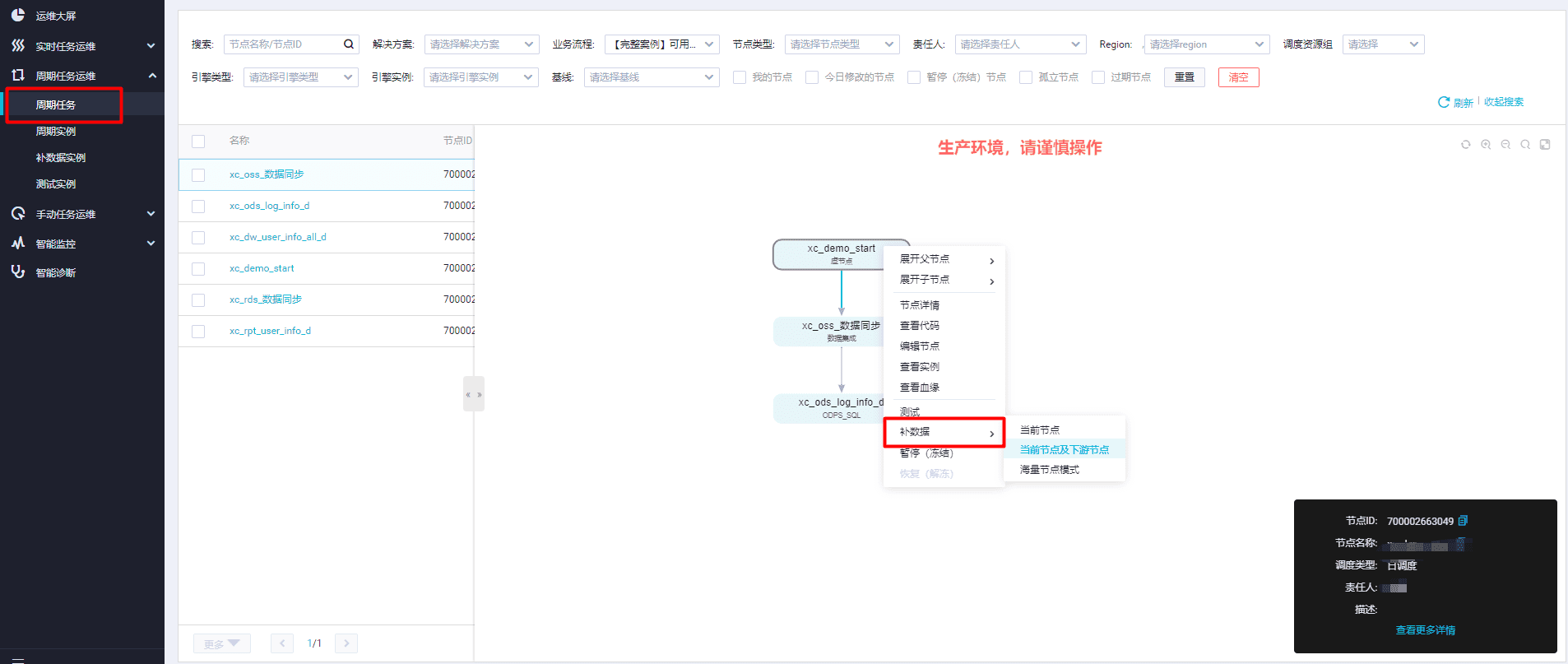
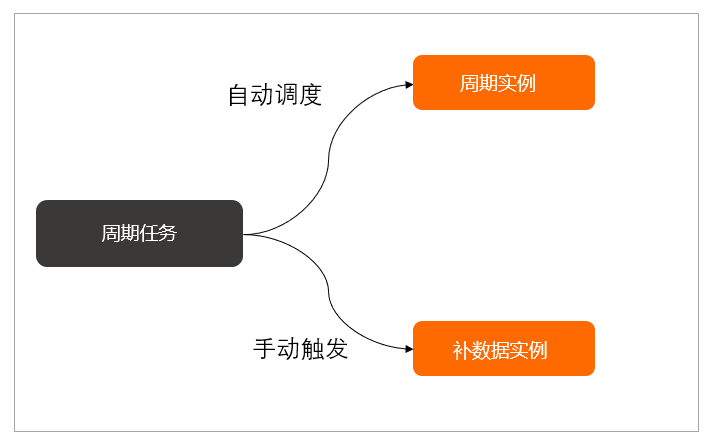
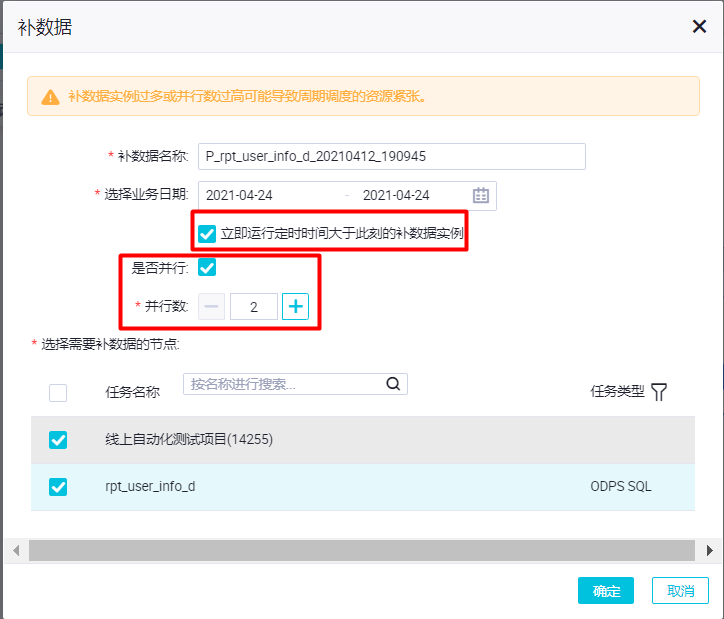
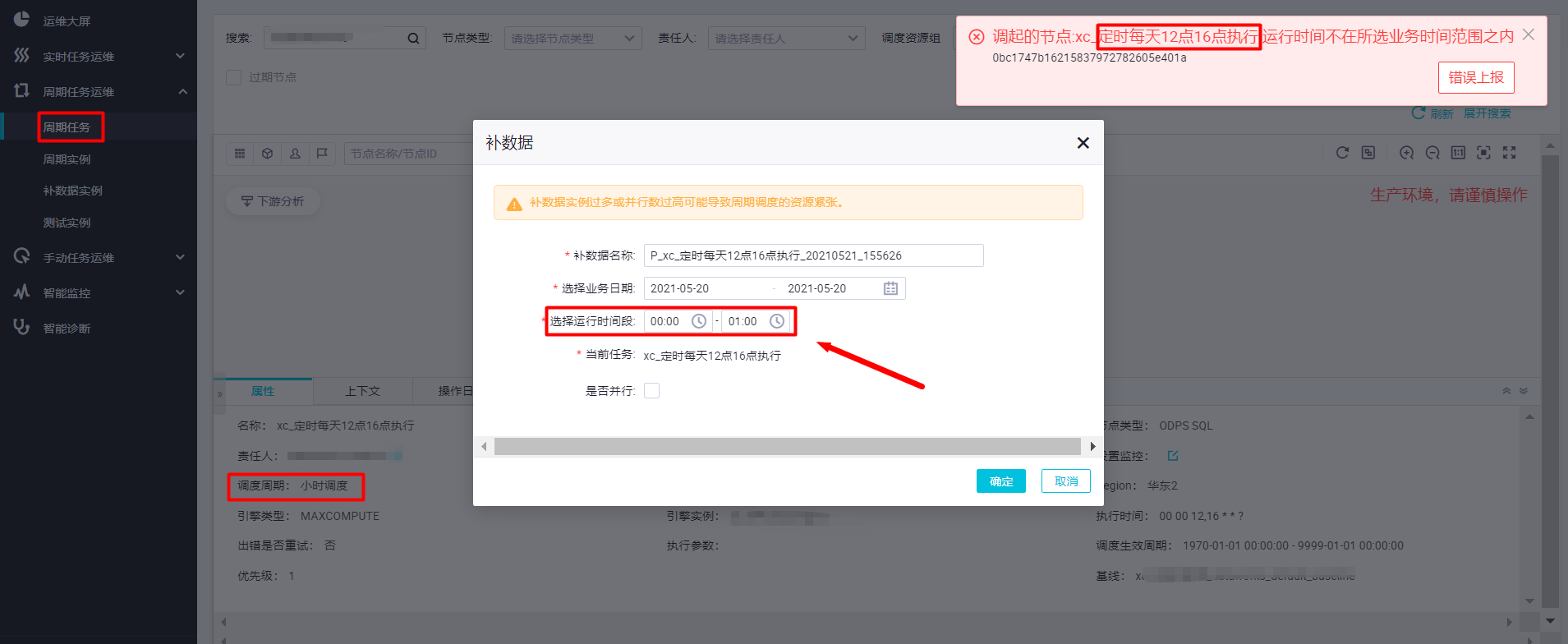
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


