
大数据计算MaxCompute我的odps任务中途总是会失败一次,报错如下,帮忙看看是为什么?
{"t":"SERVICE_MODE","a":{"f":{"odps.service.mode":"off"}},"d":"ODPS-0010000:System internal error - Service mode falling back to batch mode to rerun due to AllOrNothingResourceWaitTimeout"}
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
任务整体是成功的,过程中是online job失败后,回退到了offline。报错也是回退的时候报的我理解。Fuxi Job的两种作业类型:Online Job(service mode)和Offline Job。对于Offline的作业而言,当每次提交作业时在Fuxi上都会有一个环境准备的时间,针对大数据量并且不需要返回查询结果的作业比较合适,而对小数据量并且实时作业要求比较高的作业是不合适的。所以Fuxi提供为什么ServiceMode这种准实时的作业形式,也是online,首先会有一个服务去预先申请计算一些资源并加载出来,比如会预先分配一 万个nstance,当有作业提交时会根据作业规模分配一些Instance进行执行,这样就省去环境准备的时间,所以就会比较快。online不等资源且不保证成功。如果service mode失败,比如instance个数超过1000,或者运行超过10分钟,就会退回以Offline模式重跑。可以set odps.service.mode=off;这样就直接跑完了,不会再跑online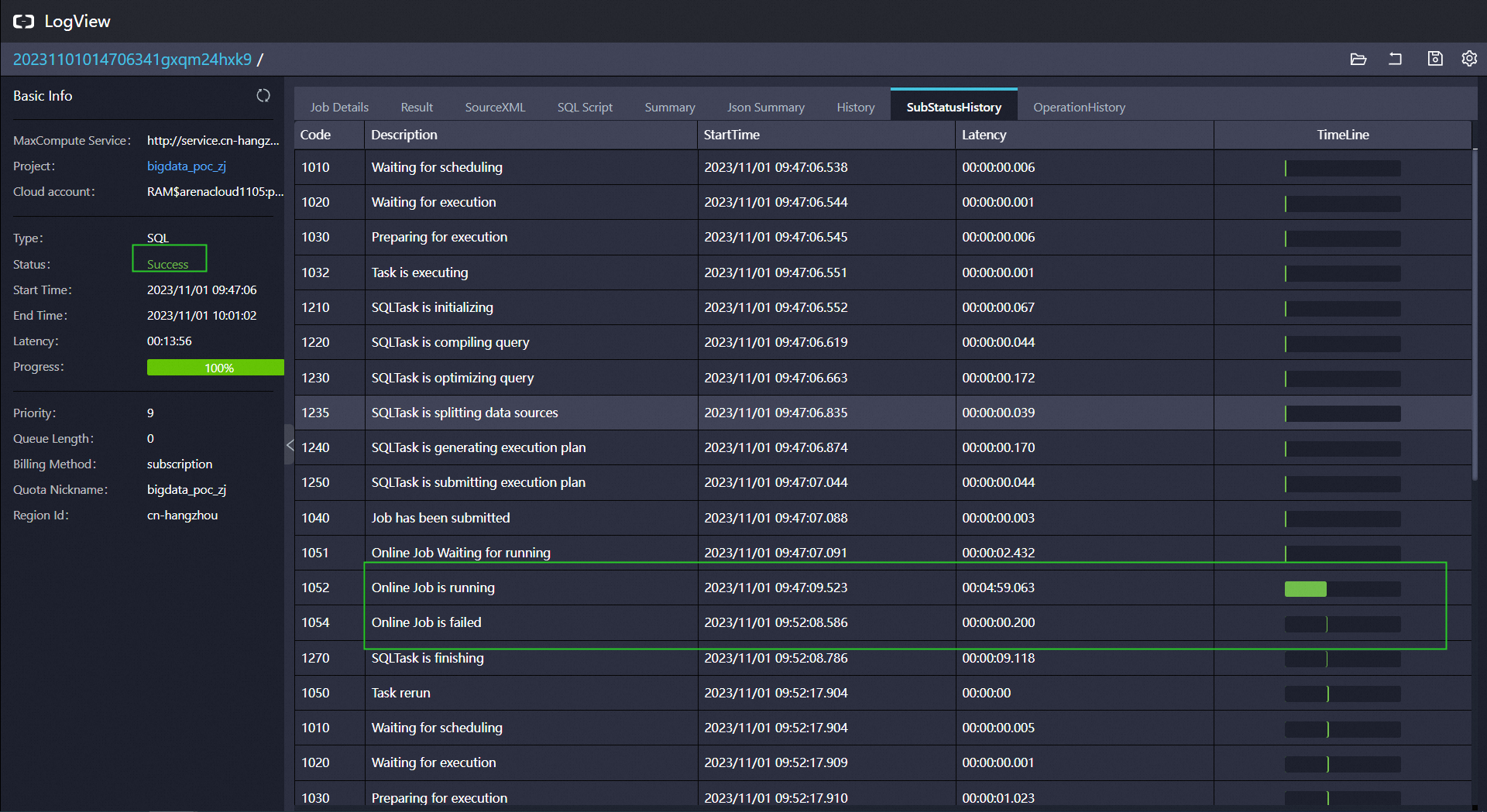
,此回答整理自钉群“MaxCompute开发者社区2群”
根据您提供的错误信息,问题可能是由于MaxCompute的在线服务模式被关闭导致的。错误信息中提到了"AllOrNothingResourceWaitTimeout",这意味着任务在等待资源时超时,导致任务失败。
要解决这个问题,您可以尝试以下方法:
odps.service.timeout参数来增加任务的超时时间。例如,将超时时间设置为30分钟:SET odps.service.timeout=1800;
-- 在这里编写您的SQL查询语句
检查资源可用性:确保您的MaxCompute环境中有足够的资源(如内存、CPU等)来运行任务。如果资源不足,任务可能会因为等待资源而超时。
优化SQL查询:检查您的SQL查询是否存在性能问题,如低效的JOIN操作、大量的数据筛选等。优化查询可以提高任务的执行效率,从而减少任务的超时风险。
检查依赖关系:确保您的任务依赖的其他任务或作业已经成功完成。如果依赖的任务失败,可能会导致当前任务失败。
查看日志:您可以查看MaxCompute的日志以获取更多关于任务失败原因的信息。日志中可能包含有关错误的详细信息和建议的解决方案。
根据您的描述和提供的日志信息,看起来您的MaxCompute任务遇到了一个内部系统错误,导致它从批处理模式退回到了服务模式重新运行,这是由于“AllOrNothingResourceWaitTimeout”(所有或无等待超时)造成的。
这个问题可能是由于资源不足或无法及时调度而导致的,例如:存储空间不足、内存不足、网络拥塞等情况。您可以考虑以下几种解决方案:
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


