
问题1:Flink CDC这个拉取速度要把参数怎么调才能达到?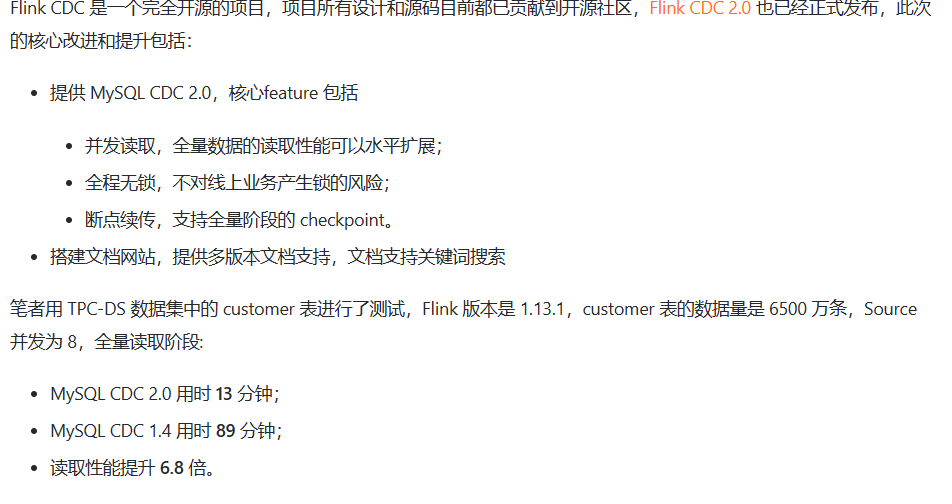 我大概知道调哪些参数,我调了chunksize和fetchsize,我是写doris,写入速度70多万一分钟 问题2:这个里面每分钟读了500万条,所以想问问这个6500万条13分钟的参数设的多少?
我大概知道调哪些参数,我调了chunksize和fetchsize,我是写doris,写入速度70多万一分钟 问题2:这个里面每分钟读了500万条,所以想问问这个6500万条13分钟的参数设的多少?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要优化Flink CDC的拉取速度,需要根据具体的场景调整不同的参数。除了chunkSize参数之外,还有以下几个参数可以影响拉取速度:
maxParallelism: 这个参数控制Flink CDC任务的最大并行度,即同时处理的数据流数目。如果您的数据量较大,可以适当增加这个参数的值,以提高任务的并行处理能力。
pollInterval: 这个参数控制Flink CDC任务从源数据库中拉取数据的时间间隔。如果您的数据变化较频繁,可以适当缩短这个时间间隔,以提高任务的实时性。
maxRetries: 这个参数控制Flink CDC任务在拉取数据时发生错误的最大重试次数。如果您的网络环境不稳定,可以适当增加这个参数的值,以提高任务的容错能力。
maxRetryTimeout: 这个参数控制Flink CDC任务在发生错误时的最大重试时间。如果您的网络环境不稳定,可以适当增加这个参数的值,以避免任务因网络延迟而失败。
要提高 Flink CDC 的拉取速度,可以调整多个参数以优化性能。除了 chunkSize 和 fetchSize,还有其他一些参数可以考虑进行调整:
1. maxParallelism:根据你的环境和任务需求,适当增加最大并行度。这样可以充分利用资源并提高并行处理的能力。
2. maxNumberOfParallelRequests:增加并行请求的数量,允许同时发起更多的数据库请求。这可以提高数据读取的并发性能。
3. idleTimeout:调整空闲超时时间,避免无效的连接等待。根据数据库特性和网络状况,将其设置为合理的值以避免性能下降。
4. connectionProperties:根据数据库类型和配置,设置适当的连接属性,如批量插入模式、提交间隔等。这些属性可能会对读取性能产生影响。
5. 硬件资源配额:确保 Flink 集群的硬件资源足够支持高吞吐量的数据读取。包括 CPU、内存、磁盘和网络等方面的资源。
需要注意的是,每个应用和环境都具有不同的特点,因此最佳的参数调整方式可能会因情况而异。建议先了解官方文档中关于性能调优的指导,并根据实际情况进行逐步调整和测试。
关于第二个问题,每分钟读取了 500 万条数据,如果要在 13 分钟内处理 6500 万条数据,可以根据需求和资源情况计算出合理的并行度、处理速度和任务配置。这包括调整并行度、分区策略、资源配额等。
回答1:看文档啊,要调性能,先把官网文档里面,所有性能相关的参数都了解一下,然后一点一点的调整,每秒1.2万?那不低了,此回答整理自钉群“Flink CDC 社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


