
大佬们,用python Flink CDC 1.13.6, flink cdc 2.2.1 读mysql-cdc数据卡住,ctrl+C停止报以下错误是什么原因呢?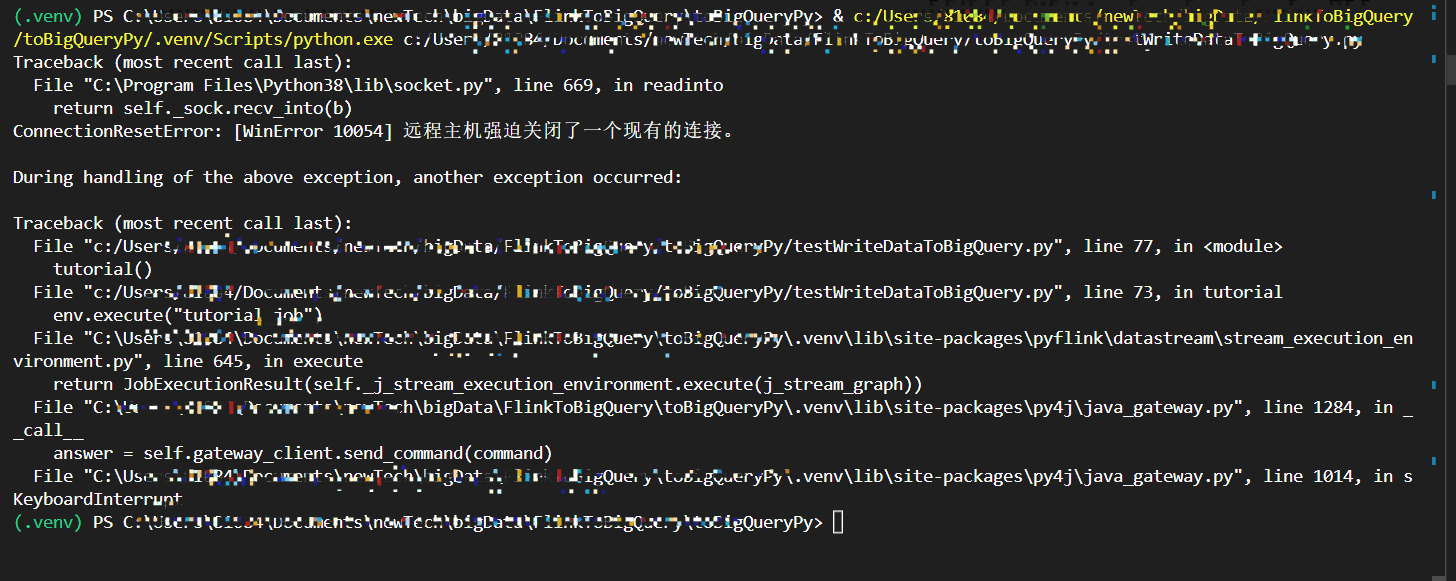
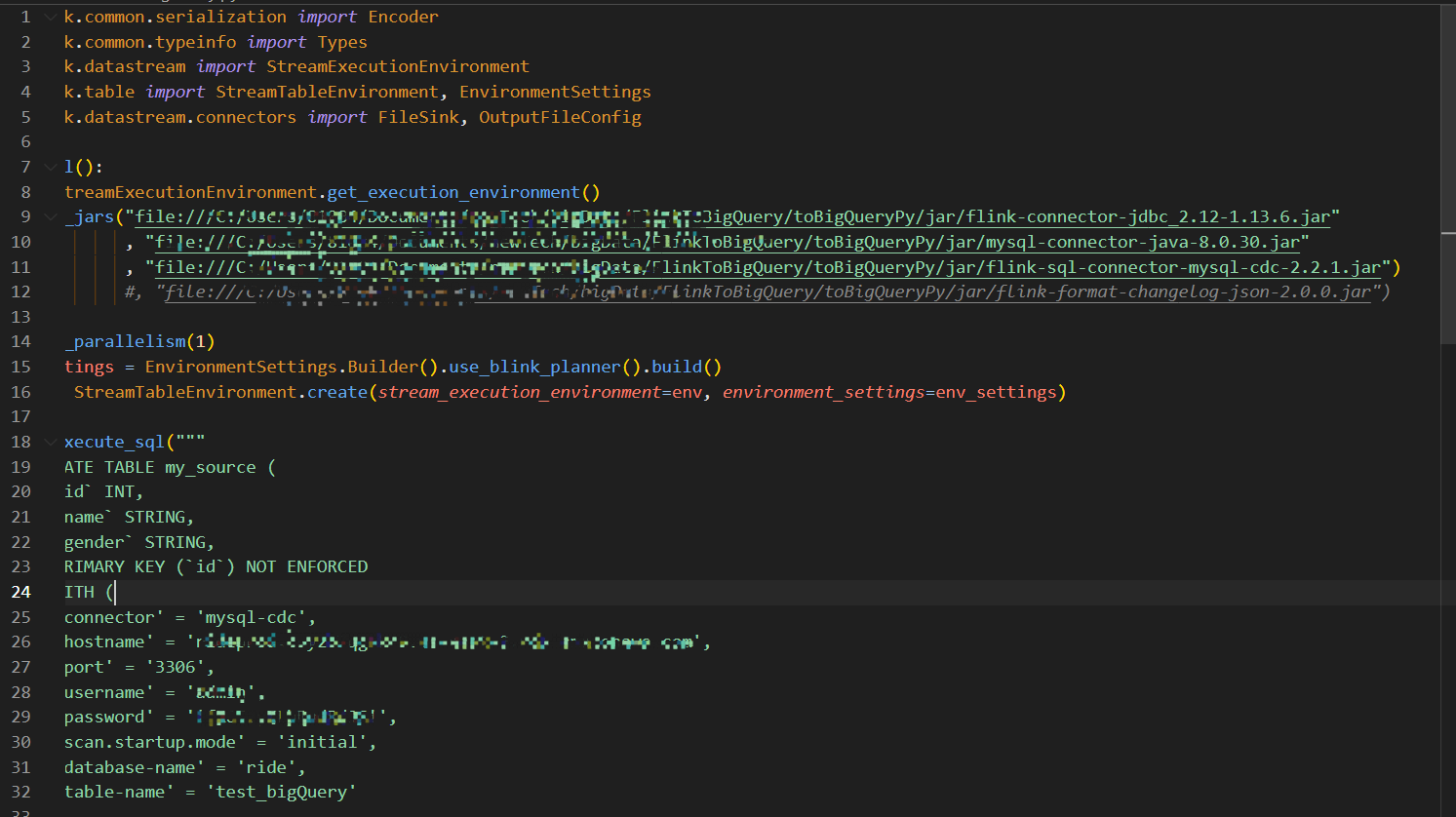
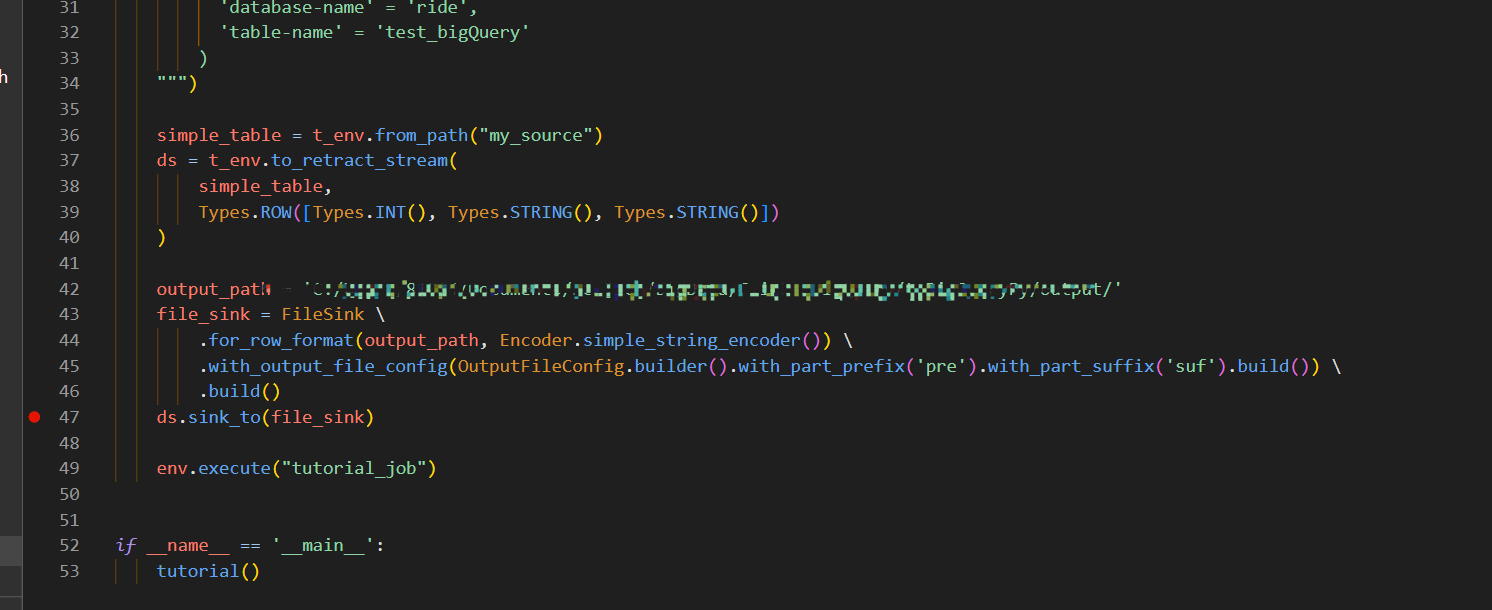 python版本 3.8.0
python版本 3.8.0
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Python中使用Flink CDC 1.13.6和Flink CDC 2.2.1读取MySQL CDC数据时出现卡住的问题,以及使用Ctrl+C停止时报告的错误,可能有以下原因:
1. Flink和Flink CDC版本不兼容:确保您使用的Flink和Flink CDC版本是兼容的。请检查它们之间的兼容性,并尝试使用兼容的版本。
2. 连接配置错误:检查您的连接配置是否正确。确保提供了正确的数据库主机名、端口号、用户名和密码等信息。
3. 数据表配置错误:请确保您提供的表名和数据库名称是正确的,并且这些表确实存在于相应的数据库中。
4. 网络或权限问题:确保您的网络连接正常,并且具有访问MySQL数据库的适当权限。
关于Ctrl+C停止时报告的错误,您可以提供更多详细信息以便进一步排查。
为了解决这个问题,您可以尝试以下几个方法:
- 检查Flink和Flink CDC版本的兼容性:确保您使用的Flink和Flink CDC版本是兼容的。可参考官方文档以获取版本兼容性信息。
- 检查连接配置和数据表配置:仔细检查您的连接配置和数据表配置,确保所有配置都是正确的。
- 检查网络和权限:确保您的网络连接正常,并具有访问MySQL数据库的适当权限。
如果问题仍然存在,建议参考Flink CDC的官方文档、社区讨论或寻求专业支持来获取更准确的帮助。同时,提供更多错误信息可以帮助其他人更好地理解和解决您的问题。
Flink CDC 是一个基于 Flink 流处理框架的工具,用于实时捕获和同步数据库变更。Flink CDC 支持多种编程语言和客户端,包括 Python、Java、Go 等语言。
如果您要在 Python 中使用 Flink CDC,您可以使用 Flink 的 Python API 和 Flink CDC 提供的 Python 客户端来实现。以下是一个简单的示例,演示如何在 Python 中使用 Flink CDC:
安装 Flink 和 Flink CDC:
首先,您需要下载并安装 Flink 和 Flink CDC。您可以在 Flink 的官方网站上下载最新版本的 Flink 和 Flink CDC。
编写 Python 代码:
在 Python 中使用 Flink CDC,您需要使用 Flink 的 Python API 和 Flink CDC 提供的 Python 客户端。下面是一个示例代码,演示如何使用 Python 连接到 Flink 和 Flink CDC,并捕获数据库变更:
python
Copy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import TableEnvironment, DataTypes
from pyflink.table.expressions import col
from pyflink.table.descriptors import Schema, OldCsv, Debezium
from pyflink.table.types import RowType
env = StreamExecutionEnvironment.get_execution_environment()
t_env = TableEnvironment.get_table_environment(env)
t_env \
.connect(Debezium()
.version('1.2')
.topic('test')
.property('connector.class', 'io.debezium.connector.mysql.MySqlConnector')
.property('database.hostname', 'localhost')
.property('database.port', '3306')
.property('database.user', 'root')
.property('database.password', '123456')
.property('database.server.name', 'test')
.property('table.include.list', 'test.test_table')
.property('database.history.kafka.bootstrap.servers', 'localhost:9092')
.property('database.history.kafka.topic', 'mysql-history')
) \
.with_format(OldCsv()
.field_delimiter(',')
.field('after_id', DataTypes.BIGINT())
.field('after_name', DataTypes.STRING())
.field('after_age', DataTypes.INT())
) \
.with_schema(Schema()
.field('after_id', DataTypes.BIGINT())
.field('after_name', DataTypes.STRING())
.field('after_age', DataTypes.INT())
) \
.create_temporary_table('test_table')
result = t_env.from_path('test_table') \
.select(col('after_id'), col('after_name'), col('after_age'))
result.print_schema()
result.print()
在上述代码中,首先使用 Flink 的 Python API 创建了 StreamExecutionEnvironment 和 TableEnvironment 对象。然后,使用 Flink CDC 提供的 Python 客户端,连接到 MySQL 数据库,并捕获 test.test_tabl
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


