
Flink CDC 使用yarn- application提交python作业报错,有遇到过的么?python3.8、flink 1.18.1。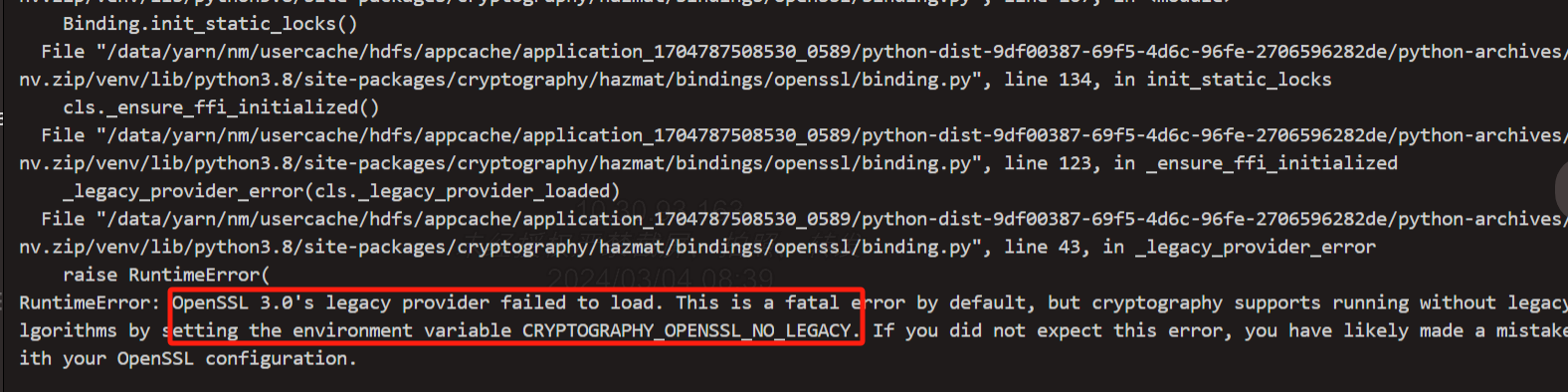
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题描述,Flink CDC 使用 YARN Application 模式提交 Python 作业时出现报错,以下是可能的原因分析及解决方案:
Flink 1.18.1 和 Python 3.8 的组合可能存在兼容性问题。根据知识库中的信息,Flink 对 Python 环境有明确的版本要求: - 实时计算引擎 VVR 8.0.11 及以上版本预装 Python 3.9.21。 - 如果使用较低版本的 Python(如 3.7.9),需要对 PyFlink 作业进行重新测试和部署。
建议操作: - 确保 Flink 集群中预装的 Python 版本与您的代码兼容。如果集群默认使用 Python 3.9.21,而您的代码依赖 Python 3.8,请尝试升级代码以适配 Python 3.9.21。 - 如果无法升级代码,可以考虑在 YARN 容器中自定义 Python 环境,并通过 pyflink 的配置指定 Python 解释器路径。
YARN Application 模式下,Flink 作业的资源分配可能会受到限制,导致作业启动失败或运行异常。常见问题包括: - 资源不足:YARN 队列的资源配额不足以支持作业启动。 - IP 地址不足:项目空间剩余的 IP 数量不足以满足 TaskManager 的需求。
建议操作: - 检查 YARN 队列的资源配额,确保有足够的内存和 CPU 资源分配给作业。 - 减少作业的并发度或合理配置槽位(slots),以降低资源需求。 - 如果 IP 地址不足,可以修改工作空间的虚拟交换机配置。
如果您的作业依赖自定义连接器(如 Flink CDC 连接器),但未将其正确上传到 OSS 或其他存储位置,可能会导致作业启动失败。
建议操作: - 确保所有自定义连接器已上传到 OSS,并在作业配置中正确引用。 - 检查连接器的版本是否与 Flink 1.18.1 兼容。
Flink 在生成 JobGraph 时,如果作业逻辑过于复杂,可能会导致 gRPC 消息超出默认大小限制(41943040 字节)。
建议操作: - 在作业的其他配置中添加以下参数,以增加 gRPC 消息的最大大小限制:
table.exec.operator-name.max-length: 1000
如果您在代码中依赖了 Flink 的内部 API(如 org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery),而这些 API 在阿里云版本中进行了优化,可能会导致包冲突或方法缺失。
建议操作: - 确保代码中仅调用 Flink 明确标注为 @Public 或 @PublicEvolving 的公开方法。 - 如果必须使用内部 API,请检查其版本兼容性,并考虑替换为官方推荐的替代方案。
为了进一步定位问题,可以通过以下方式获取更多调试信息: - 在 Python 自定义函数中添加日志输出,示例如下:
import logging
@udf(result_type=DataTypes.BIGINT())
def add(i, j):
logging.info("hello world")
return i + j
PYTHONPATH 中。可以通过 requirements.txt 文件管理依赖。根据上述分析,您可以按照以下步骤逐步排查问题: 1. 检查 Python 环境版本是否与 Flink 兼容。 2. 确保 YARN 队列资源充足,并合理配置并发度和槽位。 3. 确认自定义连接器已正确上传并引用。 4. 增加 gRPC 消息大小限制,避免因 JobGraph 过大导致的启动失败。 5. 避免使用 Flink 的内部 API,改用公开方法。 6. 添加日志输出,查看 TaskManager 日志以获取详细错误信息。
如果问题仍未解决,请提供具体的错误日志,以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

