
OCR中线上的是有的,但是github上面下载的Python代码不能正常调用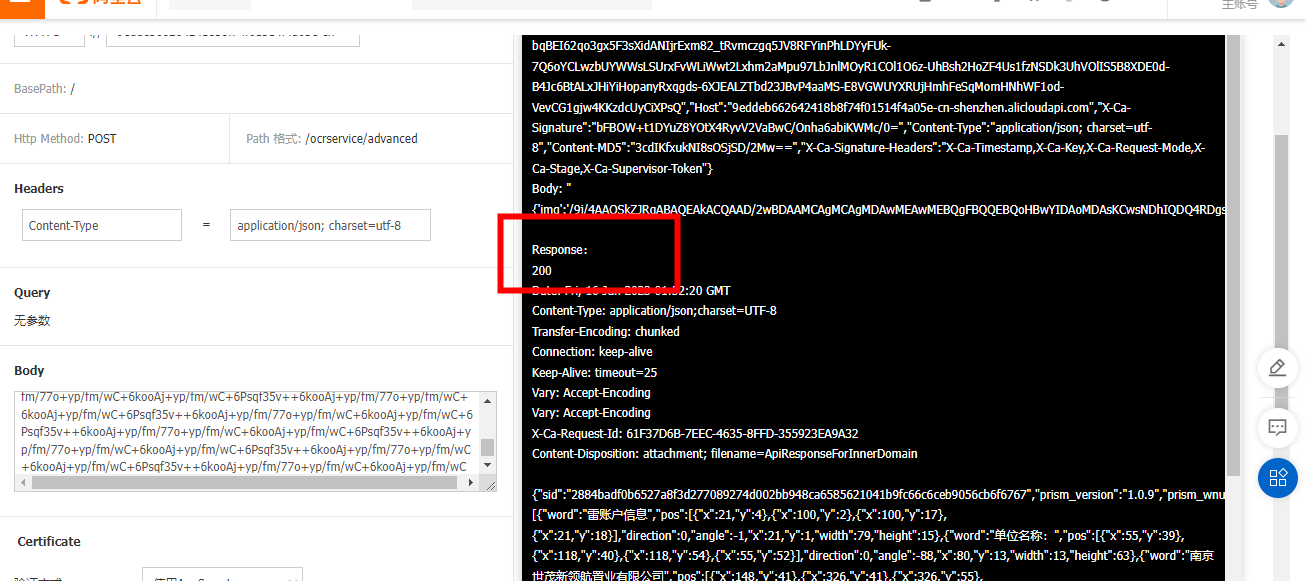 这个是代码的报错信息(403, [('Date', 'Fri, 16 Jun 2023 03:14:10 GMT'), ('Content-Type', 'application/oct-stream'), ('Content-Length', '0'), ('Connection', 'keep-alive'), ('Keep-Alive', 'timeout=25'), ('X-Ca-Error-Message', 'Invalid protocol http:// unsupported'), ('Server', 'Kaede/3.5.3.804 (sz00iotms)'), ('X-Ca-Error-Code', 'I403PT'), ('X-Ca-Request-Id', '408F4331-07AB-49CE-9AEE-7AB5EB78E2FA')], '')我觉得好像提供的代码里面缺少东西次数是有的
这个是代码的报错信息(403, [('Date', 'Fri, 16 Jun 2023 03:14:10 GMT'), ('Content-Type', 'application/oct-stream'), ('Content-Length', '0'), ('Connection', 'keep-alive'), ('Keep-Alive', 'timeout=25'), ('X-Ca-Error-Message', 'Invalid protocol http:// unsupported'), ('Server', 'Kaede/3.5.3.804 (sz00iotms)'), ('X-Ca-Error-Code', 'I403PT'), ('X-Ca-Request-Id', '408F4331-07AB-49CE-9AEE-7AB5EB78E2FA')], '')我觉得好像提供的代码里面缺少东西次数是有的 这段代码你们自己电脑上能跑出来吗?
这段代码你们自己电脑上能跑出来吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果使用的是线上的OCR服务,可能需要通过API接口进行调用。一般来说,API接口会有比较详细的文档和使用说明,可以根据文档和使用说明进行调用。如果没有文档和使用说明,可以联系OCR服务的客服或技术支持人员获取帮助。
如果使用的是从Github上下载的Python代码,可能需要安装相应的依赖库才能正常调用。可以先检查一下代码中使用的依赖库是否已经安装,如果没有安装,可以通过pip install命令进行安装。同时,也可以检查一下代码是否有错误或缺失的部分,如果有,可以尝试修复或补充代码。如果还是无法正常调用,可以考虑联系代码的作者或者寻找相关的问题解决方案。
您提供的代码是使用了Python的requests库发送HTTP请求,然后将响应内容解析为图片,并使用OCR模型进行识别。但是在使用时出现了403错误,这个错误通常表示您没有足够的权限访问请求的资源,或者是请求的资源不存在或已删除。 您需要检查一下您是否按照正确的步骤来使用这段代码,例如是否将在线OCR服务的API网址输入正确,是否将API认证信息输入正确,是否已经获得了对该API的访问权限等等。如果您按照正确的步骤来使用,但仍然出现403错误,那么您可以尝试联系在线OCR服务的技术支持团队,以获取更多帮助。
楼主你好,对于第一个问题,可能是因为接口返回数据编码不一致导致出现乱码。可以尝试在代码中设置合适的编码方式解决此问题,比如将返回的内容使用UTF-8进行解码。
对于第二个问题,如果您下载的Python代码不能正常调用,可能是由于环境配置或代码本身问题所致。您可以尝试检查代码是否缺少必要的依赖库、是否存在语法错误等。
根据你提供的错误信息,我发现是因为程序试图从一个http协议的链接中读取数据,但是该链接返回了一个错误的响应。
这可能是因为该链接不是一个有效的图片链接,或者该链接需要授权才能访问。
为了解决这个问题,你可以尝试以下几种方法:
检查图片链接是否正确。确认图片链接是否正确,是否可以在浏览器中正常访问。
确认图片链接是否需要授权。有些图片链接需要授权才能访问,你可以检查一下是否需要提供授权信息。
使用其他方式加载图片。如果图片链接无法访问,你可以考虑使用其他方式加载图片,例如使用Python的Pillow库加载本地图片。

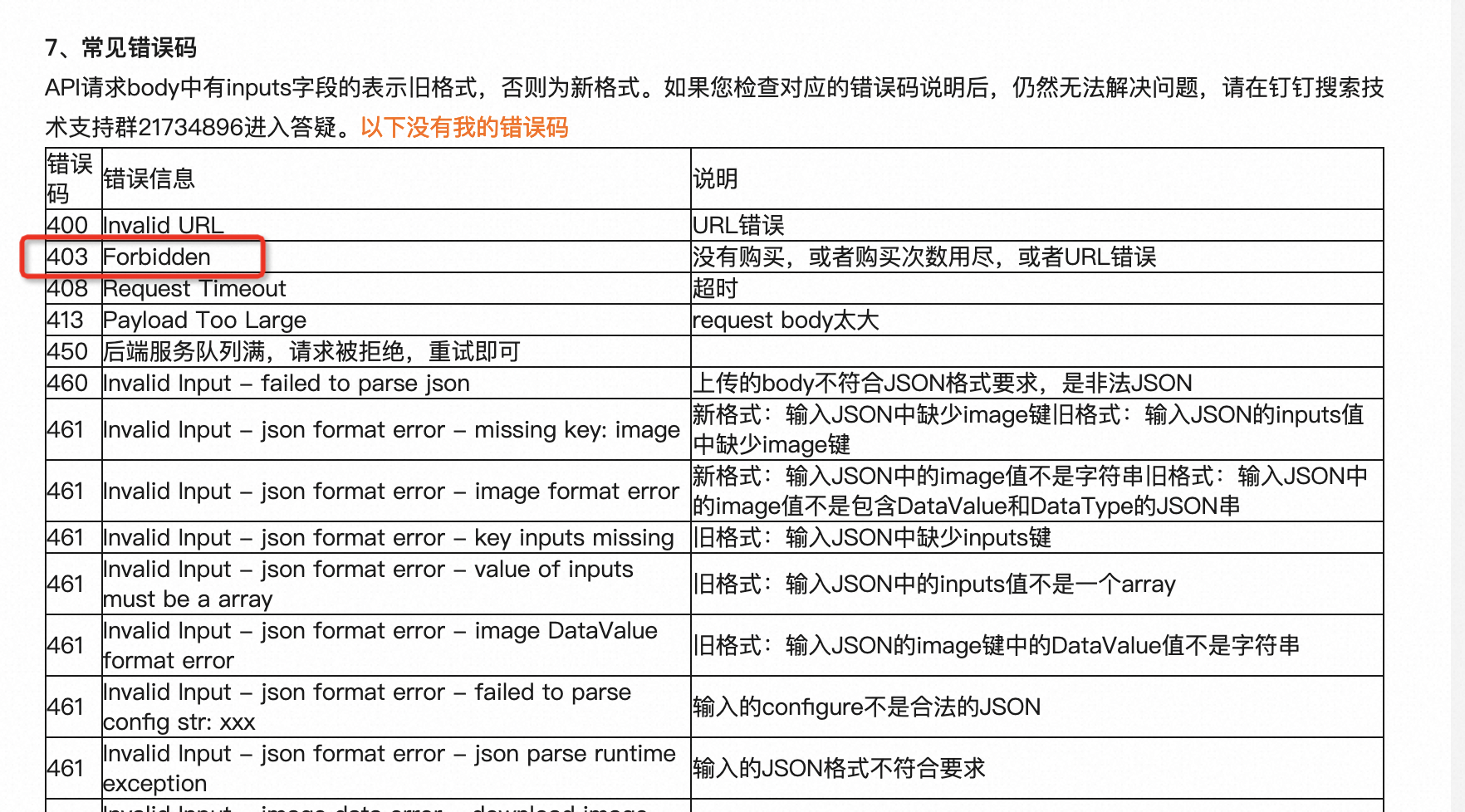 看错误日志,是不支持http协议,检查一下是不是url写错了,此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”
看错误日志,是不支持http协议,检查一下是不是url写错了,此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”
