
Flink中现在大数据组件,用docker部署 k8s管理的场景 多不多,比如计算flink spark 调度yarn 中间件kafka zk 存储clickhouse es mysql 我理解存储或者网络IO重的组件 不放在docker,因为性能比较差 其他可以都放?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink on K8S Native 部署架构,Flink Client 原生支持了 K8S Client,Job 提交后 Flink Client 会通过 K8S API Server 完成 ConfigMap、JobManager Deployment、Service 等资源的创建,然后 JobManager 中的 Resource Manager 模块会根据作业的资源需求与 K8S API Server 交互来进行资源的申请,完成 TaskManager Pod 的创建和销毁工作。
实际落地中,状态快照存储方面,保留小规模的 HDFS 集群,来尽可能地减少迁移和学习成本;高可用方面,也保留运维经验比较丰富的 Zookeeper 来作为过渡。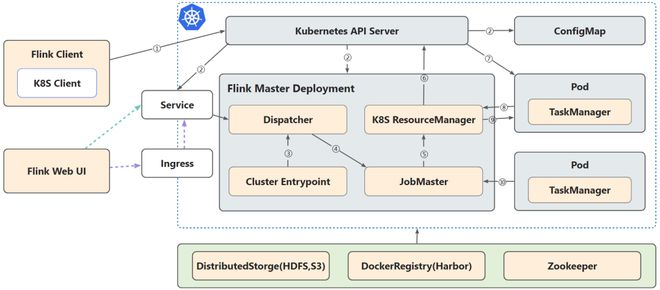
Flink 作业在启动或者 Failover 时,所有的 Pod 同时拉取作业文件资源,对 HDFS 等分布式存储性能要求较高。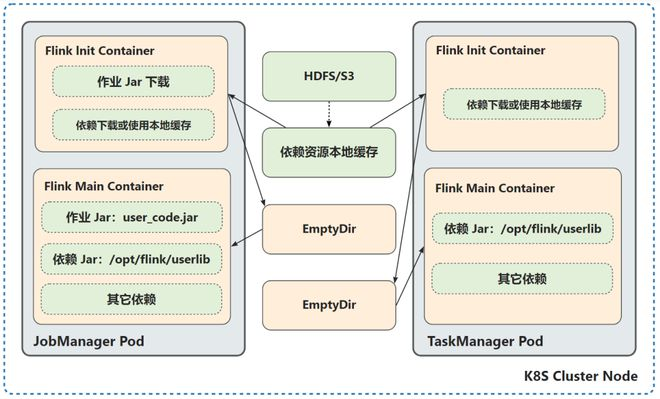
——参考链接。
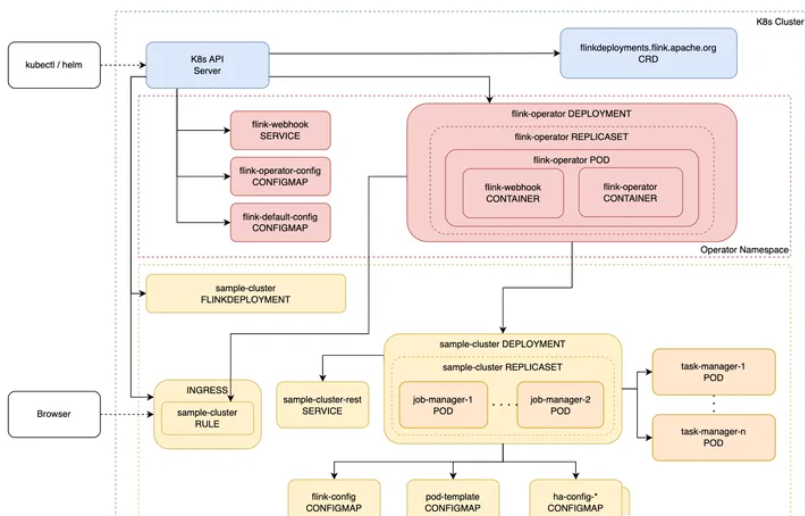
随着容器技术的发展,Kubernetes已经成为许多企业选择用来编排微服务架构的重要平台。在这个背景下,将大数据组件部署在Kubernetes上也越来越普遍。虽然一些高性能的存储和服务(如MySQL、ClickHouse)出于性能原因并不适合直接作为Kubernetes上的Pod运行,但在很多场景下,包括Flink在内的计算引擎和其他中间件都可以很好地适应Kubernetes环境。
以下是基于你的例子所涉及的大数据组件如何被部署在Kubernetes之上的简述:
计算引擎(如Flask Spark)
Flink和Spark都可以在Kubernetes上运行,它们既可以作为一个单独的服务部署,也可以集成到更复杂的流水线中。
用户可以选择官方提供的镜像,或者自定义构建符合特定要求的基础镜像。
调度器(如YARN)
Kubernetes本身就是一种调度器,因此不需要额外安装YARN或其他类似的调度器。
中间件(如Zookeeper、Kafka)
Zookeeper、Kafka这样的分布式协调服务同样可以部署在Kubernetes之上。这些组件通常会配合StatefulSet或Deployment等对象进行部署。
数据库(如ClickHouse、MySQL)
ClickHouse、MySQL这类关系型数据库更适合本地宿主机部署而非Docker化的部署方案。尽管如此,你仍然可以用Kubernetes的PersistentVolume功能挂载外部存储设备来存放这些数据库的数据。另外,还有一些云服务商提供了托管版的MySQL服务,这些服务能够更好地适配Kubernetes环境。
Elasticsearch
Elasticsearch是一种常见的搜索引擎,它可以方便地部署在Kubernetes平台上。Elasticsearch通常会被设计为StatefulSet类型的对象进行部署,以便保持数据的安全性。
MySQL/MariaDB
同样的道理也适用于MySQL或MariaDB这样的传统关系型数据库。它们不适合直接放入Docker容器中运行。相反,你需要借助Kubernetes的 PersistentVolume 功能来连接外部存储设备,从而安全可靠地存取数据。当然,也有一些云厂商提供了托管版本的MySQL服务,这些服务更加易于在Kubernetes环境中使用。
Redis/Cassandra/InfluxDB
Redis、Cassandra、InfluxDB都是NoSQL数据库的例子,它们可以轻松地部署在Kubernetes上。这些数据库通常也会被设计为StatefulSet的对象进行部署,以确保数据安全性。
总的来说,大多数大数据相关组件都能够良好地融入Kubernetes生态系统之中。关键在于正确选择合适的部署模型和技术栈组合,以充分利用Kubernetes的优势,同时也充分考虑各个组件的特点及其对性能的影响。
在现代云原生架构中,使用Docker和Kubernetes(K8s)部署大数据组件已成为一种常见的实践。Flink、Spark等计算引擎以及Yarn作为资源调度系统,确实常被部署在容器化环境中以实现更好的资源管理和弹性伸缩。
对于中间件如Kafka、ZooKeeper等,由于它们对稳定性和低延迟有较高要求,的确曾有人担心容器环境可能带来的额外开销会影响性能。然而,随着Docker和Kubernetes的优化以及持久化存储解决方案的成熟,越来越多的企业开始选择将这些服务容器化,并通过合理的资源配置、存储卷挂载以及集群管理策略来保证性能和稳定性。
例如:
尽管早期可能有所顾虑,但现在将大数据组件包括存储在内的几乎所有服务都纳入容器化管理的做法已经越来越普遍,关键在于合理设计和配置集群以充分利用Kubernetes的优势同时避免潜在的性能瓶颈。只要正确配置和调优,即使是对I/O敏感的服务也能在容器中获得良好的性能表现。
在Flink中,使用Docker部署并使用Kubernetes进行管理的场景越来越多。对于大数据组件,如计算(Flink、Spark)、调度(YARN)、中间件(Kafka、Zookeeper)、存储(ClickHouse、Elasticsearch、MySQL)等,可以将它们都放在Docker容器中进行部署和管理。
对于存储或网络IO较重的组件,由于性能要求较高,通常不建议将它们放在Docker容器中。这是因为Docker容器会引入一定的性能开销,包括网络IO和存储IO的额外开销。因此,这些组件通常会直接部署在物理机或者专用的高性能服务器上,以保证其性能表现。
总结起来,可以将计算、调度、中间件等轻量级的组件放在Docker容器中进行部署和管理,而将存储或网络IO较重的组件直接部署在物理机或高性能服务器上。这样可以充分利用Docker和Kubernetes的优势,同时保证系统的性能和稳定性。
在Flink中,使用Docker部署和Kubernetes管理的场景越来越多。Docker提供了一个轻量级、可移植的容器化解决方案,可以帮助用户更轻松地部署和管理Flink集群。而Kubernetes是一个强大的容器编排平台,可以自动化部署、扩展和管理容器化应用程序。
在您的场景中,计算Flink、Spark、调度Yarn等组件都可以放入Docker容器中。这是因为这些组件主要关注于处理逻辑和计算任务,对性能要求较高,而Docker可以较好地满足这一需求。
对于中间件Kafka、ZooKeeper、存储ClickHouse、Elasticsearch和MySQL等组件,您可以根据实际情况进行选择。如果这些组件主要关注于数据存储和网络IO,那么将它们放在Docker容器中可能会影响性能。在这种情况下,您可以考虑将这些组件部署在宿主机上,而不是放入Docker容器中。
总之,在Flink中使用Docker和Kubernetes管理的场景是可行的,可以根据组件的特性和性能需求进行合理的选择和部署。
在Flink中,使用Docker部署K8s管理的场景越来越多。对于大数据组件,如计算Flink、Spark、调度Yarn、中间件Kafka、Zookeeper、存储ClickHouse、Elasticsearch和MySQL等,可以将它们都放在Docker容器中进行部署和管理。
本文为您介绍实时计算Flink版的产品形态区别、发布状态及选型建议。https://help.aliyun.com/zh/flink/product-overview/service-types?spm=a2c4g.11186623.0.i92
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


