
我这边做一个flinkcdc断点续传测试,写代码之后打jar包运行,完全没问题。我设置了之后,关闭?
我这边做一个flinkcdc断点续传测试,写代码之后打jar包运行,完全没问题。我设置了savepoint之后,关闭任务,再用savepoint重启,重启之后报错,状态一直显示restarting?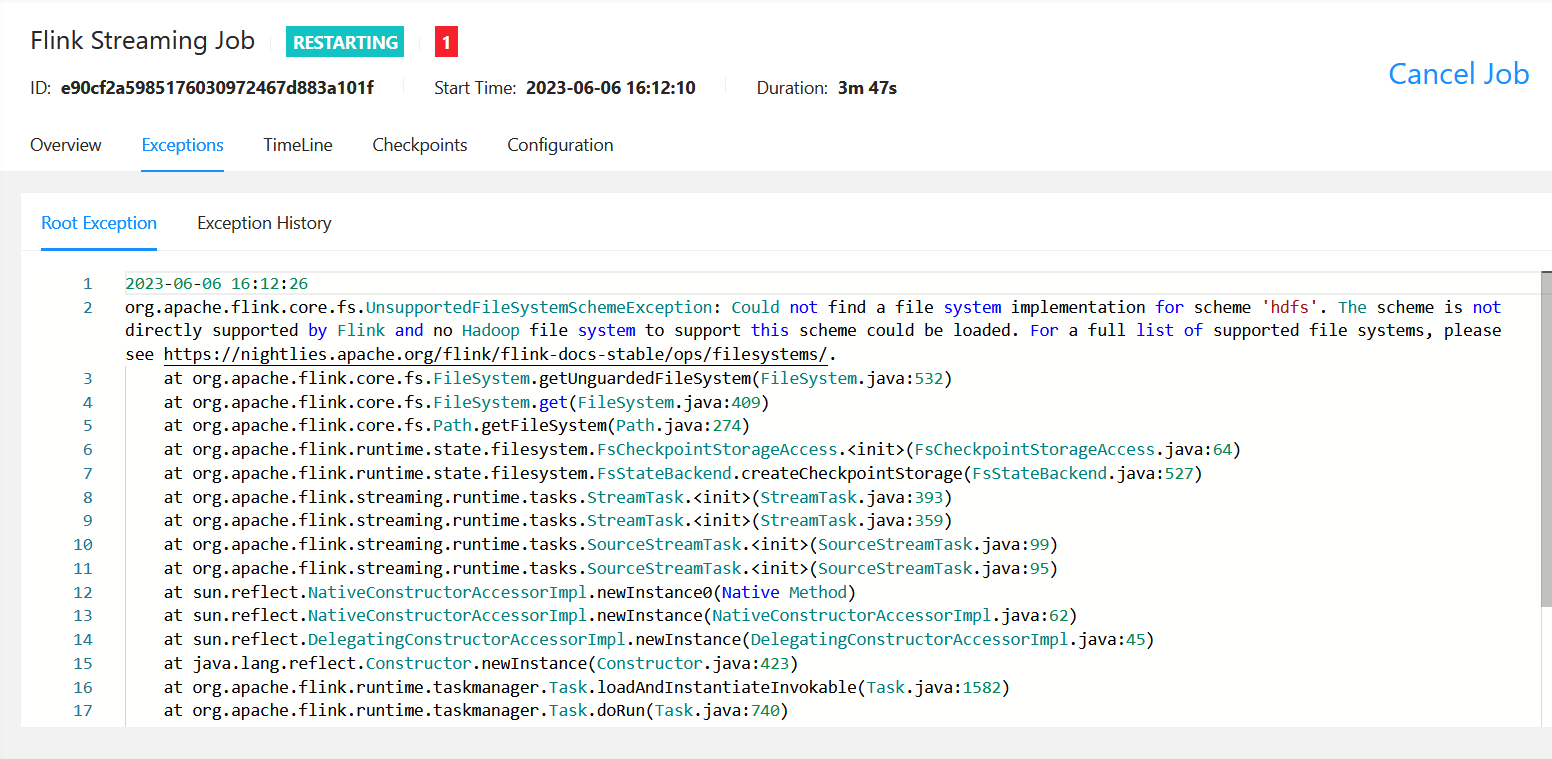 有大佬知道这个是什么原因吗?
有大佬知道这个是什么原因吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
根据您提供的信息,问题可能出在Flink任务使用HDFS作为文件系统时,Flink无法找到支持HDFS的FileSystem实现。这可能是由于Flink没有正确配置Hadoop的依赖项,或者您使用的Hadoop版本与Flink不兼容。
要解决这个问题,您可以尝试以下步骤:
1、确保您的Flink项目中包含了正确的Hadoop依赖项。您可以在Flink的官方文档中找到与您使用的Hadoop版本相对应的依赖项信息。
2、检查您的Hadoop版本是否与Flink兼容。如果不兼容,您需要升级或降级您的Hadoop版本,使其与Flink兼容。
3、检查Flink配置文件(例如flink-conf.yaml)是否正确配置了HDFS的相关参数,例如fs.hdfs.hadoopconf和fs.hdfs.impl。
4、如果您使用的是Flink的Standalone模式,请确保您的Flink集群配置正确,并且可以访问HDFS文件系统。
2023-08-22 23:14:25赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,这个问题可能有多种原因,请提供更多信息或日志,以帮助更好地解决。
以下是可能的原因和解决方法:
保存点(storepoint)可能无法从存储位置加载。尝试检查存储位置是否可用,或者从更稳定的存储位置重新创建一个保存点。
Flink任务可能在重启时遇到错误。可以通过查看日志文件获取更多信息,以确定问题所在。如果Flink任务重启失败,则可以尝试手动停止任务并重启。
Flink任务可能在重启时出现资源约束问题,例如内存不足或文件描述符限制。建议在重启之前检查资源使用情况,并相应地调整资源配置。
Flink任务可能与其它任务或服务发生冲突,例如端口号冲突或共享数据源问题。建议检查系统配置,并确保Flink任务没有与其它任务或服务发生冲突。最后可以排查一下参数:
2023-08-21 12:37:17赞同 展开评论 -
根据您提供的信息,这个问题可能是由于 Flink CDC 无法正确读取savepoint文件导致的。具体的原因可能是您在设置savepoint时指定的文件系统不被 Flink 支持。
以下是一些可能导致这个问题的原因和解决方法:
您在设置savepoint时指定的文件系统不被 Flink 支持。Flink 支持的文件系统包括本地文件系统、HDFS、S3 等。如果您使用的是其他文件系统,可能会导致 Flink CDC 无法正确读取保存点文件。您可以尝试使用 Flink 支持的文件系统来保存保存点文件。
您在启动 Flink CDC 时没有正确指定savepoint文件的位置。如果您在启动 Flink CDC 时没有正确指定savepoint文件的位置,可能会导致 Flink CDC 无法正确读取savepoint文件。您可以检查启动命令中是否包含正确的保存点文件路径。
savepoint文件已经损坏或者丢失。如果savepoint文件已经损坏或者丢失,可能会导致 Flink CDC 无法正确读取savepoint文件。您可以尝试使用其他savepoint文件或者重新创建savepoint文件。
2023-08-16 09:38:02赞同 展开评论 -
北京阿里云ACE会长
根据错误信息,您尝试使用Savepoint进行Flink CDC任务的断点续传时,可能遇到如下问题:
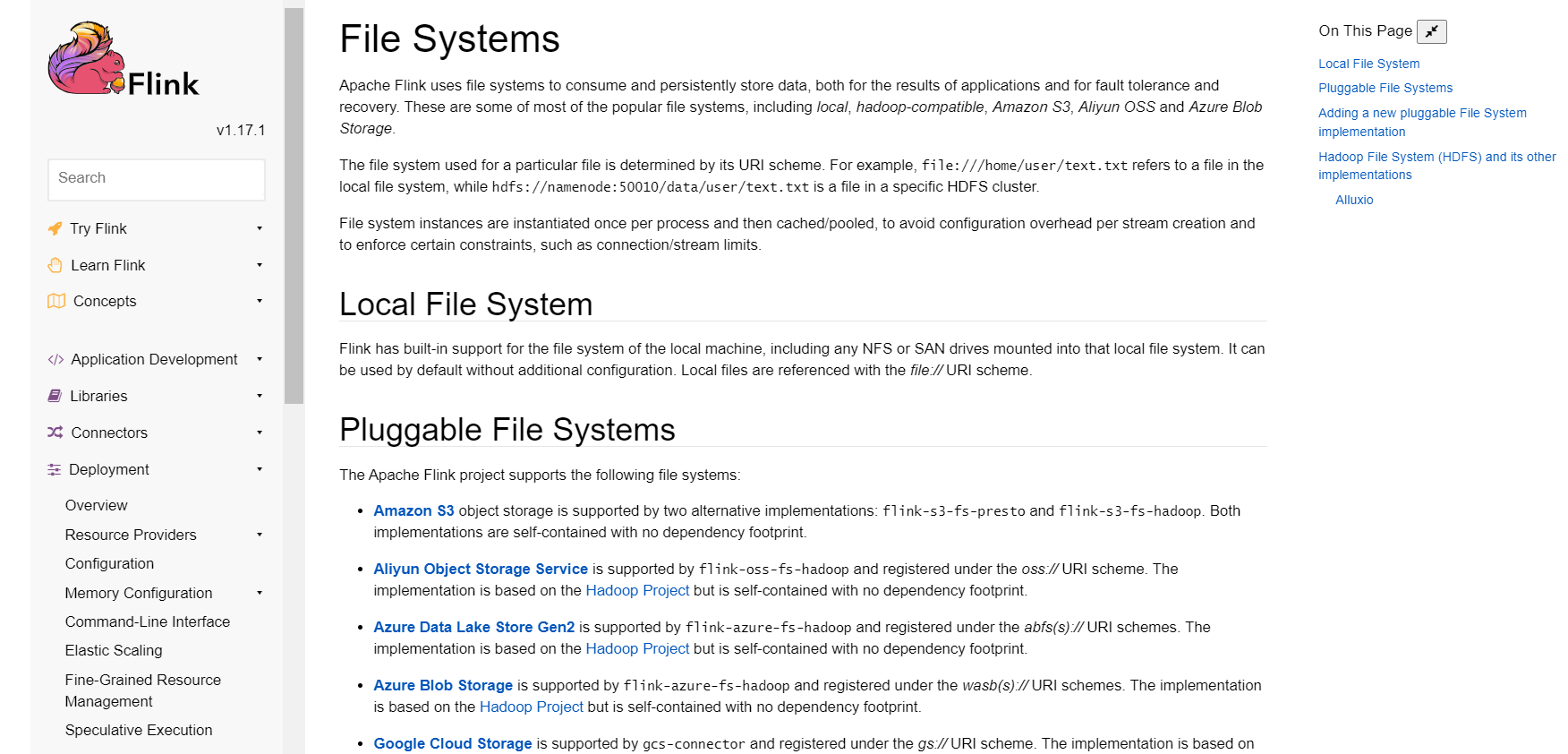
Savepoint持久化位置使用了"hdfs" scheme,而Flink本身不直接支持hdfs文件系统。
您的Flink环境中没有正确配置和类路径引入Hadoop客户端支持hdfs。
一般来说,要成功使用Savepoint进行任务恢复,需要满足一下条件:
Savepoint存放位置文件系统要与任务运行文件系统一致或兼容。
如果使用hadoop文件系统,需要正确集成hadoop客户端支持。
确认保存和加载Savepoint时任务运行环境一致。
清理之前残留的Savepoint文件避免重名导致加载失败。
打印日志调试Savepoint文件元数据是否完整。
尝试使用本地FS路径做测试以排除文件系统错误。
详细配置信息可以参考:https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/ ↗
2023-08-14 18:34:10赞同 展开评论 -
全栈JAVA领域创作者
如果您在使用Flink CDC进行断点续传测试时,设置了savepoint之后,关闭任务,再用savepoint重启,重启之后报错,状态一直显示restarting,那么可能是由于以下原因:
数据源表的数据结构发生了变化:如果您的数据源表的数据结构发生了变化,那么可能会导致Flink CDC无法正确读取和写入数据。在这种情况下,您需要在Flink CDC的配置文件中,指定数据源表的数据结构,以确保Flink CDC能够正确读取和写入数据。
数据源表的索引发生了变化:如果您的数据源表的索引发生了变化,那么可能会导致Flink CDC无法正确读取和写入数据。在这种情况下,您需要在Flink CDC的配置文件中,指定数据源表的索引,以确保Flink CDC能够正确读取和写入数据。
数据源表的字典发生了变化:如果您的数据源表的字典发生了变化,那么可能会导致Flink CDC无法正确读取和写入数据。在这种情况下,您需要在Flink CDC的配置文件中,指定数据源表的字典,以确保Flink CDC能够正确读取和写入数据。
需要注意的是,如果您在生产环境中使用Flink CDC进行断点续传测试,那么您需要考虑Flink CDC的资源使用情况。例如,您需要确保Flink CDC有足够的内存和CPU资源,以保证数据处理和同步的效率和稳定性。同时,您还需要确保Flink CDC的数据备份和恢复机制,以保证数据的安全性和可靠性。2023-08-14 13:39:07赞同 展开评论 -
从图片来看,你的Flink任务似乎遇到了一个错误,所以它被标记为"RESTARTING"。这通常意味着Flink正在尝试重新启动失败的任务。
至于为什么会出现这样的错误,有很多种可能的原因。以下是一些常见的可能性:
依赖项冲突:如果你在不同的JVM实例之间共享依赖项,就可能会发生这种情况。例如,两个不同的JVM实例可能同时加载了一个相同的类库的不同版本。
资源竞争:当多个任务试图访问同一个资源(如文件或数据库连接)时,可能会发生资源竞争。
外部服务调用:当你在Flink任务中调用外部服务时,可能会遇到各种问题,比如超时、服务不可用等等。
数据源问题:如果你使用的是自定义的数据源实现,就有可能遇到问题。
代码逻辑错误:最有可能的情况就是你在代码中有逻辑错误,导致任务出错。
2023-08-14 10:59:47赞同 展开评论
