
Flink CDC中有谁知道请问2.3版本默认还是走的全局锁对吧?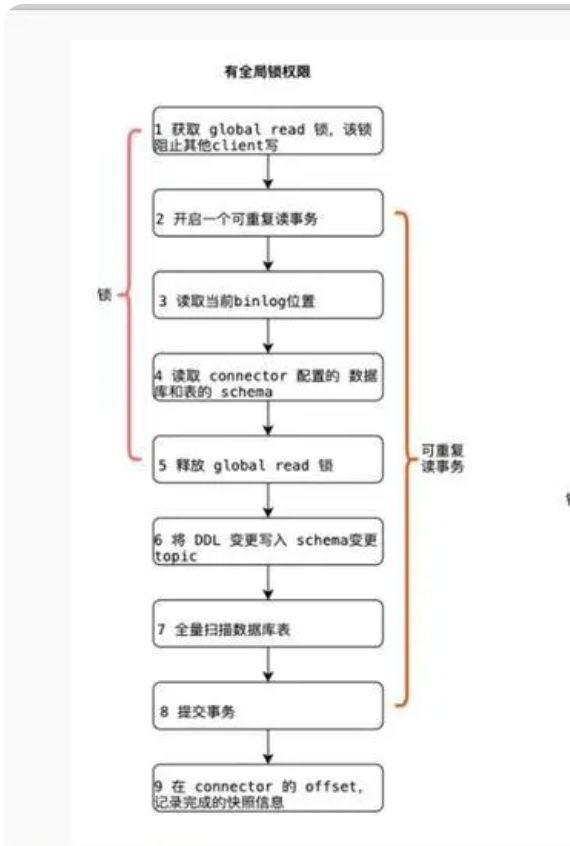
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC 2.3版本中,默认情况下仍然会使用全局锁(Global Lock)来保证数据一致性。这是因为在全量阶段(Snapshot Phase),为了确保读取的数据一致性,Flink CDC会对表加全局锁以防止数据在读取过程中被修改。
全局锁的主要目的是在全量数据同步阶段避免数据的并发修改,从而保证数据的一致性。然而,这种机制可能会对数据库的性能产生一定影响,尤其是在高并发写入的场景下。
如果您希望避免全局锁的影响,可以通过以下方式跳过Snapshot阶段,直接从增量阶段(Binlog Phase)开始读取数据: 1. 配置参数:在创建CDC表时,通过设置'scan.startup.mode' = 'latest-offset',可以跳过全量阶段,直接从最新的Binlog位置开始读取。
CREATE TABLE mysql_cdc_table (
id INT,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'your-hostname',
'port' = '3306',
'username' = 'your-username',
'password' = 'your-password',
'database-name' = 'your-database',
'table-name' = 'your-table',
'scan.startup.mode' = 'latest-offset'
);
注意:这种方式会丢失全量数据,仅适用于不需要全量同步的场景。
如果必须使用全局锁,建议采取以下措施减轻对数据库的影响: - 低峰期执行:将全量同步任务安排在业务低峰期执行,减少对在线业务的影响。 - 分库分表:对于大规模数据,可以通过分库分表的方式分散锁的影响范围。 - 调整锁粒度:部分数据库支持调整锁的粒度(如表级锁或行级锁),可以根据实际情况进行优化。
Flink CDC 2.3版本默认仍会使用全局锁来保证全量数据的一致性。如果需要避免全局锁的影响,可以通过配置scan.startup.mode跳过全量阶段,或者结合手动导出和增量同步的方式实现数据同步。在实际使用中,请根据业务需求权衡数据一致性和性能之间的关系。
