
Flink CDC整库写入tidb运行一段时候后经常报这个错误,有人知道是什么原因?已知不是连接空闲超时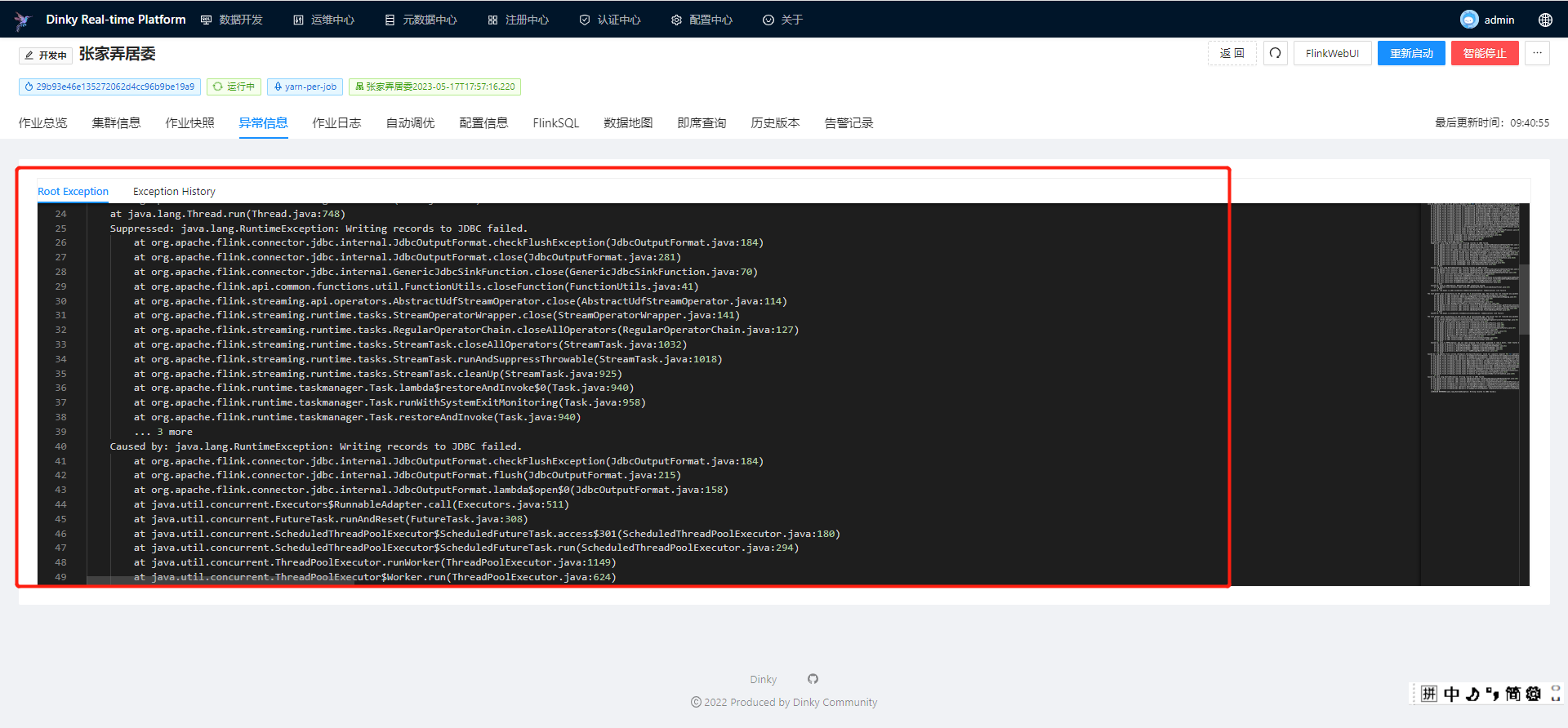
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC整库写入TiDB运行一段时间后经常报错,并且已知问题并非由连接空闲超时引起。以下是可能的原因分析及解决方案,基于知识库中的相关资料进行总结和建议:
问题原因:
Flink CDC依赖MySQL的Binlog来捕获增量数据变更。如果MySQL服务器上的Binlog保留时间过短(例如默认的expire_logs_days值较小),可能会导致Flink CDC作业在Failover或重启时无法找到之前记录的Binlog位点,从而报错。
解决方案:
- 延长MySQL的Binlog保留时间,例如设置为7天:
SHOW VARIABLES LIKE 'expire_logs_days';
SET GLOBAL expire_logs_days=7;
问题原因:
如果下游TiDB的写入性能不足(例如高并发写入、索引维护开销大等),可能导致Flink作业出现反压,进而影响CDC Source的消费速度。当反压传递到Source端时,可能会导致Binlog消费延迟或失败。
解决方案:
- 优化TiDB写入性能: - 检查TiDB的表结构设计,避免过多的二级索引。 - 调整TiDB的写入参数,例如tidb_batch_insert和tidb_dml_batch_size。 - 优化Flink作业资源: - 增加Flink TaskManager的并行度或内存资源。 - 调整Flink的Checkpoint间隔和超时时间,避免因Checkpoint失败导致作业不稳定: yaml execution.checkpointing.interval: 10min execution.checkpointing.tolerable-failed-checkpoints: 100
问题原因:
在Flink CDC运行过程中,如果上游MySQL表结构发生了不兼容的变更(例如新增列、修改主键等),可能会导致作业报错或无法继续同步。
解决方案:
- 停止并重新启动作业: 1. 停止当前Flink CDC作业。 2. 删除下游TiDB中对应的表。 3. 无状态地重新启动Flink CDC作业,重新同步全量数据。 - 避免不兼容的表结构变更: - 在同步期间尽量避免对表结构进行重大修改。 - 如果必须修改表结构,请确保变更兼容(例如新增列允许NULL值)。
问题原因:
Flink CDC底层依赖Debezium解析MySQL的Binlog。如果Binlog中包含Debezium无法解析的变更事件(例如DEFAULT (now())),可能会导致作业报错。
解决方案:
- 检查日志定位具体问题: - 查看Flink作业日志中io.debezium.connector.mysql.MySqlSchema WARN级别的日志,确认具体的解析异常。 - 调整Debezium配置: - 设置debezium.inconsistent.schema.handling.mode为warn,避免因解析异常直接导致作业失败: properties debezium.inconsistent.schema.handling.mode = warn
问题原因:
Flink CDC要求源表必须定义主键,否则在启用增量快照功能时会报错。
解决方案:
- 确保MySQL源表定义了主键。 - 如果无法修改表结构,可以在Flink SQL中显式指定主键:
CREATE TABLE source_table (
id INT,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
...
);
问题原因:
在非正常情况下(例如网络抖动或故障恢复),Debezium可能会投递重复的变更事件到Kafka中,导致Flink作业消费时出现重复数据或异常。
解决方案:
- 启用Flink的去重机制: - 在作业参数中设置table.exec.source.cdc-events-duplicate为true。 - 确保源表定义了主键,以便Flink生成有状态算子对重复事件进行去重。
网络连通性问题:
如果Flink与TiDB之间的网络存在延迟或抖动,也可能导致写入失败。建议检查网络连通性,并确保Flink能够稳定访问TiDB。
Task退出超时:
如果作业在Failover或退出过程中长时间阻塞,可能会触发Task did not exit gracefully错误。建议排查自定义函数实现是否存在阻塞操作,并适当调整task.cancellation.timeout参数。
根据上述分析,建议您按照以下步骤逐步排查和解决问题: 1. 检查MySQL的Binlog保留时间,确保位点不会因清理而丢失。 2. 优化下游TiDB的写入性能,避免反压影响CDC Source。 3. 确保表结构变更兼容,必要时重新启动作业。 4. 检查Debezium解析日志,调整相关配置以避免解析异常。 5. 确保源表定义了主键,并启用Flink的去重机制。
如果问题仍未解决,请提供具体的错误日志信息,以便进一步分析和定位问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
