
大佬,Flink CDC提交集群的会把依赖包都打在自己的jar包里吗?然后就报错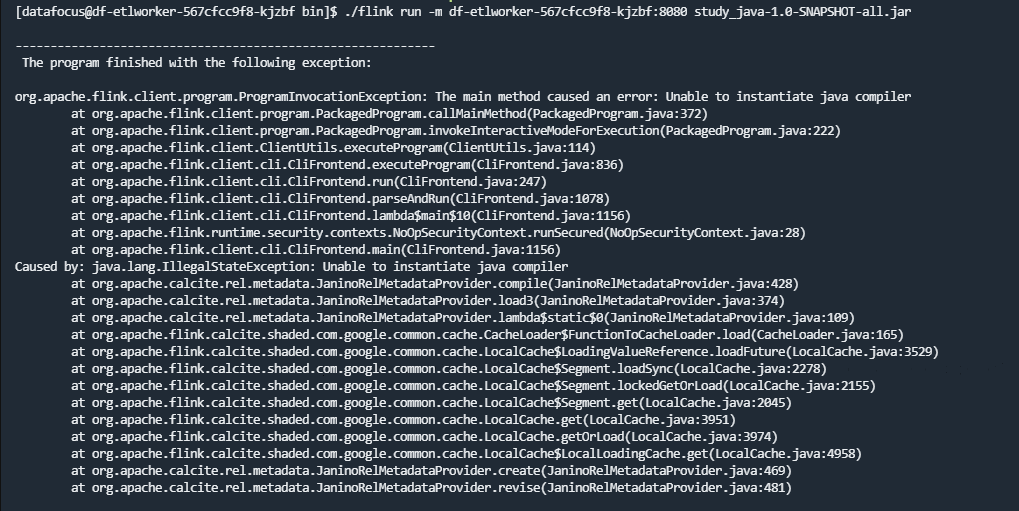
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 提交集群时,是否会将依赖包打包到自己的 JAR 包中,以及是否会导致报错,取决于您选择的连接器类型和打包方式。以下是详细说明:
根据知识库中的描述,Flink CDC 连接器分为以下两种类型: - flink-sql-connector-xxx
- 这是一个 FAT JAR,包含了连接器的所有代码及其依赖的第三方库(通过 Shade 打包)。 - 适用于 SQL 作业,用户只需将该 JAR 放入 lib 目录即可直接使用。 - 优点:无需额外管理依赖。 - 缺点:如果多个 FAT JAR 中包含相同的依赖,可能会导致依赖冲突。
flink-connector-xxx
因此,如果您使用的是 flink-sql-connector-xxx,所有依赖会被打包到一个 JAR 中;而使用 flink-connector-xxx 则不会。
当依赖被打包到 JAR 中时,可能会引发以下问题:
flink-sql-connector-xxx),这些 JAR 可能会包含相同但版本不同的第三方依赖(例如 log4j 或 janino),从而导致类加载冲突。java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactoryInvocationTargetException 导致 Slot 分配失败。flink-connector-xxx,但未正确声明依赖或未将依赖上传到集群,可能会导致运行时找不到类或方法。Can't find any matched tables, please check your configured database-name: xxx and table-name: xxxxEncountered change event for table xxx.xxx whose schema isn't known to this connectorMETA-INF/services 文件或其他资源文件,可能会导致连接器无法正常工作。NoResourceAvailableExceptionCannot allocate the requested resources为了避免上述问题,您可以采取以下措施:
flink-sql-connector-xxx,并确保只引入一个 FAT JAR。flink-connector-xxx,并通过 Maven 管理依赖。mvn dependency:tree 命令查看依赖树,检查是否存在重复或冲突的依赖。jar tf foo.jar 查看 JAR 包内容,确认是否有重复的类。pom.xml 中使用 <exclusions> 排除不必要的依赖。例如:<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
log4j),可以使用 maven-shade-plugin 将其重定位(Relocation)。例如:<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<relocations>
<relocation>
<pattern>org.apache.log4j</pattern>
<shadedPattern>com.shaded.log4j</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
classloader.parent-first-patterns.additional 参数来调整类加载顺序。例如:
classloader.parent-first-patterns.additional: org.codehaus.janino
flink-connector-xxx,需要将依赖的 JAR 文件上传到 Flink 集群,并在作业配置中指定路径。例如:
pipeline.classpaths: 'file:///flink/usrlib/jar1.jar;file:///flink/usrlib/jar2.jar'
vvr-8.0.9-flink-1.17 引擎对应 Flink 1.17.2。flink-streaming-java),应将其作用域设置为 provided。flink-sql-connector-xxx,依赖会被打包到 JAR 中,但可能引发依赖冲突。flink-connector-xxx,需要手动管理依赖,避免遗漏或冲突。希望以上解答能够帮助您解决问题!您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
