
请教下,FlinkCDC 同步oracle11g到mysql,需要怎么设置log.mining.ba
请教下,FlinkCDC 同步oracle11g到mysql,需要怎么设置log.mining.batch.size.max的值?现在试了10w,100w,任务运行6个小时后,cdc就没效果了,会提示以下信息?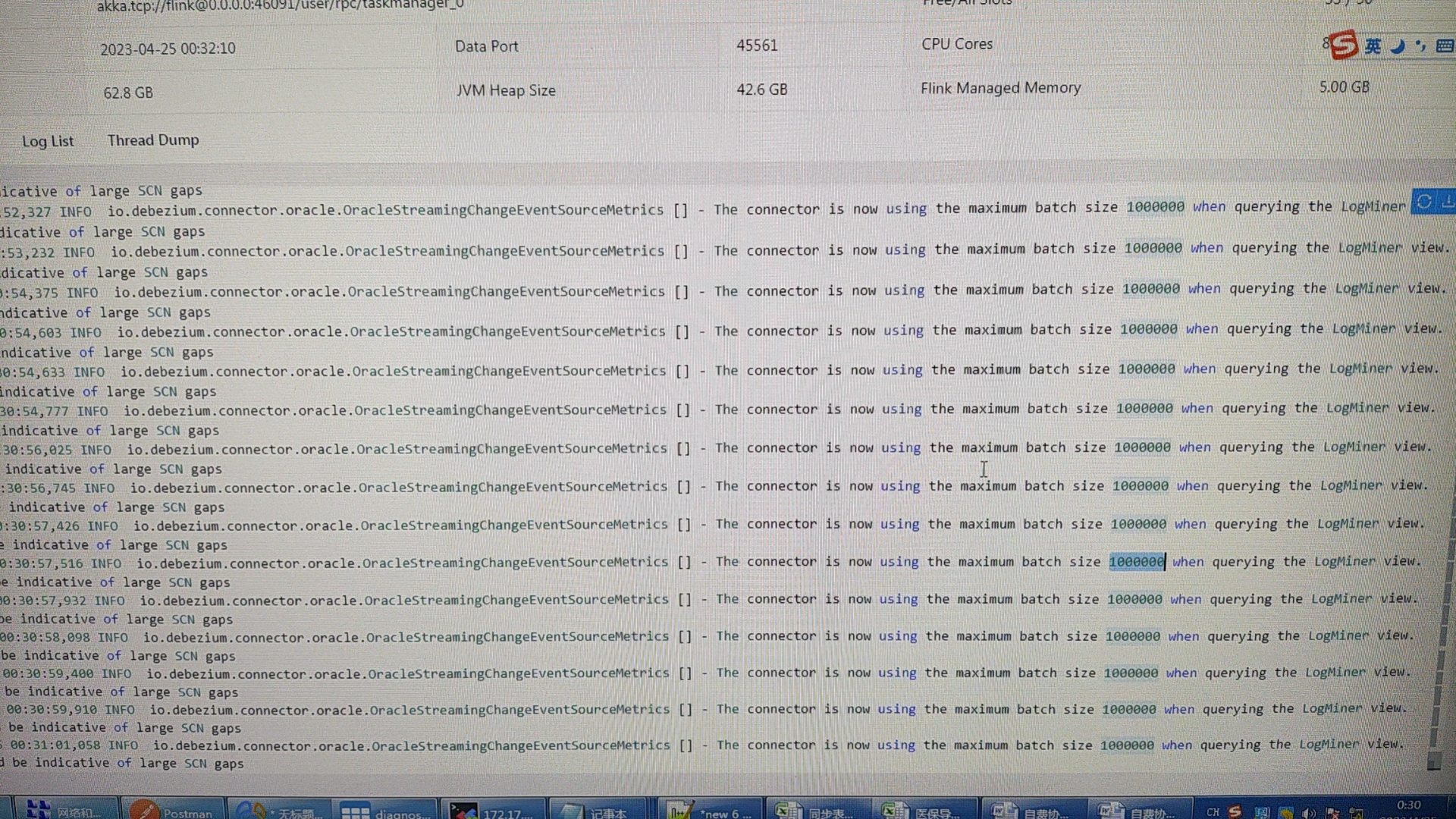 昨天晚上调整成1000w后,cdc任务已经坚持了10个小时了
昨天晚上调整成1000w后,cdc任务已经坚持了10个小时了
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
FlinkCDC将Oracle 11g同步到MySQL,并且在设置log.mining.batch.size.max的值时遇到了问题。根据情况,这个值的设置可能需要根据具体的环境和需求进行调整。
log.mining.batch.size.max是Oracle LogMiner的一个参数,它控制了每个批次处理的最大事务数。较小的值可能会导致频繁的提交,而较大的值可能会导致内存消耗过高或处理时间延长。
在您的情况下,您已经尝试了10万和100万作为log.mining.batch.size.max的值,但任务在运行6个小时后CDC功能失效。这可能是由于以下原因导致的:
1、内存不足:较大的log.mining.batch.size.max值可能导致内存消耗过高,超出了系统的可用内存。您可以尝试减小这个值,以减少内存消耗。
2、日志挖掘延迟:当批处理大小较大时,LogMiner在处理事务时可能会导致一定的延迟。如果Oracle的日志产生速度过快,可能会导致CDC无法及时处理所有的日志。您可以尝试增大log.mining.batch.size.max的值,以提高处理速度。
3、Oracle日志配置:请确保Oracle数据库的日志配置正确,并且日志模式允许进行CDC操作。您可以检查Oracle数据库的日志模式设置、归档日志是否开启以及日志保留时间等参数。
如果以上方法仍然无法解决问题,建议您考虑以下步骤:
1、监控任务日志:查看Flink任务的日志,了解具体的错误或异常信息,以便更好地定位问题。
2、调整其他参数:除了log.mining.batch.size.max之外,还可以尝试调整其他相关参数,如FlinkCDC的并行度、MySQL目标表的配置等。
总的来说,log.mining.batch.size.max的值需要根据具体的场景和需求进行调整。您可以根据系统资源、日志产生速度和任务性能等因素进行测试和优化,以找到合适的值来确保CDC功能的稳定和可靠性。
2023-08-26 20:02:58赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,log.mining.batch.size.max是指定Oracle CDC解析binlog的批处理大小。该参数的值应该根据你的数据集大小和机器配置来进行设置。如果你设置的值太小,Oracle CDC会更频繁地发送binlog事件到Flink任务,这会增加任务的开销。如果你设置的值太大,则可能会导致内存不足或请求超时等问题。
任务运行6个小时后,CDC停止解析binlog可能是因为Binlog的时间范围或大小超出了Oracle的默认设置,或者是因为Oracle日志文件的数量达到了Oracle的最大数量限制。
建议你检查Oracle的CDC捕获日志是否有删除或轮换,此外还可以尝试增大log.mining.batch.size.max的值,同时在CDC配置中设置binlog最大存储时间来避免binlog文件过大。
2023-08-21 14:28:40赞同 展开评论 -
在使用 Flink CDC 同步 Oracle 11g 数据库到 MySQL 时,您需要合理地设置
log.mining.batch.size.max参数的值。这个参数用于控制每个批次从 Oracle 日志中读取的最大数量。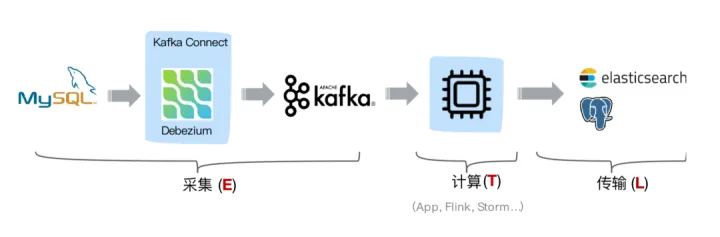
当设置的值过大时,可能会导致 CDC 任务在读取数据时超出可接受的处理能力,从而引起任务性能下降或超时。另一方面,如果设置的值过小,则可能会导致每个批次读取的数据量过少,造成不必要的网络开销和额外的延迟。
要设置
log.mining.batch.size.max的值,需要考虑以下几个因素:数据变更速率:根据 Oracle 数据库的变更速率评估每个批次应包含的变更记录数量。如果变更速率很高,可以适当调高该值,以便更有效地利用资源。
任务处理能力:考虑 Flink CDC 任务所运行的机器的计算和网络资源,以及任务所分配的 CPU 和内存等配置。确保为任务提供足够的资源来处理每个批次的数据。
目标数据库的吞吐量:根据目标 MySQL 数据库的性能特点和可接受的写入吞吐量,确定每个批次写入 MySQL 的数据量。避免将过多的数据同时写入 MySQL 数据库造成负载过高或性能下降。
根据您提供的情况,如果在运行了6个小时后出现 CDC 任务停止同步的问题,并且提示相关信息,那么可能还有其他原因导致任务停止。您可以检查 Flink CDC 任务的日志和错误信息,以查找更具体的问题。
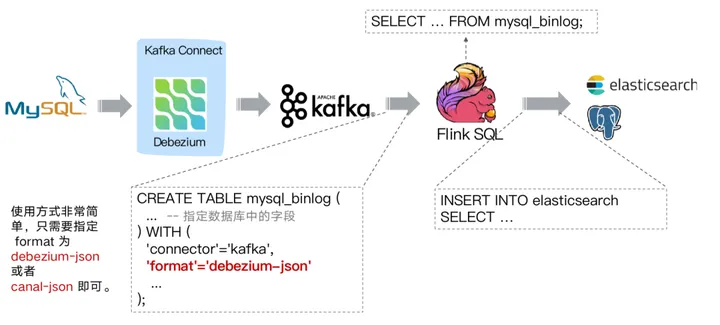
此外,请确保 Oracle 数据库的日志模式设置正确,并且 Flink CDC 的配置与 Oracle 数据库的连接参数、权限和日志模式相匹配。
2023-08-17 20:14:49赞同 展开评论 -
根据你的描述,你需要调整 log.mining.batch.size.max 参数的值来控制 Flink CDC 任务对 Oracle 数据库的数据采集速率。如果你的任务在运行一段时间后停止工作,并出现如下错误信息:
[main] ERROR org.apache.flink.api.common.Collector - Failed to collect data within the time limit. Data may be lost.这通常意味着 Flink CDC 任务无法在指定的时间内收集到足够的数据,因此无法生成有效的数据输出。在这种情况下,你可以尝试增加 log.mining.batch.size.max 参数的值,以便 Flink CDC 任务能够更快地收集到足够的数据。
然而,需要注意的是,如果你将 log.mining.batch.size.max 参数的值设置得过高,可能会导致 Flink CDC 任务对数据库的写入操作变得过于频繁,从而影响数据库的性能。因此,你需要根据实际情况进行调整,以找到一个适合你的应用场景的最佳值。
在你的情况下,你已经尝试了多个不同的值,但是没有得到满意的结果。因此,你可以尝试将 log.mining.batch.size.max 参数的值设置为更高的值,例如 1000w,以查看是否能够提高任务的性能。当然,你也需要密切监视任务的性能和数据库的性能,以确保任务不会对数据库造成过大的负载。
2023-08-17 14:10:49赞同 展开评论 -
北京阿里云ACE会长
在使用 Flink CDC 同步 Oracle 11g 到 MySQL 时,log.mining.batch.size.max 是一个重要的参数,它用于控制 Flink CDC 每次从 Oracle 的 Redo Log 中读取的最大批次大小。根据你的描述,任务在运行 6 个小时后出现了问题,可能是由于批次大小设置不合适导致的。你可以根据以下建议来设置 log.mining.batch.size.max 的值:
考虑 Oracle 11g 数据库的性能和资源情况:在确定批次大小之前,需要考虑 Oracle 11g 数据库的性能和资源情况。如果数据库的负载较高或资源有限,你可能需要设置较小的批次大小,以避免对数据库性能产生过大的影响。
调整批次大小:根据你的描述,试过 10 万和 100 万的批次大小后出现了问题。你可以尝试使用一个介于这两个值之间的较小批次大小,例如 50,000 或者 80,000,然后观察任务的运行情况。通过逐步调整批次大小,你可以找到一个合适的值,既能满足同步需求,又不会给 Oracle 数据库带来过大的负载。
监控任务运行情况:在设置批次大小后,建议密切观察任务的运行情况。特别关注任务是否能够持续进行 CDC 操作,并且没有出现延迟或者失败的情况。如果任务仍然出现问题,你可能需要进一步调整批次大小或者根据日志信息进行故障排查。
需要注意的是,批次大小的设置是一个权衡过程,取决于具体的场景和资源限制。你可能需要进行多次尝试和调整,以找到最佳的批次大小值。
2023-08-14 18:58:45赞同 展开评论 -
根据你提供的图片,看起来你的Flink CDC任务在运行了大约6个小时后停止了。这可能是由于以下原因导致的:
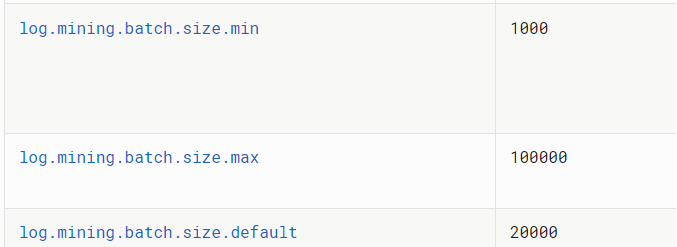
Log Mining Batch Size Max设置得太小:Log Mining Batch Size Max是Flink CDC的一个重要参数,它决定了每个批次处理的数据量。如果这个参数设置得太小,那么Flink CDC可能会在处理大量数据时遇到困难,导致任务暂停。为了解决这个问题,你可以尝试增加这个参数的值,例如从10W增加到100W或更大。
数据库连接出现问题:有时候,数据库连接可能会出现问题,导致Flink CDC无法继续处理数据。为了解决这个问题,你可以检查一下你的数据库连接是否仍然有效,以及是否有其他进程正在使用相同的数据库连接。
数据源出现问题:有时候,数据源可能会出现问题,导致Flink CDC无法继续处理数据。为了解决这个问题,你可以检查一下你的数据源是否仍然可用,以及是否有其他进程正在使用相同的数据源。
系统资源不足:如果你的系统资源(如内存、CPU、磁盘空间等)不足以支持Flink CDC的运行,那么任务可能会被暂停。为了解决这个问题,你可以尝试增加系统的资源分配,或者优化你的任务配置。
任务调度策略:Flink CDC的任务调度策略可能会影响任务的运行时间。你可以尝试调整任务的调度策略,以便更好地适应你的需求。

2023-08-14 15:01:13赞同 展开评论 -
全栈JAVA领域创作者
根据您提供的图片,您在使用Flink CDC同步Oracle11g到MySQL时,任务运行6个小时后,出现了log.mining.batch.size.max参数设置过小的问题。这个问题可能是由于您的Flink CDC任务处理速度过慢,导致任务队列中的任务越来越多,最终导致任务无法正常执行。
为了解决这个问题,您可以尝试以下方法:调整log.mining.batch.size.max参数:您可以调整log.mining.batch.size.max参数,以指定Flink CDC从源数据库中读取数据的批量大小。一般来说,您可以根据您的数据量和任务处理速度,调整log.mining.batch.size.max参数的值。例如,如果您的数据量较大,那么您可以适当增加log.mining.batch.size.max参数的值,以提高任务处理速度。
调整fetchInterval参数:您可以调整fetchInterval参数,以指定Flink CDC从源数据库中读取数据的频率。一般来说,您可以根据您的数据量和任务处理速度,调整fetchInterval参数的值。例如,如果您的数据量较大,那么您可以适当减小fetchInterval参数的值,以提高任务处理速度。
调整batchSize参数:您可以调整batchSize参数,以指定Flink CDC写入目标数据库的数据批量大小。一般来说,您可以根据您的数据量和任务处理速度,调整batchSize参数的值。例如,如果您的数据量较大,那么您可以适当增加batchSize参数的值,以提高任务处理速度。
使用增量同步:如果您的Oracle数据库中存在增量数据,那么您可以使用Flink CDC的增量同步功能,以优化数据同步速度。具体来说,您可以在Flink CDC的配置文件中,指定增量同步的参数,以便Flink CDC只读取和写入增量数据。
需要注意的是,不同的情况可能需要不同的解决方案,因此需要根据具体情况进行调整和优化。同时,您可以使用Flink CDC提供的TableFunction接口,自定义一个TableFunction实现类,对读取到的数据进行特殊过滤,以避免出现表字段变少的情况。2023-08-14 13:21:05赞同 展开评论
