
你好,麻烦问下机器学习PAI-命令方式训练LR模型,在哪可以查询LR模型训练好的参数呢 PAI -name logisticregression_binary -project algo_public -DmodelName="xlab_m_logistic_regression_6096" -DregularizedLevel="1" -DmaxIter="100" -DregularizedType="l1" -Depsilon="0.000001" -DlabelColName="y" -DfeatureColNames="pdays,emp_var_rate" -DgoodValue="1" -DinputTableName="bank_data"比如这样的pai命令 怎么查看训练好的LR模型的参数
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
使用PAI命令行进行模型训练时,训练好的模型参数通常会被保存在PAI平台上,可以通过PAI Web控制台或者OSS等云存储服务来获取这些参数。以下是具体步骤:
登录阿里云官网,进入PAI控制台。
在左侧导航栏中选择“项目列表”,进入项目列表页。
找到你的项目,并进入该项目的界面。
选择“数据”标签页,可以看到上传的数据和训练生成的模型。
找到对应的模型名字,单击该名称进入模型详情页。
在模型详情页中,找到模型的输出路径,例如“oss://your-bucket/logistic_regression/output/model/”。这个路径指向了模型参数在OSS上的存储位置。
打开OSS控制台,在对象存储桶中找到对应的文件夹,即可查看训练好的LR模型参数。具体格式可能因实际情况而异。
需要注意的是,某些模型可能无法直接读取参数文件,需要使用相应的工具将其转换为可读取的格式,以方便后续的模型预测和应用。
阿里云机器学习平台是构建在阿里云是构建在阿里云Maxcompute计算平台之上,集数据处理,建模,离线预测,在线预测为一体的机器学习平台。阿里云机器学习封装了阿里巴巴集团内成熟的算法,向机器学习用户提供了更简易的操作体验。
该智能平台主要分为三层:
第一层:web UI界层;
第二层:机器学习算法层;
第三层:Maxcompute平台层。
数据准备阶段,机器学习平台底层支持两种数据源,一种是MaxCompute存储数据,另一种是OSS存储数据。
注意:使用MaxCompute作为存储,建议当数据小于20MB时使用机器学习IDE环境上传,当数据大于20MB时使用命令行工具上传。
开通机器学习PAI,并且创建项目,开通时注意自己选择的地域。
数据准备,进入机器学习平台,单击数据源,创建表。
IDE端上传数据到Maxcompute
OSS上传数据创建新空白数据,
数据准备完成后,单击组件,在工具和数据预处理文件夹下将SQL脚本、类型转换、归一化组件拖到画布中,并拼接成如下实验。
数据可视化,
在机器学习->二分类文件夹下,将逻辑回归二分类组件拖入画布。
在右侧的字段设置页签,将目标列设置为ifhealth,训练特征列选择除目标列以外的全部列,并拼接运行,
在机器学习->评估文件夹下,将二分类评估组件拖入画布。在画布右侧的字段设置页签,将原始标签列列名设置为ifhealth,并连接对应的组件流和数据流。
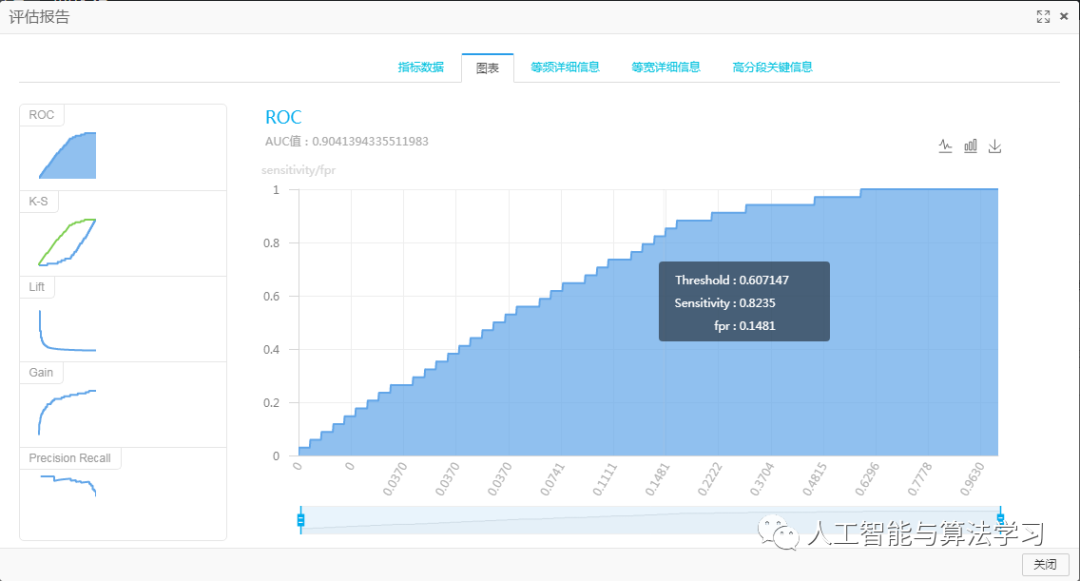
单击运行。完成后右键单击二分类评估组件,选择查看评估报告,单击图表页签,得到不同参数下训练的LR模型的ROC曲线,如下图所示。
在使用 PAI 命令方式训练 LR 模型后,可以通过以下步骤查询训练好的模型参数:
在训练任务结束后,可以使用 PAI 命令行界面的 remote ls 命令查看模型保存路径。例如,如果模型保存在 OSS 上,则可以使用以下命令列出该 OSS 存储路径下的所有文件:
pai -name osscmd_public -project algo_public -Dcmd="ls oss://your-bucket/path/to/model"
其中,your-bucket 为您的 OSS 存储桶名,path/to/model 为您训练好的 LR 模型保存路径。
找到保存的模型文件后,可以使用常见的机器学习库(例如 sklearn、PyTorch、TensorFlow 等)加载模型并查询其参数。以 sklearn 为例,您需要执行以下步骤:
导入 LinearRegression 模型类:
from sklearn.linear_model import LogisticRegression
实例化一个 LogisticRegression 对象,并从模型文件中加载参数:
model = LogisticRegression()
model.coef_ = np.fromfile('/path/to/coef.bin', dtype=np.float32).reshape((-1, 2))
model.intercept_ = np.fromfile('/path/to/intercept.bin', dtype=np.float32)
其中,/path/to/coef.bin 和 /path/to/intercept.bin 分别为模型参数保存路径下的系数矩阵文件和偏差向量文件。请根据您的实际情况修改这些路径。
使用 model.coef_ 和 model.intercept_ 属性获取已训练模型的参数,例如系数向量和偏差量等。
需要注意,模型参数的具体格式和存储路径,取决于您训练模型时选择的机器学习库和参数设置。请根据具体情况进行调整。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。



