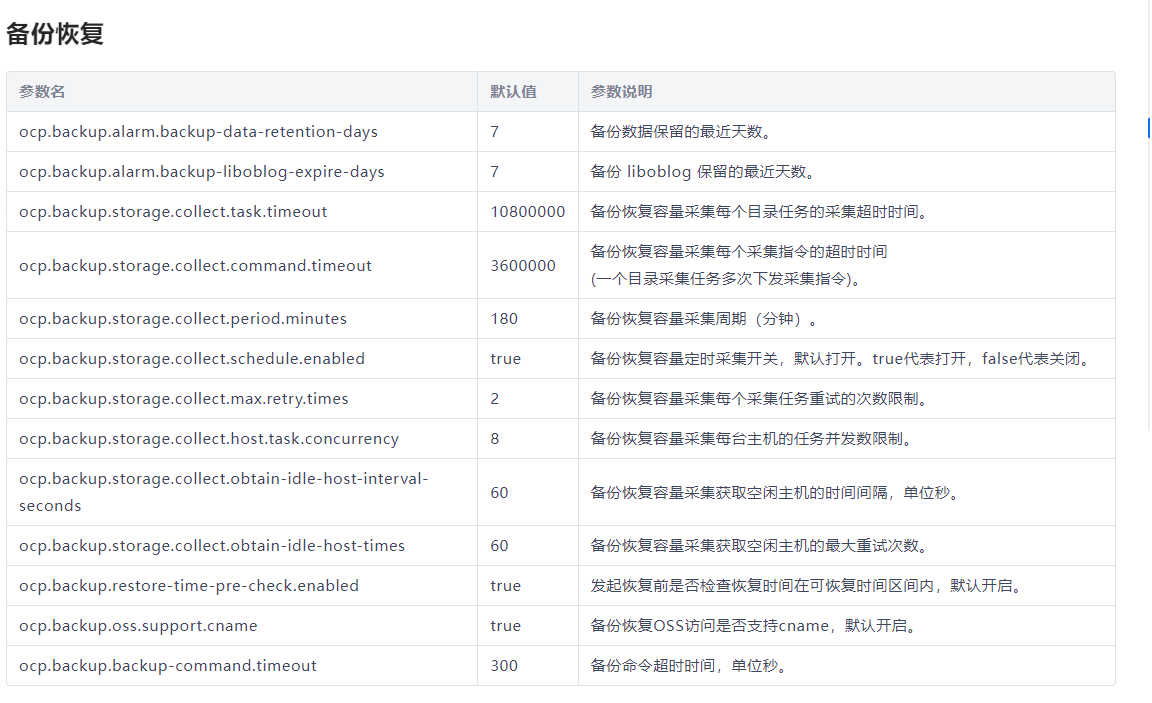
想请教下各位大佬,用OceanBase-cdc采集一张600多万数据量的表,initial模式启动任务后,一直卡在 Start to read snapshot阶段,长时间不往下运行导致任务报错,这种问题该怎么解决呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对OceanBase CDC在initial模式启动任务时,长时间卡在读取快照(Start to read snapshot)阶段的问题,可以尝试以下几种排查和解决方法:
资源检查:
网络状况:
配置优化:
监控与日志分析:
OceanBase支持:
业务时间窗口:
楼主你好,如果在使用阿里云OceanBase CDC采集一张大表时,任务在"Start to read snapshot"阶段一直卡住,导致长时间不往下执行并最终报错,可以尝试增加资源配额,检查任务所在的机器的资源配额,包括CPU、内存、磁盘等。如果配额不足,可以尝试增加资源配额,给任务提供更多的计算和存储资源。
还有就是调整CDC参数,可以直接调整OceanBase CDC的相关参数,如增加采集的并行度、调整内存管理参数等。这些参数的调整可以根据具体的任务需求和机器配置进行优化,以提高任务的执行效率。然后再来看一下下面的设置: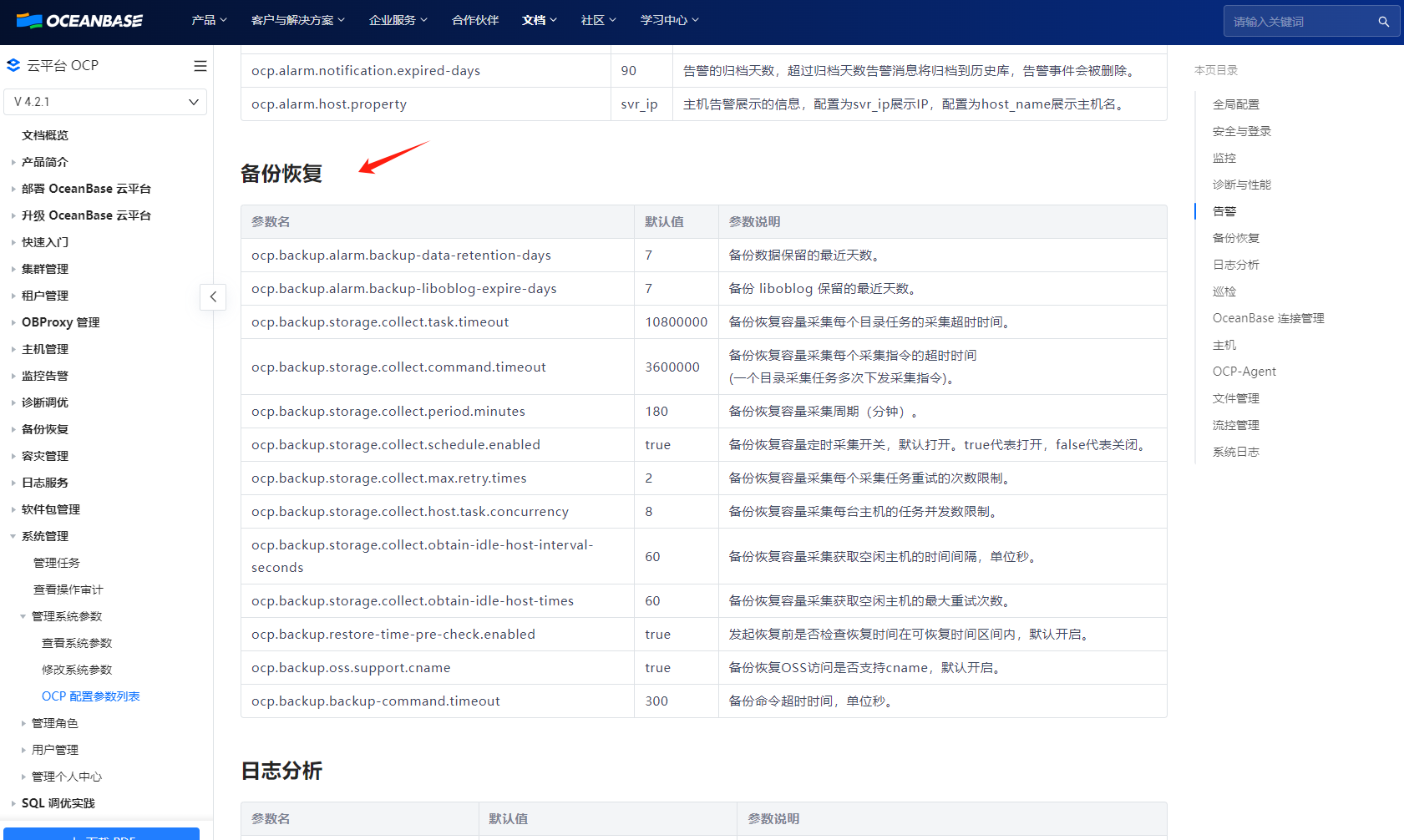
注意:本回答参考了阿里云OceanBase官方文档
OceanBase-cdc 是 OceanBase 数据库变更数据捕获(Change Data Capture,CDC)的组件,它可以捕获数据库的变更事件并将这些事件传递给下游的应用程序或服务。如果你在使用 OceanBase-cdc 以 initial 模式启动任务时遇到了长时间卡在 "Start to read snapshot" 阶段的问题,可能有几个潜在的原因和解决步骤:
资源限制:
配置检查:
3 . 数据库锁定和隔离级别:
确保采集的表结构正确,并且在initial模式下,表的schema与表文件的结构一致。如果不一致,您需要修改schema与表文件的结构,使其一致。
确保表空间配置正确,并且在initial模式下,表空间与表的数据存储路径一致。如果不一致,您需要修改表空间配置,使其一致。
如果您的表中存在全文索引,请在采集任务中指定全文索引,并且将其作为一个独立的数据源进行采集。这样可以避免全文索引对任务运行的影响。
确保您的网络连接正常,并且可以正常访问OceanBase数据库。如果网络连接不正常,您需要检查网络设置,并确保网络畅通。
查看OceanBase-cdc采集任务的日志信息,以便更详细地了解问题的原因。如果有错误信息,您可以根据错误信息进行排查。
出现这种问题,可能是由于以下几个原因导致的:
调整CDC任务的并发数:通过设置--task.concurrency参数来调整CDC任务的并发数。例如,将并发数设置为10