model_id = 'damo/nlp_convai_text2sql_pretrain_cn'
model = Model.from_pretrained(model_id)
tokenizer = BertTokenizer(os.path.join(model.model_dir, ModelFile.VOCAB_FILE))
db = Database(tokenizer=tokenizer,
# table_file_path=os.path.join('/home/django/users.json'),
table_file_path='/home/django/order_item.json',
syn_dict_file_path=os.path.join(model.model_dir, 'synonym.txt'),
is_use_sqlite=True)
preprocessor = TableQuestionAnsweringPreprocessor(model_dir=model.model_dir, db=db)
pipelines = [
pipeline(
Tasks.table_question_answering,
model=model,
preprocessor=preprocessor,
db=db)
]
test_case = {
'utterance': [['我一共购买了多少镀锌钢管', 'material_item']]
}
for pipeline in pipelines:
historical_queries = None
for question, table_id in test_case['utterance']:
output_dict = pipeline({
'question': question,
'table_id': table_id,
'history_sql': historical_queries
})[OutputKeys.OUTPUT]
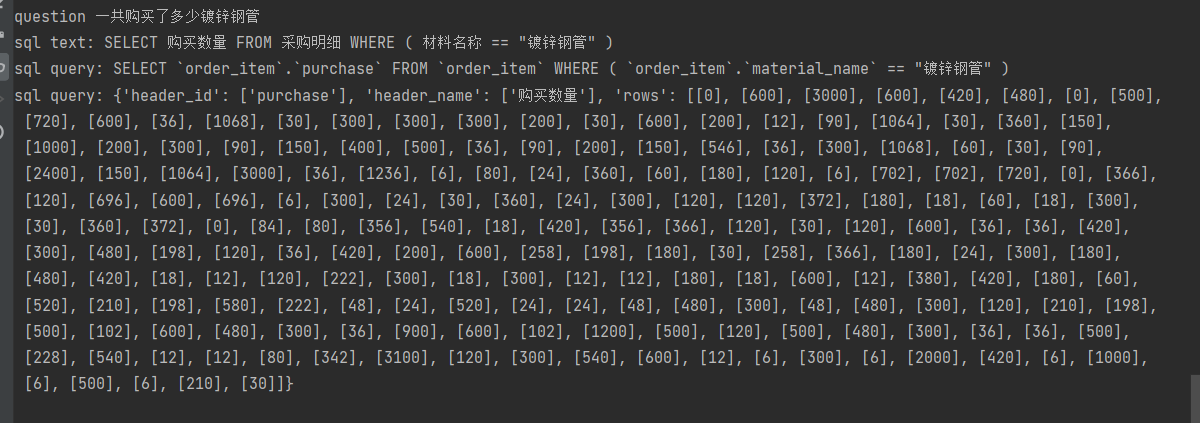
print('question', question)
print('sql text:', output_dict[OutputKeys.SQL_STRING])
print('sql query:', output_dict[OutputKeys.SQL_QUERY])
print('sql query:', output_dict[OutputKeys.QUERT_RESULT])
print()
historical_queries = output_dict[OutputKeys.HISTORY]
class Command(BaseCommand):
help = 'Generate JSON data for OrderItem'
def handle(self, *args, **options):
header_id = ['id', 'material_name', 'sku', 'purchase',
'unit',
'order_name',
'user',
'time']
header_name = ["编码", "材料名称", "规格", "购买数量", "单位", "材料单名称", "采购者", '时间']
header_types = ["text", "text", "text", "number", "text", "text", "text", "date"]
header_units = ["", "", "", "个", "", "", "", ""]
header_attribute = ["PRIMARY", "MODIFIER", "MODIFIER", "MODIFIER", "MODIFIER", "MODIFIER", "MODIFIER",
"MODIFIER"]
rows = []
order_items = OrderItem.objects.all()
for o in order_items:
rows.append([
str(o.id),
remove_special_chars(o.material.name),
remove_special_chars(o.material.sku),
o.buy_num,
remove_special_chars(o.material.unit),
# str(o.order.id),
remove_special_chars(o.order.name),
# str(o.order.created_by.id),
remove_special_chars(o.order.created_by.name),
o.order.created_time.date().isoformat(),
])
data = {
"table_id": "order_item",
"table_name": "采购明细",
"header_id": header_id,
"header_name": header_name,
"header_types": header_types,
"header_units": header_units,
"header_attribute": header_attribute,
"rows": rows
}
with open('order_item.json', 'w') as f:
json.dump(data, f, ensure_ascii=False)
self.stdout.write(json.dumps(data))


