
dataworks如何加工kafka中的数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
DataWorks可以通过Kafka数据源实现对Kafka中数据的加工。下面是具体的步骤:
在DataWorks中创建Kafka数据源,需要填写Kafka集群地址、Topic名称、消费组ID等信息。
创建数据集,选择Kafka数据源,指定需要消费的Topic,设置数据格式。
创建数据开发节点,选择Kafka数据集作为输入,选择需要的数据处理算子进行数据加工,最终输出到目标数据集。
创建目标数据集,选择需要的存储介质,如MaxCompute、RDS等。
创建数据集成节点,选择数据开发节点的输出作为输入,选择目标数据集作为输出,设置数据同步方式。
提交任务并执行,即可实现对Kafka中数据的加工。
需要注意的是,在使用Kafka数据源进行数据加工时,需要考虑数据的实时性和稳定性,合理设置消费组ID、消费位置等参数,避免数据重复消费或数据丢失。
DataWorks可以通过流计算模块来加工Kafka中的数据。具体步骤如下:
创建流计算任务:在DataWorks控制台中,选择数据开发->流计算,创建一个新的流计算任务。
添加数据源:在流计算任务中添加Kafka作为输入数据源,并设置相关参数,如Kafka的地址、Topic等。
定义SQL脚本:在流计算任务中编写SQL脚本来对Kafka中的数据进行加工处理。SQL脚本的编写可以使用DataWorks提供的可视化SQL编辑器,也可以使用自定义的SQL脚本。
配置输出:在流计算任务中配置输出数据源,可以将加工后的数据输出到MySQL、MaxCompute等目标数据源中,也可以将结果写回到Kafka中。
提交任务:完成以上配置后,提交流计算任务并启动,即可开始对Kafka中的数据进行加工处理。
以上是对Kafka数据进行加工处理的基本流程,具体的加工操作可以根据实际需求进行编写。值得注意的是,流计算任务在处理Kafka数据时需要考虑到数据实时性和容错性,需要进行一定的性能和容错优化。
使用DataWorks数据同步功能,将消息队列Kafka版集群上的数据迁移至阿里云大数据计算服务MaxCompute,
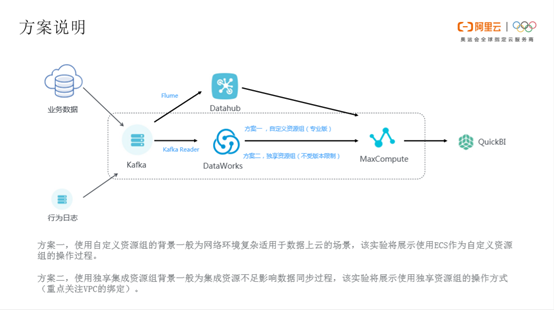
Kafka数据同步到DataWorks有两条链路。一条链路是业务数据和行为日志通过Kafka,再通过Flume 上传到Datahub,以及Max Compute,最终在QuickBI进行展示。另一条链路是业务数据和行为日志通过Kafka以及DataWorks,MaxCompute,最终在QuickBI当中展示。
从DataWorks上传到MaxCompute是通过两种方案进行上传数据同步的。方案一是自定义资源组,方案二是独享资源组。自定义资源组一般适用于复杂网络的数据上云场景。独享资源组操作方式主要针对集成资源不足的情况。
消息队列 for Apache Kafka 是阿里云提供的分布式、高吞吐、可扩展的消息队列服务。消息队列for Apache Kafka一般用于日志收集、监控数据聚合、流式数据处理、在线离线分析等大数据领域。消息队列 for Apache Kafka 针对开源的 Apache Kafka 提供全托管服务,彻底解决开源产品长期以来的痛点。云上Kafka具有低成本、更弹性、更可靠的优势,用户只需专注于业务开发,无需部署运维。
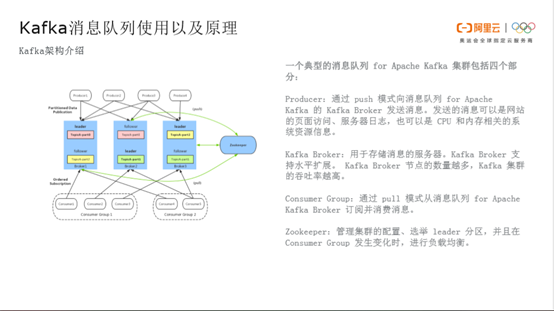
典型的Kafka集群主要分为四部分。Producer生产数据并通过 push 模式向消息队列 for Apache Kafka 的 Kafka Broker 发送消息。发送的消息可以是网站的页面访问、服务器日志,也可以是 CPU 和内存相关的系统资源信息。Kafka Broker用于存储消息的服务器。Kafka Broker 支持水平扩展。 Kafka Broker 节点的数量越多,Kafka 集群的吞吐率越高。Kafka Broker针对topic会partition一个概念,partition有leader、follower的角色分配。
Consumer通过 pull 模式从消息队列 for Apache Kafka Broker 订阅并消费leader的信息数据。其中partition内部有offset作为消息的消费点位。通过ZooKeeper管理集群的配置、选举 leader 分区,并且在Consumer Group 发生变化时,管理partition_leader的负载均衡。
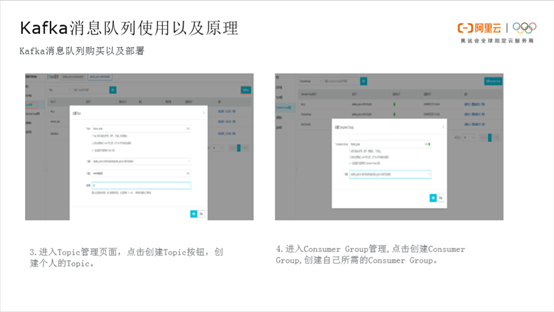
用户首先可以到Kafka消息队列产品页面点击购买,根据个人情况选择对应包年、包月等消费方式、地区、实例类型、磁盘、流量以及消息存放时间。其中较为重要的一点是要选择对应地区,如果用户的MaxCompute在华北,那么尽量选择华北地区。选择开通完成后需要进行部署。点击部署,选择合适的VPC及其交换机进行部署。
部署完成后进入Kafka Topic管理页面,点击创建Topic输入自己的Topic。Topic命名下面有三条注意信息,命名尽量跟自己的业务一致,比如是财经业务或者是商务业务,尽量进行区分。第四步进入Consumer Group管理,点击创建Consumer Group创建自己所需要的Consumer Group。Consumer Group的命名也需要规范,如果是财经或商务业务,尽量和自己的Topic相对应。
**Kafka安装部署完成之后确认需要访问Kafka的服务器或产品的白名单。
购买完成后需要把独享集成资源组绑定到与Kafka对应的VPC,点击专有网络绑定,选择与Kafka对应的交换机(最明显的是可用区的区别)、安全组。
楼主你好,给你提供一个dataworks加工kafka中数据的思路:创建数据清洗加工任务,并编排,将编排后的任务提交、发布至生产环境进行周期调度。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



