
StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
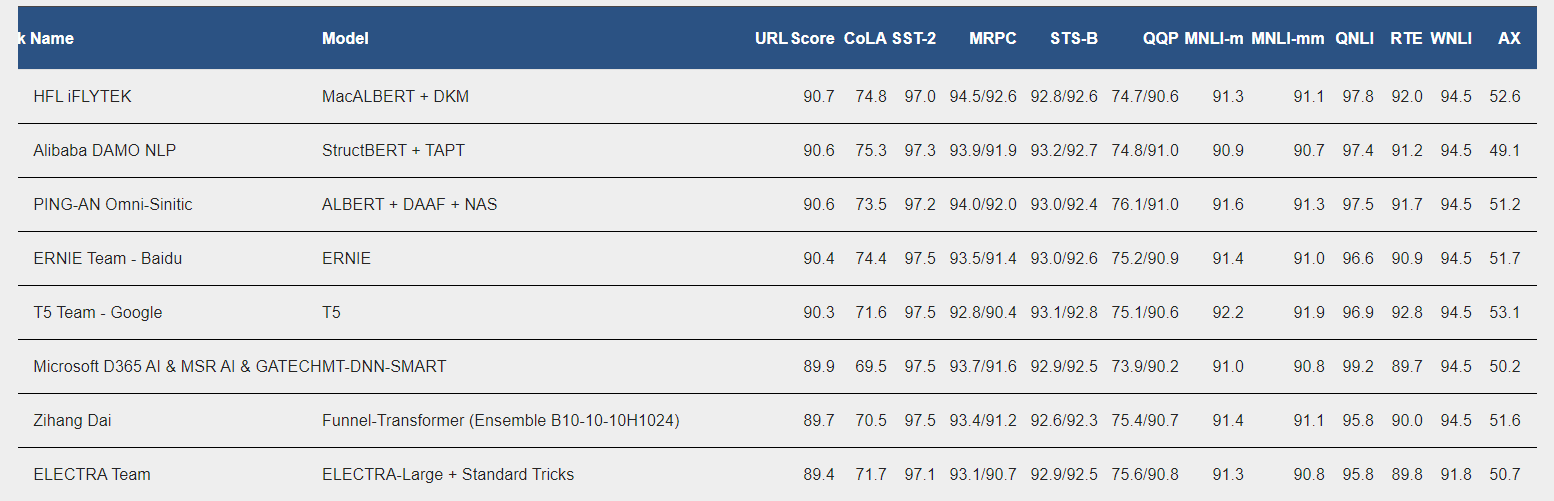
StructBERT是阿里对的一个BERT改进,模型取得了很好的效果,目前在GLUE排行榜上排名第二
首先我们看下面一个英文和中文两句话
i tinhk yuo undresatnd this sentneces.研表究明,汉字序顺并不定一影阅响读。比如当你看完这句话后,才发这现里的字全是都乱的
其实上面两个句子都是乱序的
这就是structBERT的改进思路的来源。对于一个人来说,字或字符的顺序不影响阅读,模型也是一样,一个好的LM,需要懂得自己纠错
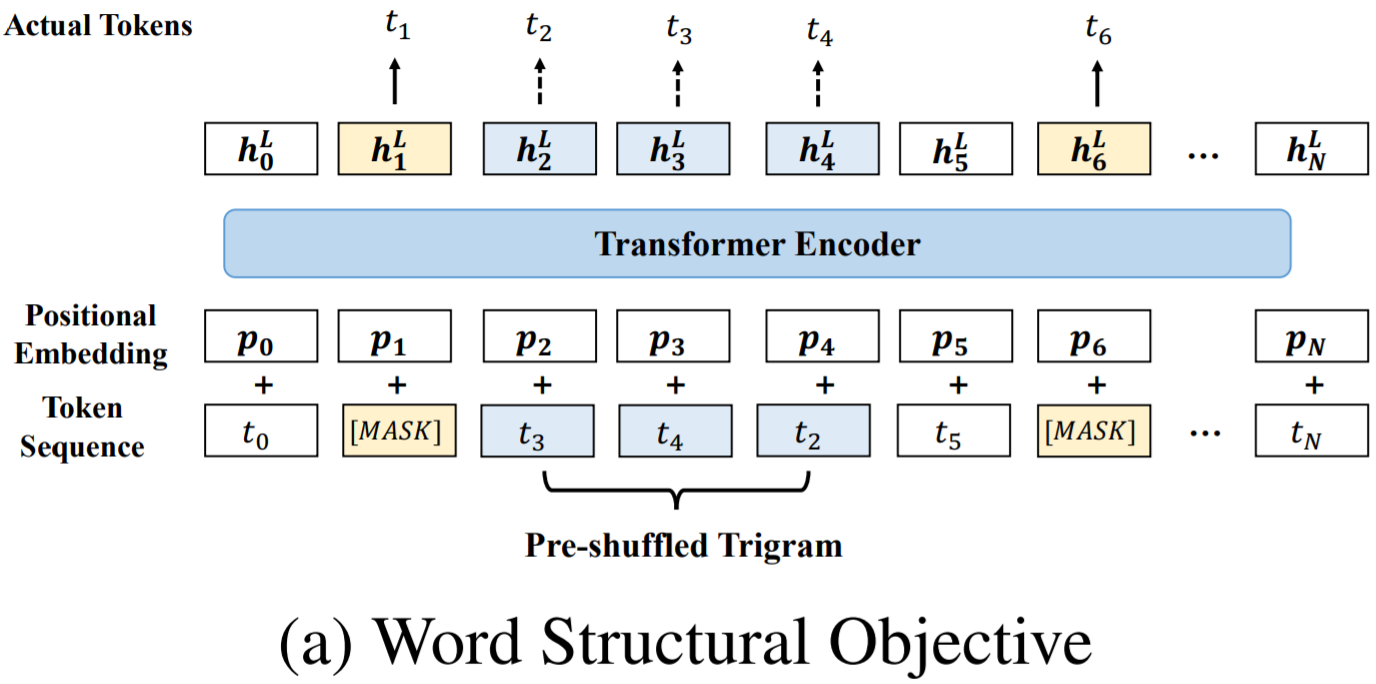
StructBERT的模型架构和BERT一样,它改进在于,在现有MLM和NSP任务的情况下,新增了两个预训练目标:Word Structural Objective和Sentence Structural Objective
从未被mask的序列中随机选择部分子序列(使用超参数KKK来确定子序列的长度),将子序列中的词序打乱,让模型重建原来的词序
argmaxθ∑logP(pos1=t1,pos2=t2,...,posk=tk∣t1,t2,...,tk,θ)\mathop{argmax}\limits_{\theta}\sum \log P(pos_1=t_1,pos_2=t_2,...,pos_k=t_k\mid t_1,t_2,...,t_k,\theta) θargmax∑logP(pos1=t1,pos2=t2,...,posk=tk∣t1,t2,...,tk,θ)其中,θ\thetaθ表示模型的参数,希望的结果是把子序列恢复成正确顺序的likelihood最大
Larger KKK,模型必须要学会重建更多的干扰数据,任务难
Smaller KKK,模型必须要学会重建较少的干扰数据,任务简单
论文中设定的是K=3K=3K=3,这对单个句子任务的效果比较好
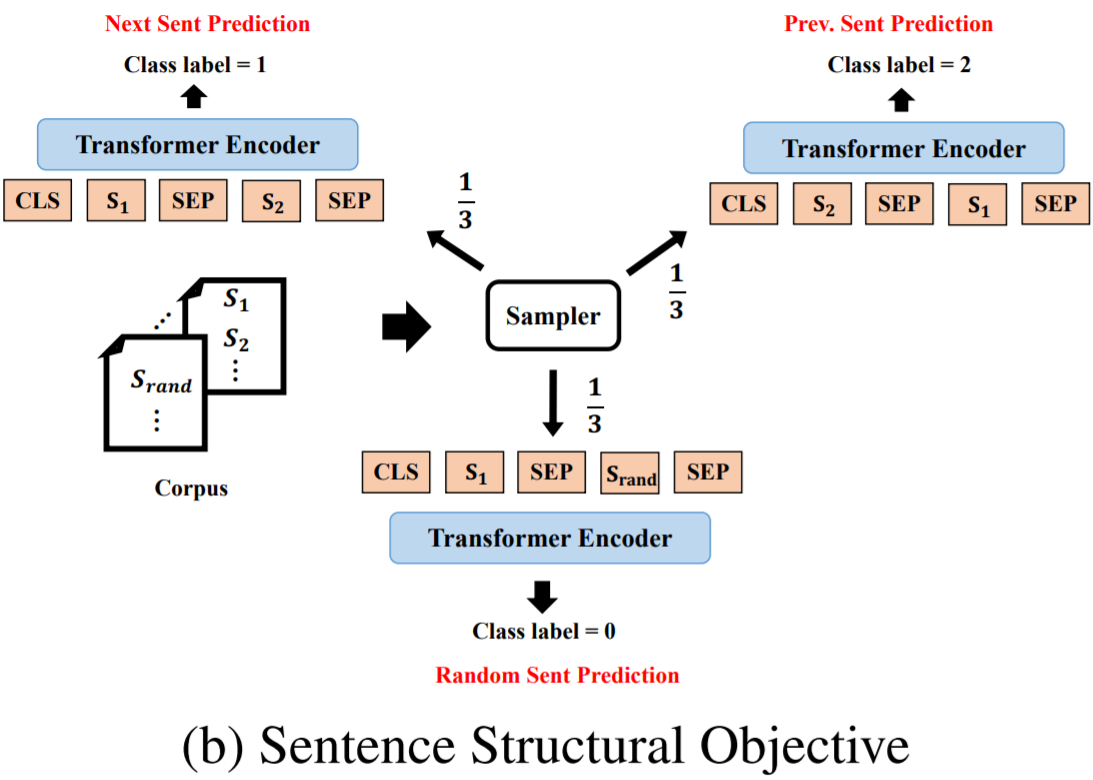
给定句子对(S1,S2),判断S2是S1的下一个句子、上一个句子、毫无关联的句子(三分类问题)
采样时,对于一个句子S,13\frac{1}{3}31的概率采样S的下一句组成句对,13\frac{1}{3}31的概率采样S的上一句,13\frac{1}{3}31的概率随机采样另一个文档的句子组成句对
作者对于提出的两个预训练任务进行了消融研究,以验证每个任务的有效性
如上图所示,这两个任务对大多数下游任务的性能都有很大影响(除了SNLI)
前三个是单句任务,可以看出Word Structural Objective对它们的影响很大
后三个是句对任务,可以看出Sentence Structural Obejctive对它们的影响很大
很可惜,笔者翻遍了github也没有找到预训练好的StructBERT模型
StructBERT调研
StructBERT(ALICE) 详解
StructBert Review
StructBERT是阿里云提出的一种对BERT模型的改进方法,旨在通过整合语言结构信息来提升深度语言理解能力。该模型在GLUE排行榜上取得了第二名的好成绩,显示了其在自然语言处理任务中的有效性。StructBERT的核心创新在于引入了两种新的预训练目标,即词结构目标(Word Structural Objective)和句子结构目标(Sentence Structural Objective),以此增强模型对语言结构的理解和自纠错能力。
这个目标关注于词序的重建。它从未被遮蔽(mask)的序列中随机选择子序列,并打乱这些子序列中的词序,然后要求模型学习恢复原始的正确词序。这一过程鼓励模型学习词汇之间的依赖关系,即使它们的顺序被打乱。超参数K决定了子序列的长度,较大的K值会增加任务难度,而较小的K值则使任务相对简单。论文推荐使用K=3,这对于处理单句任务效果较好。
此目标则是针对句子间的关系判断,为模型提供上下文理解的训练。给定两个句子S1和S2,模型需要判断S2相对于S1的位置关系(下一个句子、上一个句子或无关)。通过以1/3的概率分别采样相邻句子、前一个句子以及来自不同文档的句子作为句对,模型学习捕捉句子间的连贯性和逻辑关系,这对于句对任务尤其重要。
研究者还进行了消融实验,验证这两个新引入的预训练任务的有效性。结果显示,Word Structural Objective显著提升了单句任务的表现,而Sentence Structural Objective则对句对任务的性能有较大影响,证明了这两种结构化目标的有效性。
尽管StructBERT展示了强大的语言理解潜力,但遗憾的是,目前似乎没有公开预训练好的StructBERT模型可供直接使用。对于希望深入研究或应用StructBERT的开发者来说,可能需要自行复现论文中的方法进行训练。
参考文献中提到的链接可以提供更多关于StructBERT的详细信息和研究背景,对于想要深入了解该模型的读者来说是宝贵的资源。

