
使用ModelScope官方模型demo 运行时候报错 这个怎么解决啊?
已解决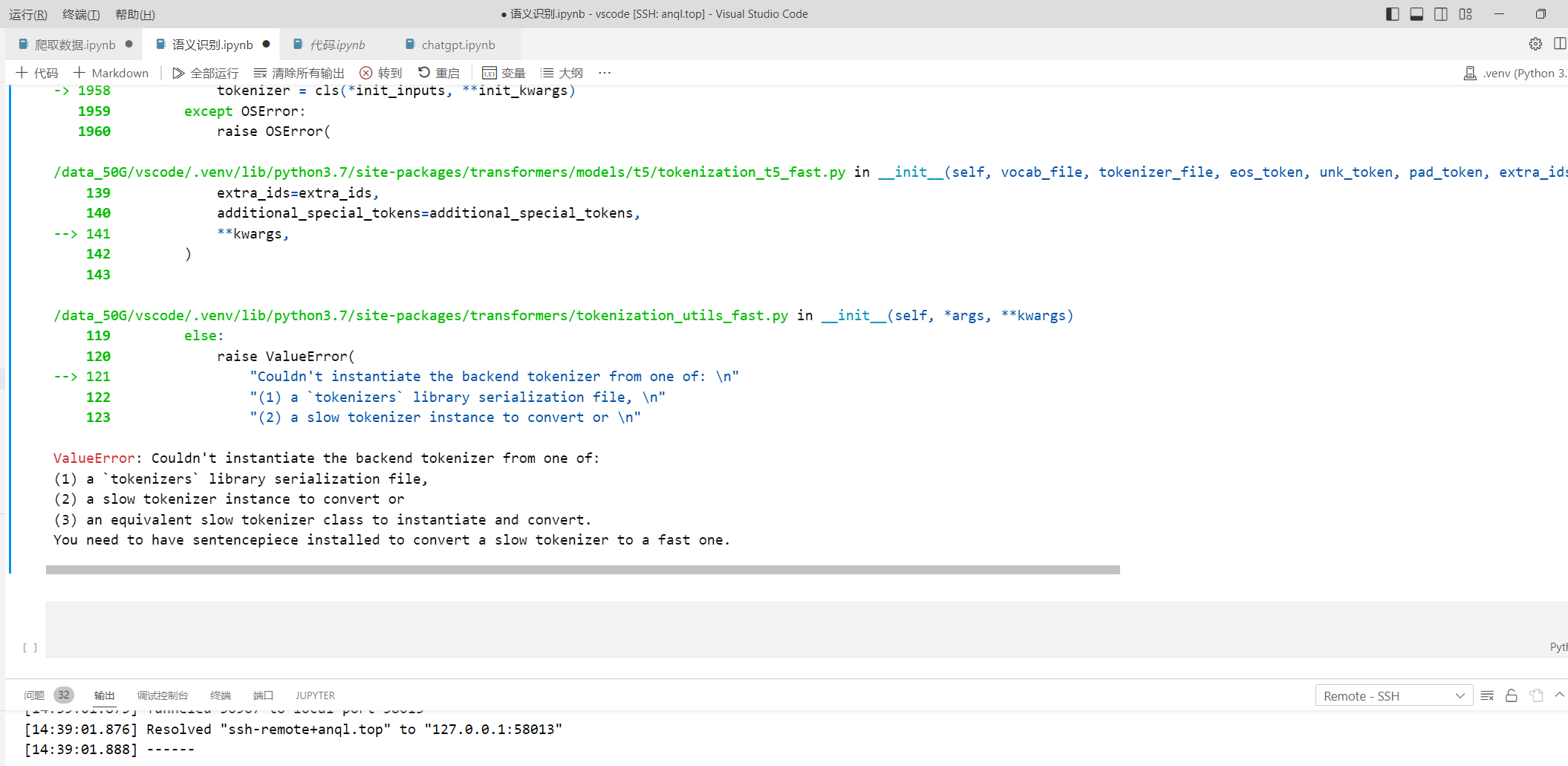
 使用ModelScope官方模型demo 运行时候报错 这个怎么解决啊?
使用ModelScope官方模型demo 运行时候报错 这个怎么解决啊?
-
北京阿里云ACE会长推荐回答
根据你提供的错误信息,看起来是在使用 ModelScope 官方的模型 demo 时出现了问题,提示缺少 sentencepiece 库,导致无法初始化 tokenizer。
sentencepiece 是一种开源的自然语言处理库,用于训练和使用字级别或子词级别的文本分割模型。在 Transformers 库中,sentencepiece 通常被用来作为 tokenizer 的后端,用于将原始文本分割成 token。
为了解决这个问题,你需要安装 sentencepiece 库。你可以使用以下命令来安装 sentencepiece:
pip install sentencepiece 安装完成后,再次运行 ModelScope 的模型 demo,应该就可以成功初始化 tokenizer 了。
如果你已经安装了 sentencepiece 库,但仍然出现这个错误,可能是因为 Transformers 库的版本不兼容导致的。你可以尝试升级 Transformers 库到最新版本,或者降级到与 demo 中使用的版本相同的 Transformers 版本。
2023-06-10 15:53:07赞同 展开评论 -
俩方面可能 1. 检查一下环境中是否已经安装了相应的 tokenizer。
- 检查一下代码中是否正确指定了 tokenizer 的类型和参数。
2023-06-21 13:43:26赞同 展开评论 -
公众号:网络技术联盟站,InfoQ签约作者,阿里云社区签约作者,华为云 云享专家,BOSS直聘 创作王者,腾讯课堂创作领航员,博客+论坛:https://www.wljslmz.cn,工程师导航:https://www.wljslmz.com
这个错误提示看起来是在使用 ModelScope 官方模型 demo 时出现的。根据错误提示中的信息,可能是由于无法实例化后端 tokenizer 导致的。
您可以尝试检查一下您的环境中是否已经安装了相应的 tokenizer。如果您使用的是 Hugging Face 的 Transformers 模块,可以尝试安装相应的 tokenizer,例如:
pip install transformers如果您使用的是其他的 NLP 工具包,也需要确保相应的 tokenizer 已经安装并正确配置。
另外,还需要检查一下您的代码中是否正确指定了 tokenizer 的类型和参数。如果您使用的是 Hugging Face 的 Transformers 模块,可以参考以下示例代码:
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')在这个示例中,我们使用
AutoTokenizer类来实例化 tokenizer,并指定了bert-base-uncased模型。您需要根据自己的情况进行相应的调整。2023-06-20 09:54:35赞同 展开评论 -
从事java行业9年至今,热爱技术,热爱以博文记录日常工作,csdn博主,座右铭是:让技术不再枯燥,让每一位技术人爱上技术
您好,运行modelscope官方模型报错的话,为了排除环境方面的影响,建议您采用线上Notebook在线开发测试,注意选择正确的python版本编辑器,清除上次运行失败记录再次尝试看是否可以,通常情况下官方发布的模型都是可以直接运行测试的。
2023-06-19 16:28:35赞同 展开评论 -
云端行者觅知音, 技术前沿我独行。 前言探索无边界, 阿里风光引我情。
这个错误信息表明在使用ModelScope官方模型demo时,无法从以下任意一个位置实例化后端tokenizer:
tokenizers库序列化文件
Hugging Face Transformers模型
TensorFlow SavedModel4. TensorFlow Hub模型
这个错误通常是由于缺少必要的文件或者文件路径不正确导致的。您可以尝试检查几个方面: 检查您的文件路径是否正确,确保您的文件存在于正确的位置。
检查您是否正确安装了所需的库和依赖项。
检查您是否正确下载了所的模型文件。
检查您是否正确设置了环境变量。
如果您仍然无法解决问题,您可以尝试查看ModelScope方文档或者联系他们的支持团队以获取更多帮助。
2023-06-13 18:52:58赞同 展开评论 -
不断追求着最新的技术和趋势,在云技术的世界里,我不断寻找着新的机会和挑战,不断挑战自己的认知和能力。
这个错误提示表明在运行官方模型demo时,无法实例化后端tokenizer。
这个错误通常是由于以下原因之一引起的:
缺少必要的 tokenizer 库:您可能需要安装一些 tokenizer 库,例如 PyTorch tokenizer、BERT tokenizer 等。如果这些库没有正确安装,就会出现这个错误。
tokenizer 库的版本不匹配:如果您安装了多个 tokenizer 库,但其中某个库的版本与模型所需求的版本不匹配,也会出现这个错误。
模型文件路径不正确:在运行官方模型 demo 时,需要将模型文件复制到指定的路径中。如果模型文件路径不正确,就会出现这个错误。
为了解决这个问题,您可以按照以下步骤进行排查:
确认您已经安装了必要的 tokenizer 库,例如 PyTorch tokenizer、BERT tokenizer 等。
确认您的 tokenizer 库的版本与模型所需求的版本匹配。您可以在模型文件中查看所使用的 tokenizer 库版本。
确认模型文件路径是否正确。您可以在运行官方模型 demo 时,将模型文件复制到指定的路径中。
如果以上步骤都没有解决问题,您可以尝试联系官方模型 demo 的开发者或相关的技术支持团队,以获取更多的帮助。
2023-06-13 18:52:39赞同 展开评论 -
这个问题可能是因为您缺少了 sentencepiece 库,它是一个用于训练和使用各种自然语言处理模型的库,包括 BERT 和 GPT 等模型中使用的分词器。如果缺少该库,就会导致初始化 tokenizer 时出现错误。
要解决这个问题,您需要安装 sentencepiece 库。您可以使用以下命令在终端或命令行界面中安装: pip install sentencepiece 如果您使用的是 Anaconda 或 Miniconda 等科学计算环境管理工具,也可以使用以下命令安装: conda install -c conda-forge sentencepiece 安装完成后,您可以再次运行 ModelScope 官方的模型 demo,并检查是否仍然存在同样的问题。
2023-06-13 10:06:13赞同 展开评论 -
这个错误通常是由于缺少必要的依赖项或安装不正确而导致的。根据错误信息,你需要安装sentencepiece库,它是一种用于自然语言处理的工具,可以用于分词和生成词汇表等任务。 你可以使用以下命令在终端中安装sentencepiece库:
pip install sentencepiece如果你已经安装了sentencepiece库,你需要确认你的安装是否正确。你可以尝试从Python中导入sentencepiece库,如果没有错误则表示安装正确:
import sentencepiece如果你仍然无法解决问题,可能需要检查你的环境变量和路径设置是否正确。
2023-06-12 20:50:36赞同 展开评论 -
天下风云出我辈,一入江湖岁月催,皇图霸业谈笑中,不胜人生一场醉。
该问题可能是由于缺少sentencepiece库导致的。sentencepiece是一个常用的自然语言处理工具包,它可以将慢速的单词切分器转换为快速的单词切分器,从而提高模型在训练和推理时的性能。您可以尝试使用以下命令安装sentencepiece库:
pip install sentencepiece 然后重新编译运行您的代码。如果仍然出现问题,您可以尝试使用TensorFlow的FastTokenizer模块来加速单词切分器的转换。
2023-06-12 16:32:12赞同 展开评论 -
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
-
检查依赖项:首先需要检查所需的依赖项是否已经正确安装和配置。可以查看错误日志和报告,分析具体的错误信息并尝试进行修复。如果无法确定具体的错误原因,可以尝试重新安装依赖项,并确保按照要求进行配置和调试。
-
确保运行环境正确:在运行 ModelScope 官方模型 demo 时,需要确保所选用的运行环境正确。例如,需要选择适合该模型的硬件、操作系统、编程语言和库等,并确保其版本和配置符合要求。可以参考 ModelScope 的文档和示例代码,了解如何正确配置和部署运行环境。
-
重启服务和程序:有时候,由于系统或者其他原因导致服务和程序出现异常,可以尝试重新启动服务和程序,以恢复正常运行。可以使用命令行或者脚本方式重新启动服务和程序,并观察报错信息和日志输出等信息。
-
寻求帮助:如果以上方法无法解决问题,可以向 ModelScope 官方客服或技术支持团队寻求帮助。可以提供相关的错误信息和报告,以便他们能够更好地理解和分析问题,并给出相应的解决方案和建议。
2023-06-11 19:38:31赞同 展开评论 -
-
值得去的地方都没有捷径
下面是一些我推荐的步骤:
1.确保您按照官方文档的步骤正确设置了您的环境。
2.检查提示的错误消息并确定其原因。请检查访问您的模型所需的设置、网络连接等。
3.如果您仍然不能确定错误的原因,请提供更多的错误信息和重现步骤。这将帮助其他人更好地理解您的问题并提供帮助。
4.最后,您可以通过联系ModelScope的客服,寻求更具针对性的帮助。他们的邮箱是info@modelscope.io。
希望这些步骤可以帮助您解决问题。再次感谢您的提问!
2023-06-11 15:27:11赞同 展开评论 -
这个错误通常是由于缺少必要的依赖项或配置不正确引起的。以下是一些可能的解决方案:
确认您已经安装了ModelScope的依赖项。您可以使用pip freeze命令列出当前环境中已安装的包,并确保torch、transformers、tokenizers等包已经安装。 确认您的配置文件正确。ModelScope需要一些配置文件来正确运行,例如tokenizer_config.json、tokenizer_model_file.txt等。您可以检查这些文件是否存在,并确保它们位于正确的位置。 确认您的代码没有其他错误。如果您的代码中存在其他错误,可能会导致ModelScope无法正确初始化后端tokenizer。您可以检查您的代码并确保它们没有语法错误或其他问题。 如果您使用的是Anaconda环境,确保您已激活该环境并正在使用正确的Python版本。如果您的Python版本不正确,则可能会导致此类错误。 如果以上解决方案不起作用,请尝试查看ModelScope官方文档或联系官方支持团队以获取更多帮助。
2023-06-11 09:23:58赞同 展开评论 -
这个报错是因为在使用ModelScope官方模型demo时,需要使用sentencepiece这个库来对tokenizer进行转换,但是当前环境下并没有安装sentencepiece。解决这个问题的方法是安装sentencepiece库,可以使用以下命令进行安装:
!pip install sentencepiece安装完成之后,重新运行程序即可解决报错问题。
2023-06-09 23:46:03赞同 展开评论 -
全栈JAVA领域创作者
一些常见的解决方法包括:
确保您已经正确安装了所需的依赖项。您可以尝试重新安装依赖项,或者更新它们到最新版本。
检查代码中的错误。如果有语法错误或逻辑错误,会导致代码运行失败。请确保代码没有任何错误,并且所有变量和函数都被正确定义和使用。
查看系统日志以获取更多信息。系统日志可能会提供更详细的信息,使您能够更好地了解问题的本质。您可以在控制台或日志文件中查找这些信息。
如果上述方法无法解决您的问题,请提供更详细的信息,例如报错信息、代码示例等,以便我更好地帮助您解决问题。
2023-06-09 16:58:26赞同 展开评论 -
这个错误显示您需要安装sentencepiece模块来进行快速分词器的转换。
可按以下的方式安装这一模块:
pip install sentencepiece然后,在您的代码中导入sentencepiece模块:
import sentencepiece as spm # 加载和训练模型 spm.SentencePieceTrainer.train(input='input.txt', model_prefix='m', vocab_size=5000) # 加载模型和分词器 sp = spm.SentencePieceProcessor() sp.load('m.model') # 使用分词器 s = 'Sentence to be segmented.' tokens = sp.encode_as_pieces(s)在上述示例中,我们首先导入sentencepiece模块,然后使用SentencePieceTrainer类训练了模型,并将其保存为'm.model'文件。接下来,我们使用SentencePieceProcessor类加载了模型和分词器,并使用encode_as_pieces方法对字符串进行分词。
2023-06-09 16:15:09赞同 展开评论

