
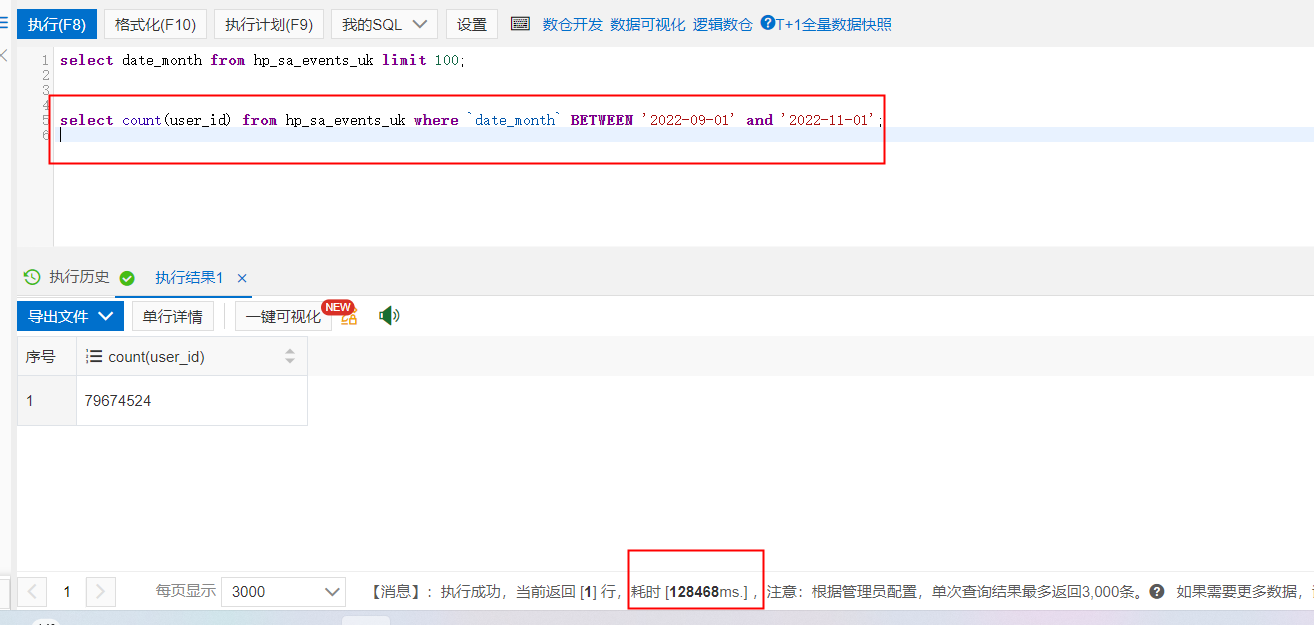
 麻烦问一下,我表里的数据也不多,总共8千万,为什么一个简单count?耗时为什么这么长?
麻烦问一下,我表里的数据也不多,总共8千万,为什么一个简单count?耗时为什么这么长?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
日期字段要增加索引。写法参考如下代码:
SELECT * FROM t_order WHERE buy_time>= str_to_date('2022-12-30', '%Y-%m-%d')
有几个原因可能会导致简单的COUNT查询耗时较长:
没有索引或索引不合适:COUNT是在整个表(或指定的where条件)中计算行数,如果没有适当的索引,数据库需要扫描整个表来计算行数。如果表特别大,这可能需要很长时间。因此,建议在执行COUNT查询的列上建立适当的索引,这样可以快速返回数据。
数据库负载过高:在高流量的情况下,COUNT查询可能需要等待其他查询完成,这会导致查询延迟。在这种情况下,可以考虑优化数据库性能,如增加系统内存、升级硬件、优化SQL查询等。
服务器/网络问题:如果服务器负载过高、网络有问题或者服务器配置不合适,也可能导致查询延迟。
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。



