
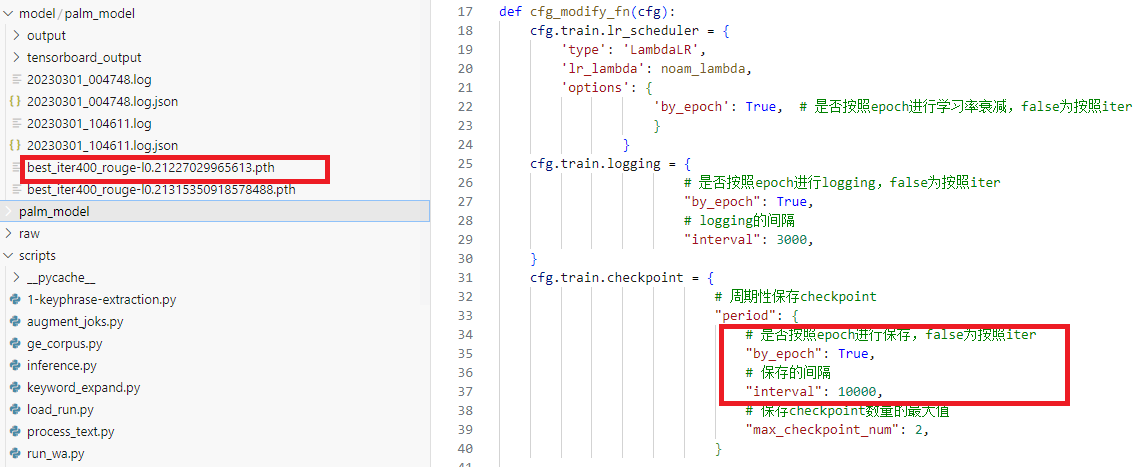
modelscope 训练时,cfg.train.checkpoint的保存中间结果设置不管用?
modelscope跑的模型, 请问这个saving checkpoint at 200 iterations,怎么把200改的大一点,在哪里设置,我按照你们给出的格式cfg.train.checkpoint,把"by_epoch": True, 但是结果还是按照iter进行保存的,interval不管怎么设置,跑的结果还是200个interval就保存一次,这怎么弄。求答复,谢谢。

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
天下风云出我辈,一入江湖岁月催,皇图霸业谈笑中,不胜人生一场醉。
参考一下网上的代码,感觉不只是这一块设置起作用,是不是还要改一下其他的参数 # Set up a RunConfig to only save checkpoints once per training cycle. run_config = tf.estimator.RunConfig(save_checkpoints_secs=1e9,keep_checkpoint_max = 10)
#改变keep_checkpoint_max的值就可以改变保存到本地的checkpoint的数量
model = tf.estimator.Estimator( model_fn=deeplab_model_focal_class_imbalance_loss_adaptive.deeplabv3_plus_model_fn, model_dir=FLAGS.model_dir, config=run_config, params={ 'output_stride': FLAGS.output_stride, 'batch_size': FLAGS.batch_size, 'base_architecture': FLAGS.base_architecture, 'pre_trained_model': FLAGS.pre_trained_model, 'batch_norm_decay': _BATCH_NORM_DECAY, 'num_classes': _NUM_CLASSES, 'tensorboard_images_max_outputs': FLAGS.tensorboard_images_max_outputs, 'weight_decay': FLAGS.weight_decay, 'learning_rate_policy': FLAGS.learning_rate_policy, 'num_train': _NUM_IMAGES['train'], 'initial_learning_rate': FLAGS.initial_learning_rate, 'max_iter': FLAGS.max_iter, 'end_learning_rate': FLAGS.end_learning_rate, 'power': _POWER, 'momentum': _MOMENTUM, 'freeze_batch_norm': FLAGS.freeze_batch_norm, 'initial_global_step': FLAGS.initial_global_step })
2023-03-01 11:27:21赞同 展开评论

