
flinkcdc读取时怎么限制读取速度?
flinkcdc读取时怎么限制读取速度?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
要限制Flink CDC的读取速度,可以尝试以下方法:
1、调整Flink的并行度(parallelism):通过调整Flink任务的并行度,可以控制Flink CDC的吞吐量。较小的并行度将减少同时处理数据的并发任务数,从而降低吞吐量。请注意,调整并行度可能会影响Flink任务的性能和资源利用率,因此需要根据实际情况进行调整。
2、调整Flink CDC的吞吐量配置:Flink CDC提供了吞吐量相关的配置选项,可以根据需要调整。例如,可以尝试降低slot-num的值来减少并发任务数,从而降低吞吐量。
3、使用流量控制:可以在Flink CDC的源组件中启用流量控制(flow control),以限制数据读取的速度。流量控制可以通过控制数据生产速率(produce rate)来实现,例如使用rateLimiter函数来限制单位时间内处理的数据量。
2023-08-26 20:35:50赞同 展开评论 -
在Flink CDC中,可以通过设置两个参数来限制读取速度:
cdc.maxParallelism和cdc.maxEventsPerSecond。.maxParallelism参数表示CDC任务的最大并行度。通过设置较小的并行度,可以限制每个任务的读取速度。请注意,小的并行度可能会降低读取速度。
cdc.maxEventsPerSecond参数表示每秒钟从数据库中读取的最大事件数。通过设置较小的值,可以限制读取速度。请注意,较小的值可能会导致数据丢失。
这些参数可以通过在Flink作业中的CDC表环境中设置来限制读取速度。例如:
tEnv.getConfig().getConfiguration().setLong("cdc.maxEventsPerSecond", 1000); tEnv.getConfig().getConfiguration().setInteger("cdc.maxParallelism", 2);这将限制CDC任务每秒钟最多读取1000个事件,并将并行度设置为2。
请根据实际需求进行调整,并注意平衡读取速度和数据一致性的关系
2023-08-21 11:43:48赞同 展开评论 -
你在使用 Flink CDC 读取数据时想要限制读取速度。为了实现这个目标,你可以尝试使用 Flink CDC 的 fetchTimeout 参数来控制 Flink CDC 在读取数据时的宽松程度,这样可以让 Flink CDC 在读取数据时更加宽松。
2023-08-17 15:45:29赞同 展开评论 -
在 Flink CDC 中,可以通过以下方法来限制读取速度:

并行度设置:通过调整作业的并行度(parallelism),可以控制 Flink CDC 作业的整体读取速度。较高的并行度可能会导致更快的读取速度,而较低的并行度则可能减慢读取速度。根据实际需求,适当调整并行度以达到期望的读取速度。
消费者速率限制:某些数据源(如 Apache Kafka)支持在消费者端进行速率限制。您可以配置 Flink CDC 的消费者参数,例如
flink.cdc.consumer.max-events-per-task或flink.cdc.consumer.max-events-per-second,以限制每个任务或每秒处理的最大事件数,从而控制读取速度。窗口和水位线:通过使用窗口操作和水位线机制,可以控制 Flink CDC 作业对输入数据的处理速度。例如,使用滚动窗口来控制每个窗口内的事件数量,或使用水位线来控制事件的处理进度。
Throttle 操作符:Flink 提供了
Throttle操作符,用于限制数据流的速率。您可以将Throttle操作符插入到 Flink CDC 作业的数据流中,在其中指定所需的最大速率,以控制数据的发射速度。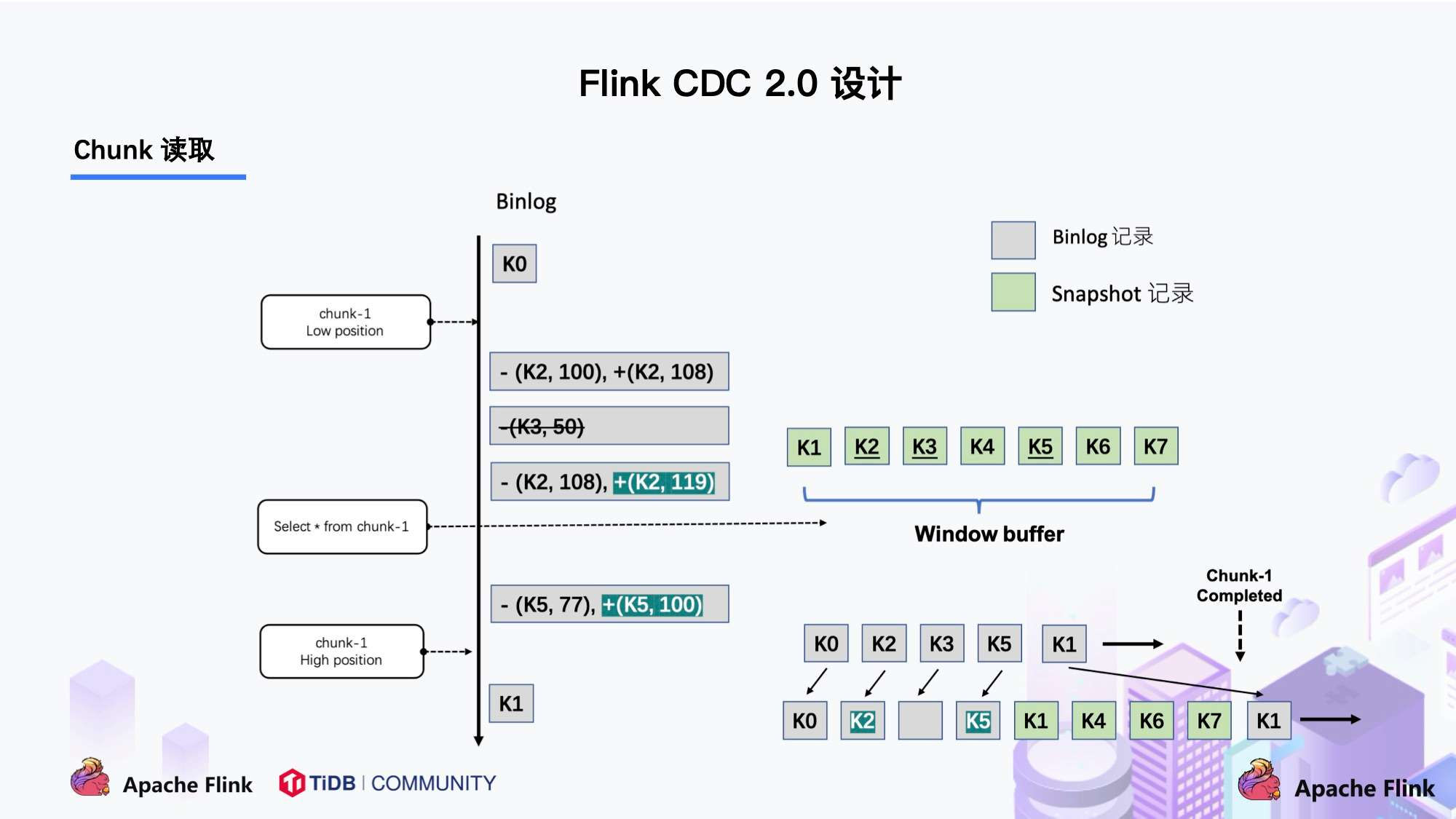
配置读取速率参数:在 Flink CDC 的配置中,可能会包含一些与读取速率相关的参数。例如,可以调整
flink.cdc.reader.fetch-size参数来控制每次读取的数据量,或者调整flink.cdc.reader.poll-interval参数来控制 Flink CDC 作业轮询数据源的频率。
 2023-08-16 22:55:15赞同 展开评论
2023-08-16 22:55:15赞同 展开评论 -
北京阿里云ACE会长
在 Flink CDC 中,你可以通过以下几种方式来限制读取速度:
并行度设置:通过调整 Flink CDC 的并行度来限制读取速度。并行度定义了同时处理数据的任务数量,较低的并行度可以减缓数据的读取速度。你可以在 Flink CDC 应用程序配置中设置并行任务的数量,或者在提交应用程序时通过命令行参数进行设置。
读取频率控制:Flink CDC 支持设置读取的频率,即每秒读取的最大记录数。你可以在 Flink CDC 应用程序中使用 setMaxReadRate() 方法来设置最大读取速率。通过限制每秒读取的记录数,可以控制读取速度,避免过快读取导致的资源压力。
数据源参数配置:某些数据源(如数据库)提供了参数配置来限制读取速度。你可以查阅数据源的文档,了解相关配置选项。例如,对于 Oracle 数据库,你可以考虑使用 FETCH FIRST 或 ROWNUM 等语句来限制每次读取的记录数。
窗口和水位线控制:在 Flink 中,你可以使用窗口和水位线机制来控制数据的处理速度。通过设置合适的窗口大小和水位线,可以控制数据的到达速度。Flink 提供了多种窗口类型和水位线生成策略,你可以根据实际需求选择合适的方式来限制读取速度。
请注意,以上方法可以在一定程度上限制读取速度,但也会对应用程序的性能产生影响。因此,需要根据实际需求和系统资源进行权衡和调整。
2023-08-14 19:10:21赞同 展开评论 -
Flink CDC 可以使用速率限制(rate limiting)机制来控制读取速度。速率限制可以通过配置 Flink 的并行度(parallelism)或使用流量控制(traffic control)来实现。
以下是一些可能的速率限制方法:
- 调整 Flink 并行度:通过调整 Flink 的并行度,可以增加或减少任务的处理能力。可以将并行度设置得更高以增加处理速度,但需要注意不要超过系统的资源限制。
- 使用流量控制:可以使用流量控制来限制 Flink CDC 的读取速度。
可以在 Flink 的配置文件(flink-conf.yaml)中添加以下参数:

taskmanager.network.netty.rateLimitingEnabled: true taskmanager.network.netty.rateLimit: 10000000 # 限制每秒的字节数这将启用流量控制,并将每秒的字节数限制为 10000000。可以根据需要调整限制值。
- 使用背压(Backpressure):背压是一种反馈机制,当数据处理速度超过输入速度时,通过增加延迟或者阻塞数据流来降低处理速度。可以在 Flink 的 Source 函数中实现背压机制,例如使用
BoundedOutOfOrdernessWatermarks来产生背压信号。
2023-08-14 15:37:35赞同 展开评论 - 调整 Flink 并行度:通过调整 Flink 的并行度,可以增加或减少任务的处理能力。可以将并行度设置得更高以增加处理速度,但需要注意不要超过系统的资源限制。
-
全栈JAVA领域创作者
如果您需要限制Flink CDC读取数据的速度,可以使用Flink提供的Checkpoint机制,定期对Flink CDC的状态进行检查点,以便在出现问题时可以快速恢复。在Flink中,您可以使用Checkpoint机制,将Flink CDC的状态保存到文件中,以便在重启Flink时可以恢复到最近的检查点状态。
同时,您还可以使用Flink提供的Watermark机制,定期向目标数据库写入数据。在Flink中,您可以使用Watermark机制,将当前时间作为水印,向目标数据库写入数据。如果您希望限制Flink CDC读取数据的速度,可以使用Watermark机制,定期向目标数据库写入数据,以便控制Flink CDC读取数据的速度。
需要注意的是,不同的情况可能需要不同的解决方案,因此需要根据具体情况进行调整和优化。同时,您可以使用Flink CDC提供的TableFunction接口,自定义一个TableFunction实现类,对读取到的数据进行特殊过滤,以避免出现表字段变少的情况。2023-08-14 13:10:39赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
