
flinkcdc消耗io很严重吗?
flinkcdc消耗io很严重吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
Flink CDC 消耗的 IO 资源主要取决于以下几个因素:
1、数据源:不同的数据源产生的 IO 消耗不同。例如,从 MySQL、PostgreSQL 等关系型数据库中读取数据时,会产生大量的 IO 消耗,因为需要读取全量数据和增量变更数据。
2、数据量:处理的数据量越大,产生的 IO 消耗就越大。
3、并行度:Flink 的并行度越高,每个 Task 处理的 数据越少,IO 消耗也会相应降低。
总体来说,Flink CDC 的 IO 消耗是相对较高的,因为它需要实时捕获数据库的变化,并将这些变化写入消息中间件供其他服务进行订阅和使用。因此,在使用 Flink CDC 时,需要根据实际情况调整并行度、优化查询语句等手段来降低 IO 消耗。
2023-08-26 21:35:22赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,阿里云flinkcdc消耗IO的情况与具体的使用场景相关。因为Flink CDC是基于Change Data Capture技术,会不断地从数据源(如MySQL)中读取变更数据,再将其写入到目标存储(如OSS、HBase)中,这个过程中会消耗一定的IO资源。同时,在数据变更频繁的情况下,CDC的IO消耗可能会更加严重。因此,在使用CDC时,需要结合具体的数据量、变更频率等因素进行评估和优化,以确保系统的稳定性和性能。建议可以使用性能测试工具对系统进行压力测试,评估其IO消耗情况。
2023-08-21 15:02:51赞同 展开评论 -
在Flink CDC中,由于需要进行数据捕获和传输,因此需要一定的IO操作。具体IO消耗的情况取决于多个因素,例如要捕获的数据量、数据来源的类型、网络带宽等等。但是一般情况下,CDC会产生一定的IO消耗。如果数据量较大或者网络带宽有限,则IO消耗可能会更加重。因此,在使用Flink CDC时需要合理配置资源和优化性能,以平衡IO消耗和数据处理能力。
2023-08-18 11:51:30赞同 展开评论 -
-
Flink CDC 在消耗 I/O 方面的情况取决于多个因素,如数据源的类型、数据量、并行度和网络延迟等。一般来说,Flink CDC 的 I/O 消耗是可控的,并且可以通过适当的配置和调优进行优化。
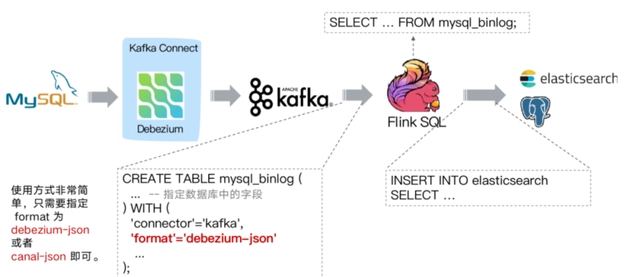
以下是一些影响 Flink CDC I/O 消耗的因素:
数据源类型:不同的数据源可能对 I/O 有不同的要求。例如,如果您使用 Flink CDC 从文件系统读取数据,则涉及磁盘 I/O;而如果您使用 Flink CDC 从消息队列或数据库读取数据,则涉及网络 I/O。具体的 I/O 消耗取决于数据源的性质和底层实现。
数据量和并行度:处理大规模数据时,较高的并行度可能会增加 I/O 负载。Flink CDC 可以根据作业的需求进行水平扩展,利用集群中的多个任务并行地处理数据。这可能会导致更多的 I/O 操作,尤其是在数据输入和输出方面。
网络延迟:如果数据源和 Flink CDC 之间存在较大的网络延迟,读取和写入数据的效率可能受到限制,从而影响 I/O 性能。这可能特别发生在跨网络传输数据的场景中,例如从远程数据库读取数据。
为了减少 Flink CDC 的 I/O 消耗,您可以考虑以下优化策略:
合理配置并行度:根据作业的需求和集群资源,调整 Flink CDC 作业的并行度。过高的并行度可能会导致过多的 I/O 操作,而过低的并行度可能无法充分利用集群资源。
使用适当的数据压缩:在进行数据传输时,可以考虑使用压缩算法来减少数据量,从而减少网络传输和磁盘写入的开销。
考虑数据缓存:如果数据源支持,可以使用合适的缓存机制来减少频繁的 I/O 操作。例如,可以将部分数据缓存在内存中,以减少对底层存储系统的访问次数。
定期监控和调优:通过定期监控 Flink CDC 作业的指标和性能数据,可以及时发现和解决潜在的性能问题。根据具体情况,调整相关参数和配置,以达到最佳的性能和效率。
2023-08-16 22:49:47赞同 展开评论 -
北京阿里云ACE会长
Flink CDC 的性能和资源消耗与多个因素有关,包括以下几个方面:
数据源的吞吐量:Flink CDC 从数据源(如数据库)中读取数据,并将其转换成流式数据进行处理。如果数据源的吞吐量(包括写入和更新操作)很高,那么 Flink CDC 需要处理大量的数据变化,可能会对系统的 IO 资源产生较高的消耗。
Flink CDC 的并行度和任务配置:Flink CDC 可以以并行的方式运行,可以配置多个任务来处理不同的数据分区或数据流。并行度的增加会增加资源消耗,包括 CPU、内存和网络等方面。你可以根据系统的资源情况和性能需求来调整 Flink CDC 的并行度和任务配置。
Checkpoint 和状态管理:Flink CDC 支持检查点(checkpoint)机制来保证数据的一致性和容错性。检查点需要将数据写入到持久化存储中,这可能会产生额外的 IO 消耗。同时,Flink CDC 还需要管理和维护状态信息,包括保存数据变化的位置和元数据等,这也会消耗一定的资源。
配置和优化:Flink CDC 提供了多个配置选项和优化策略,可以根据具体的场景和需求进行调整。例如,可以通过调整批处理大小、网络缓冲区大小、并行任务的数量等来优化性能和资源消耗。
总的来说,Flink CDC 在处理大规模数据变化时可能会对系统的 IO 资源产生一定的消耗。但具体的影响取决于数据源的吞吐量、任务配置、检查点和状态管理等因素。通过合理的配置和优化,可以最大程度地利用系统资源,提高性能和吞吐量,并减少资源消耗。
2023-08-14 19:10:20赞同 展开评论 -
Flink CDC 确实会消耗一定的 IO 资源,但具体消耗情况取决于多种因素,包括数据库类型、表结构、数据量、并发度等。在处理大量数据的情况下,Flink CDC 的 IO 消耗可能会比较显著。
然而,Flink CDC 的设计目的是为了实时监测和捕获数据库的变动,并将变动数据以增量的方式传输给其他服务。因此,如果数据量较大,那么 IO 消耗也会相应增加。
为了降低 IO 消耗,可以考虑以下方法:
- 优化数据库表结构:使用更合适的索引和存储引擎,可以减少 IO 消耗。
- 调整 Flink 并行度:根据系统的资源限制,可以调整 Flink 的并行度以适应数据量。
- 使用更快的硬件:升级硬件,例如更快的 CPU、更多的内存或者更快的存储设备,也可以提高 IO 性能。
- 优化 Flink CDC 配置:可以调整 Flink CDC 的配置参数,例如 fetch size、chunk size 等,以降低 IO 消耗。
2023-08-14 15:38:38赞同 展开评论 -
全栈JAVA领域创作者
是的,Flink CDC在读取和写入数据时,可能会消耗大量的I/O资源。具体来说,Flink CDC需要从源数据库中读取数据,并将数据写入目标数据库中。这些读写操作都需要进行大量的I/O操作,因此可能会消耗大量的I/O资源。
同时,Flink CDC还需要对读取到的数据进行解析和处理,以便将其转换为目标数据库中的数据格式。这些解析和处理操作也需要进行大量的I/O操作,因此可能会消耗大量的I/O资源。
需要注意的是,不同的情况可能需要不同的解决方案,因此需要根据具体情况进行调整和优化。同时,您可以使用Flink CDC提供的TableFunction接口,自定义一个TableFunction实现类,对读取到的数据进行特殊过滤,以避免出现表字段变少的情况。2023-08-14 13:09:17赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
