
请问下,我的业务场景是有个字段是身份证号,我需要用正则表达式控制这个字段的质量,dataworks的
请问下,我的业务场景是有个字段是身份证号,我需要用正则表达式控制这个字段的质量,dataworks的功能支持吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
dataworks的功能支持对身份证号的操作,使用函数 regexp_replace regexp_replace(expr, pat, repl[, pos[, occurrence[, match_type]]]) 或者创建规则 https://help.aliyun.com/document_detail/423775.html?spm=a2c4g.11186623.0.0.5af15033v6MOCz
2022-11-29 07:55:08赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主可以直接去阿里云官方文档中的DataWorks相关的内容查看,直接通过DataWorks设置数据质量规则,然后根据实际业务需求来完成数据的规则校验。
2022-11-26 08:12:42赞同 展开评论 -
十年摸盘键,代码未曾试。 今日码示君,谁有上云事。
阿里云DataWorks结合各引擎为企业提供一站式开箱即用的安全能力,这些能力可以覆盖《数据安全能力成熟度模型 GB/T37988—2019》(DSMM)中所述的几个重要的数据安全过程:传输、存储、处理、交换、通用等。
DataWorks天然具备的生产开发隔离、RABC角色权限体系、可视化数据权限管理能力结合引擎的安全特性如精细化授权、数据加密存储、数据备份等,即可解决此前提到的“事前安全”、“边界安全”,让企业快速解决安全治理的第一步。
DataWorks数据保护伞提供自动化、智能化敏感数据发现常见场景下的敏感数据保护。
DataWorks数据保护伞内置了50种个人敏感信息的识别模型,如手机号,身份证号,银行卡号等。其次,有自定义的识别功能,用户可以定义正则表达式或训练一些识别模型。另外还可以自己去定义元数据识别,即有一些敏感数据类型,内容特征不是很明显,比如工资信息,只包含一些数字,针对这样的数据,建表时可以用一些比较特殊的命名规范,也可以去指定某个项目的某个表的某一列就是这种类型的敏感数据。
然后根据定义好的这些规则新建一张表,可能并没有匹配到定义好的数据规则,但是它的原表命中了其中某一种敏感数据类型,这种情况下是可以扩散到新建的表中去的。 最后在这些核心优势的基础上再去做分级、脱敏、水印等,还可以将这些统计的结果展示在DataWorks数据保护伞的页面上,让用户清晰地看到这些图表。
在数据查询、迁移、下载的各个场景里,用户都可以在DataWorks数据保护伞页面上进行灵活的配置。
DataWorks数据保护伞提供遮盖,Hash和假名这三种脱敏方式。遮盖脱敏主要用在BI场景下,BI同学需要分析一下数据,比如分析出来是手机号,中间四位可以用四个星号代替。
DataWorks数据保护伞可以提供行为检测,用户也可以去自定义风险规则,并且可以内置一些专家模型,根据用户操作的特征、环境、历史、账号等维度来判断哪些是正常操作,哪些是可能会有问题的操作。
不管哪一种方式,每一个查询出来的数据,DataWorks数据保护伞都会去嵌入数据水印,并且生成一个操作数据库。当有数据被泄露了,用户拿着被泄露的数据,回到DataWorks数据保护伞的页面上,可以去查询操作数据库,DataWorks数据保护伞可以帮用户回溯出来这个数据可能是谁在什么时间写了什么SQL泄露的。
2022-11-25 14:32:05赞同 展开评论 -
从事java行业9年至今,热爱技术,热爱以博文记录日常工作,csdn博主,座右铭是:让技术不再枯燥,让每一位技术人爱上技术
根据你的问题描述,你应该是想对存储身份证的字段进行数据治理,在官方文档中 DataWorks可以通过配置【配置数据质量规则】来对数据进行治理,具体的操作是先创建分区,创建规则,关联调度节点,DQC规则会在产出任务完成后被触发,对匹配到的分区内的数据进行规则校验,校验完成之后还可以通过订阅钉钉机器人进行实时通知,比如说你这里所说的控制身份证字段的质量可以理解为控制身份证的位数,配置规则筛选满足身份证位数的合法身份证数据等,具体操作可以参考官方文档支持:https://help.aliyun.com/document_detail/461451.html
2022-11-23 18:39:26赞同 展开评论 -
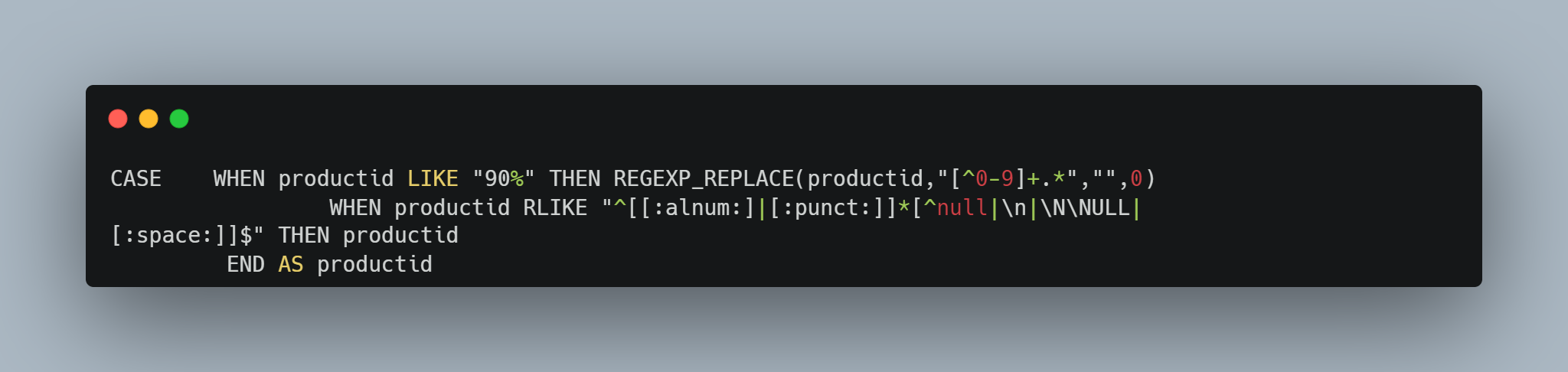
dataworks里面有个REGEXP_REPLACE函数,以及rlike,平常到清洗这一步,我会先使用前者将数据中比较明确的脏数据给清洗成需要的数据,然后再使用rlike对数据进一步过滤保障数据质量 这个是我对商品id的一次处理,首先是将带90字样的数据只保留有符号出现的前面部分,然后是将不包含英文数字以及各种字符串的“null”变为null
 2022-11-23 08:40:40赞同 展开评论
2022-11-23 08:40:40赞同 展开评论 -


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
