
flink cdc 2.0 是分片机制,全量同步,怎么保障顺序同步?状态需要顺序的
flink cdc 2.0 是分片机制,全量同步,怎么保障顺序同步?状态需要顺序的
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
公众号:网络技术联盟站,InfoQ签约作者,阿里云社区签约作者,华为云 云享专家,BOSS直聘 创作王者,腾讯课堂创作领航员,博客+论坛:https://www.wljslmz.cn,工程师导航:https://www.wljslmz.com
首先要明白为啥flink cdc 2.0需要分片,分片意味着肯定存在大数据量,在1.x版本下,如果表的数据非常的大,到底亿级的,那么数据读取就会耗时非常长,如果因为某些原因失败了,就需要从头开始读取,这样大大浪费时间,从而影响性能,而且重新读取也不一定能够一次性成功,所以分片机制就显得非常重要了。
如果我们将数据分片的话,那么就会将大的数据细分为小数据,可以做到提升效率的作用,一旦某个分片出现错误了,还能在下次读取的时候续上,也就是我们所说的断点续传。
在Flink CDC 2.0中,其增量快照算法在全量同步的情况下也能实现并行读取,且在分片的同时也会打上相关的分片TAG,保证了顺序性。
2022-11-30 22:48:57赞同 展开评论 -
网站:http://ixiancheng.cn/ 微信订阅号:小马哥学JAVA
Flink CDC数据入湖架构,分为两路,有一个全量作业做一次性的全量拉取,还有一个增量作业通过Canal和处理引擎Binlog数据实时地同步到Hudi表中。无需周期性地调度全量合并任务,能做到分钟级延迟。但是全量和增量仍是割裂的两个作业,全量和增量的切换仍需要仍需要人工的介入,并且需要指定一个准确的增量启动位点。本身Flink自身支持Exactly Once的读取计算。 基于日志的CDC,实时消费日志,流处理。例如MySql的binlog日志完整记录了数据库中的变更,可以binlog文件当作流的数据源。 保障数据一致性,因为binlog文件包括了所有的历史变更明细。 保障实时性,因为类似binlog的日志是可以流式消费的,提供的是实时数据。
2022-11-24 19:37:55赞同 展开评论 -
十年摸盘键,代码未曾试。 今日码示君,谁有上云事。
CDC 选择了 Debezium 作为 Flink CDC 的底层采集工具。Debezium 支持全量同步,也支持增量同步,也支持全量 + 增量的同步,非常灵活,同时基于日志的 CDC 技术使得提供 Exactly-Once 成为可能。
MySQL 数据库的一张表所有的变更都记录在 binlog 日志中,如果一直对表进行更新,binlog 日志流也一直会追加,数据库中的表就相当于 binlog 日志流在某个时刻点物化的结果;日志流就是将表的变更数据持续捕获的结果。这说明 Flink SQL 的 Dynamic Table 是可以非常自然地表示一张不断变化的 MySQL 数据库表。
基于日志的方式,可以很好的做到增量同步; 而基于查询的方式是很难做到增量同步的。
2022-11-24 14:59:15赞同 1 展开评论 -
Flink CDC 2.0 在 MySQL CDC 上实现了增量快照读取算法,在最新的 2.2 版本里 Flink CDC 社区 将增量快照算法抽象成框架,使得其他数据源也能复用增量快照算法。
增量快照算法解决了全增量一体化同步里的一些痛点。比如 Debezium 早期版本在实现全增量一体化同步时会使用锁,并且且是单并发模型,失败重做机制,无法在全量阶段实现断点续传。增量快照算法使用了无锁算法,对业务库非常友好;支持了并发读取,解决了海量数据的处理问题;支持了断点续传,避免失败重做,能够极大地提高数据同步的效率与用户体验。
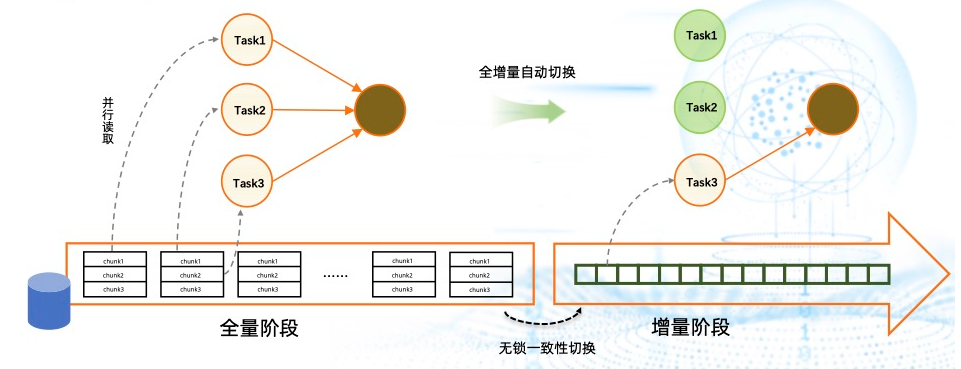 上图为全增量一体化的框架。整个框架简单来讲就是将数据库里的表按 PK 或 UK 切分成 一个个 chunk ,然后分给多个 task 做并行读取,即在全量阶段实现了并行读取。全量和增量能够自动切换,切换时通过无锁算法来做无锁一致性的切换。切换到增量阶段后,只需要单独的 task 去负责增量部分的数据解析,以此实现了全增量一体化读取。进入增量阶段后,作业不再需要的资源,用户可以修改作业并发将其释放。2022-11-24 00:43:28赞同 展开评论
上图为全增量一体化的框架。整个框架简单来讲就是将数据库里的表按 PK 或 UK 切分成 一个个 chunk ,然后分给多个 task 做并行读取,即在全量阶段实现了并行读取。全量和增量能够自动切换,切换时通过无锁算法来做无锁一致性的切换。切换到增量阶段后,只需要单独的 task 去负责增量部分的数据解析,以此实现了全增量一体化读取。进入增量阶段后,作业不再需要的资源,用户可以修改作业并发将其释放。2022-11-24 00:43:28赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
