
使用flinkSQL将数据写入hudi,而hudi的数据存储在s3上,提交程序运行报错是怎么回事? 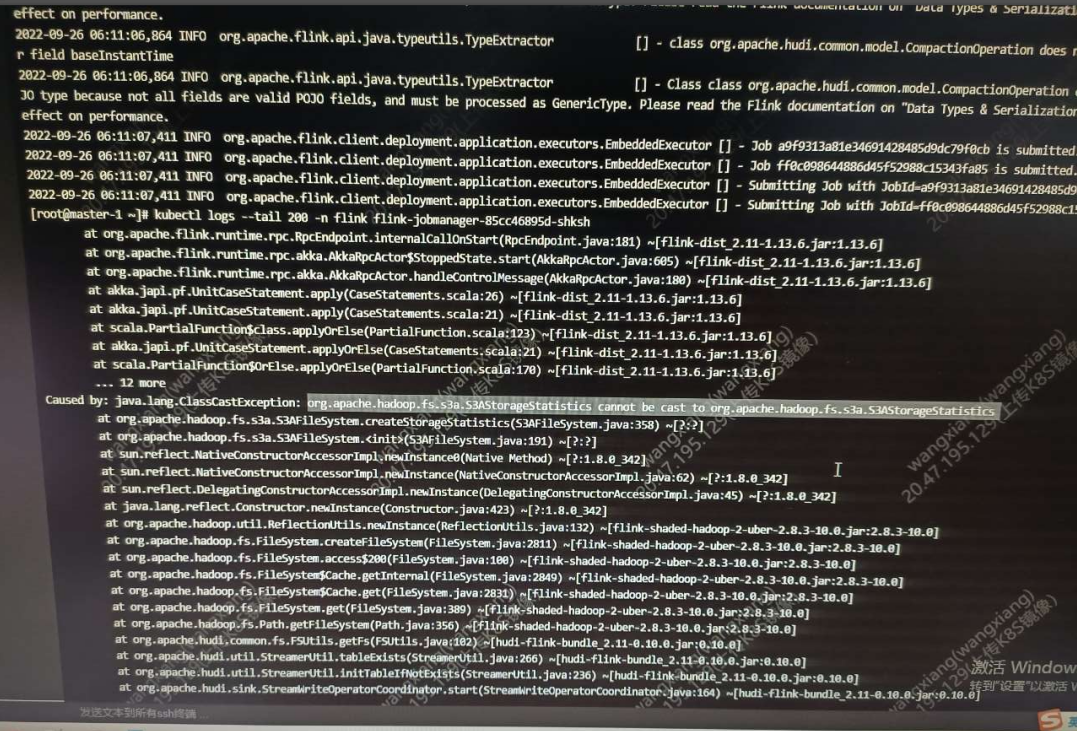
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云Flink SQL将数据写入Hudi并存储在S3上时,提交程序运行报错可能有多种原因。以下是一些常见的原因:
出现这种情况可能是因为您的 FlinkSQL 程序连接的 S3 上的 Hudi 数据湖没有正确配置或连接异常,导致无法进行数据写入。
针对这种问题,您可以参考以下几个方面进行排查:
1.检查 S3 上 Hudi 数据湖的连接参数,包括 S3 存储桶、访问 ID 和密钥等是否正确,可通过 AWS CLI 进行验证。
2.检查 FlinkSQL 程序的配置参数是否正确,在写入 Hudi 数据湖的过程中,需要通过配置参数指定 S3 存储位置、用户名和密码等信息,确保能够正确连接和访问 S3 上的 Hudi 数据湖。
3.检查网络连接和权限,确保您的 FlinkSQL 程序能够正常连接和访问 S3 上的 Hudi 数据湖,并且具有相应的权限进行数据写入。
4.查看日志,详细查看程序报错信息,并根据具体错误进行排查和修改。
可能是以下几个原因导致的:
配置问题:检查您的flinkSQL和hudi的配置是否正确,并且确保您已经正确地配置了S3的访问密钥和密钥ID。
版本问题:确认您使用的Flink SQL和Hudi版本是否兼容。不同版本之间的语法和API可能有所不同,可能会导致运行时错误。
访问控制:检查是否正确设置了S3桶的访问控制,是否有足够的权限访问S3桶中的数据。
网络问题:如果您的程序位于本地,请确认您的网络是否正确,并且确保您可以访问S3服务。
代码问题:如果以上所有问题都排除了,请检查您的代码是否有逻辑错误,并且确保您使用的库是正确的版本。
在使用 Flink SQL 将数据写入 Hudi 时,如果 Hudi 的数据存储在 S3 上,可能会出现以下几种报错情况:
S3 访问权限不足:如果没有正确配置 S3 的访问权限,可能会导致程序无法正常访问 S3 上的数据。可以通过检查 S3 访问密钥和访问权限等配置来解决这个问题。
S3 存储桶名称错误:如果指定的 S3 存储桶名称错误,可能会导致程序无法正常访问 S3 上的数据。可以通过检查存储桶名称和区域等配置来解决这个问题。
Hudi 配置错误:如果 Hudi 的配置错误,可能会导致程序无法正常访问 S3 上的数据。可以检查 Hudi 的配置文件,确保配置正确。
网络连接问题:如果网络连接不稳定或者带宽不足,可能会导致程序无法正常访问 S3 上的数据。可以检查网络连接和带宽等问题,确保网络稳定。
针对这些问题,可以通过以下方法来解决:
检查 S3 访问密钥和访问权限等配置,确保访问权限足够。
检查存储桶名称和区域等配置,确保配置正确。
检查 Hudi 的配置文件,确保配置正确。
检查网络连接和带宽等问题,确保网络稳定。
如果以上方法都无法解决问题,可以查看程序报错信息,确定具体的错误原因,进一步调试和解决问题。
使用 Flink SQL 将数据写入 Hudi 并存储在 S3 上,需要配置一些相关参数。
首先,需要使用 Hudi 提供的 S3 存储插件 hoodie.s3a.consistency.enabled,来保证 S3 存储的一致性。其次,需要设置 AWS 的访问密钥和权限等认证信息,以便 Flink SQL 能够成功连接到 S3 并进行数据写入。
具体配置方式可以参考 Hudi 官方文档[1]中的示例。在 Flink SQL 程序中,可以使用类似以下的语句来将数据写入到 Hudi:
sql
INSERT INTO hudi_sink_table (id, name, age, ts) FORMAT 'org.apache.hudi.flink.format.HoodieParquetWriteFormat' OPTIONS ( 'path'='$S3_BASE_PATH/hoodie_test', 'hoodie.table.name'='hoodie_test', 'hoodie.datasource.write.recordkey.field'='id', 'hoodie.datasource.write.partitionpath.field'='ts', 'hoodie.datasource.write.table.name'='hoodie_test', 'hoodie.datasource.write.keygenerator.class'='org.apache.hudi.keygen.NonpartitionedKeyGenerator', 'hoodie.datasource.write.payload.class'='org.apache.hudi.example.data.SimpleAvroPayload', 'hoodie.insert.shuffle.parallelism'='2', 'hoodie.upsert.shuffle.parallelism'='2', 'hoodie.delete.shuffle.parallelism'='2', 'hoodie.cleaner.commits.retained'='2', 'hoodie.cleaner.policy'='KEEP_LATEST_FILE_VERSIONS', 'hoodie.bulkinsert.shuffle.parallelism'='2', 'hoodie.s3a.consistency.enabled'='false', 'hoodie.datasource.write.keygen.class'='org.apache.hudi.keygen.NonpartitionedKeyGenerator', 'hoodie.datasource.write.partitionpath.field'='ts', 'path'='$S3_BASE_PATH/hoodie_test') SELECT id, name, age, CURRENT_TIMESTAMP() FROM source_table
其中,OPTIONS 中的参数设置需要根据实际的 S3 存储配置进行调整。需要注意的是,由于 S3 存储通常在网络和权限等方面存在一些限制和问题,因此在配置和使用上需要格外注意。
提交 FlinkSQL 程序到 Flink 集群时,需要在提交命令中指定运行时环境(如:YARN、Kubernetes 等)以及相关配置信息,包括 S3 存储的配置信息。可能是因为提交时缺少相关的 S3 配置信息,导致程序运行报错。
解决方法:
确认 S3 配置是否正确:可以检查程序中所使用的 S3 存储桶名称、密钥等配置信息是否正确,同时确认是否已经在程序中正确配置了 AWS SDK 等相关依赖库。
在提交 FlinkSQL 程序时,需要在命令中指定相关 S3 存储的配置信息。例如,使用以下命令提交程序到 YARN 集群:
flink run -m yarn-cluster -ynm <job-name> -yqu <queue-name> -yt <job-type> -c <main-class> <jar-file> -s3.accesskey <access-key> -s3.secretkey <secret-key> -s3.endpoint <endpoint> -s3.bucket <bucket-name>
其中,-s3.accesskey、-s3.secretkey、-s3.endpoint 和 -s3.bucket 分别表示 S3 存储的访问密钥、密钥、终端节点以及存储桶名称等配置信息。
根据您提供的截图,看起来是在使用 Flink 写入数据到 Hudi 时,遇到了 S3 存储相关的错误。
可能的原因是,程序缺少 S3 相关的配置或者权限。您可以检查以下配置和权限是否正确:
检查程序中是否正确配置了 S3 存储相关的配置项,例如 access key 和 secret key,region 等等。 确认程序运行的用户账号是否拥有 S3 存储的读写权限。 确认 S3 存储中是否存在对应的 Bucket,并且 Bucket 的访问权限设置正确。 如果以上都确认无误,可以尝试检查网络是否畅通,或者检查 S3 存储本身是否正常运行。如果问题依然存在,建议提供更多的上下文信息和日志,以便更好地排查问题。
这个问题可能有多种原因,以下是一些常见的排查步骤:
确认 Flink 和 Hudi 配置是否正确:检查 Flink 和 Hudi 的配置文件是否正确。例如,确认 Hudi 配置中指定了正确的 S3 存储桶地址和访问密钥等信息。
确认 S3 存储桶权限是否正确:检查 S3 存储桶是否设置了正确的权限和访问控制列表(ACL)。例如,确认 Flink 运行所使用的 IAM 用户或角色具有访问 S3 存储桶的权限。
检查网络连接是否正常:检查 Flink 运行环境和 S3 存储桶之间的网络连接是否正常。例如,可以尝试使用 AWS CLI 工具或其他 S3 客户端工具来验证连接是否正常。
确认 Hudi 依赖包是否正确添加:确认在 Flink SQL 任务中添加了正确的 Hudi 依赖包,并且 Hudi 版本与 Flink 版本兼容。
确认数据格式是否符合要求:确认输入数据格式是否符合 Hudi 要求。例如,确认输入数据中必须包含 _hoodie_commit_time 和 _hoodie_record_key 字段等信息。
如果以上排查步骤都没有解决问题,建议查看程序运行时的日志,以获取更详细的错误信息和调试信息。
S3 访问权限问题:您需要确保 Flink TaskManager 的执行环境中添加了 S3 访问密钥信息,并且该密钥对拥有写入 S3 的权限。您可以在 AWS 的控制台中进行密钥管理和授权,确保 Flink 可以正确访问 S3。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



