
问下 cdc2.2.1 读取mysql部署在flink yarn上 checkpoint 一直失败是咋回事,程序也没报错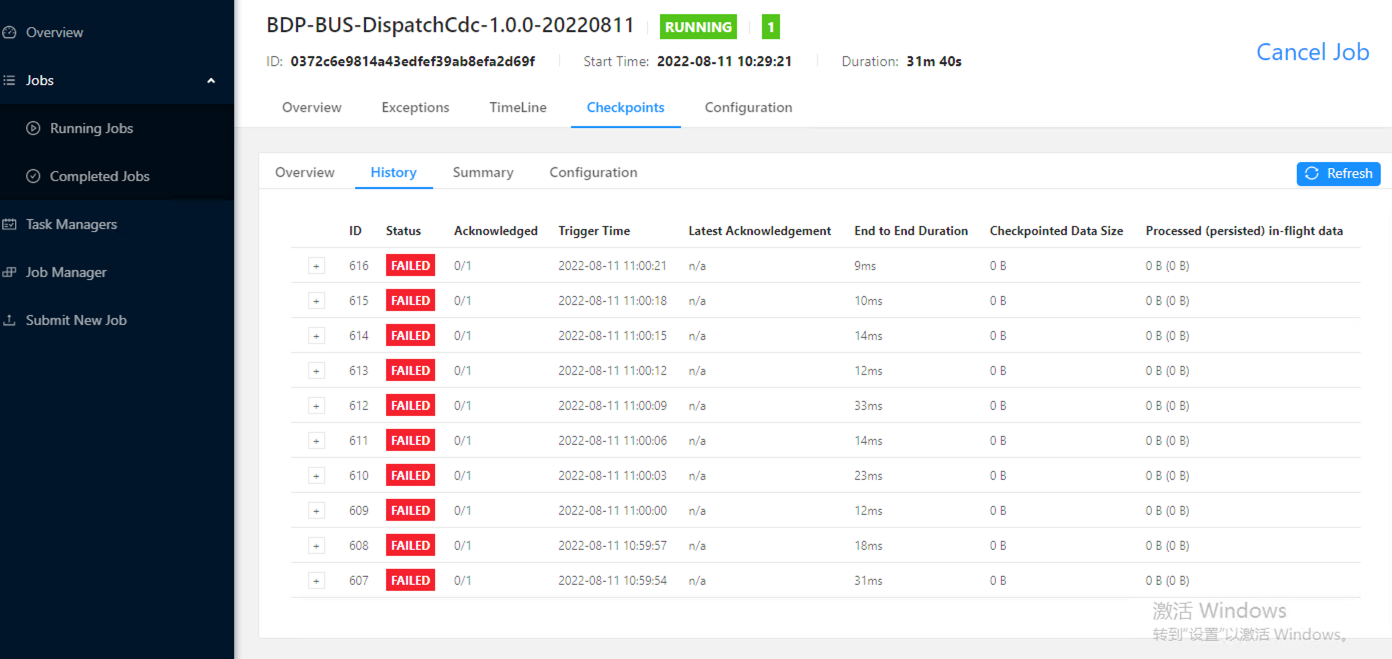
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
问题描述: 您在使用版本为2.2.1的CDC组件从MySQL读取数据,并部署在Flink YARN集群上时,遇到Checkpoint持续失败的情况,但程序并未直接报错。
可能原因及解决步骤:
配置检查: 确认Flink作业的Checkpoint配置是否正确设置,包括execution.checkpointing.interval(Checkpoint间隔时间)应符合业务需求且不过长,避免因等待Checkpoint导致的延迟问题。同时,确保YARN环境下的Flink配置支持Checkpoint存储和访问权限正确无误。
网络与权限: 验证Flink任务是否有足够的网络权限访问MySQL实例,特别是当MySQL与Flink部署在不同VPC或需通过公网访问时,需确保网络路径畅通且配置了正确的NAT规则或白名单。
MySQL Binlog配置: 检查MySQL服务器的Binlog配置,确认没有忽略掉您需要同步的数据库或表。使用show master status;命令查看Binlog_Do_DB和Binlog_Ignore_DB设置,确保目标库未被排除在外。
资源与并发: 分析作业运行时的资源分配情况,适当调整并行度(parallelism.default)以匹配任务需求。如果全量读阶段占用过多资源或时间,考虑增加Source端的并发数来加速处理,避免因最后一个分片过大导致Failover后卡住的问题。
日志分析: 详细检查Flink TaskManager的日志,寻找与Checkpoint相关的错误信息或警告,这可能是识别问题根源的关键。关注是否有与Checkpoint协调、存储或超时相关的错误提示。
Checkpoint策略与恢复机制: 确认Flink作业的重启策略是否得当,不当的重启策略可能导致Checkpoint行为异常。根据实际需求调整restart-strategy配置,如采用固定延迟重启策略并合理设定尝试次数与延迟时间。
注意事项:
进一步支持: 如果上述步骤未能解决问题,建议收集详细的日志信息并通过阿里云官方渠道寻求技术支持,提供更深入的故障排查和解决方案。
请按照上述步骤逐一排查,定位并解决Checkpoint失败的具体原因。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


